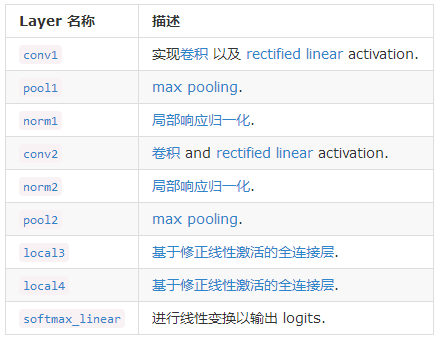
1. CIFAR-10
Cifar-10 is a data set collected by Alex Krizhevsky and Ilya Sutskever, two disciples of Hinton, for universal object recognition. Cifar is an advanced science project institute led by the Canadian government. Hinton, Bengio and his students received a small amount of money from Cifar in 2004 to build neurocomputing and adaptive perception projects. This project brings together many computer scientists, biologists, electrical engineers, neuroscientists, physicists and psychologists to accelerate the process of Deep Learning. From this lineup, DL The data mining of ML system is far away. Deep Learning emphasizes adaptive perception and artificiality Intelligence Data Mining emphasizes high speed. Big data Statistical mathematical analysis is the intersection of computer and mathematics.
Cifar-10 is composed of 60,000 32*32 RGB color images, totaling 10 categories. 50,000 exercises, 10,000 exercises test (Cross-validation). The greatest feature of this data set is that it migrates recognition to universal objects and applies it to multi-classification (sisterly data set Cifar-100 reaches 100 categories, ILSVRC competition is 1000 categories).

It can be seen that compared with mature face recognition, universal object recognition is a huge challenge. There are a lot of features and noises in the data, and the proportion of recognizing objects is different. Therefore, Cifar-10 is quite challenging compared with the traditional image recognition data set. For more information, please refer to CIFAR-10 page And Alex Krizhevsky's Technical Report.
2. Model
In previous blog posts, we have used TensorFlow to build a simple MNIST model for handwritten numeral recognition, mainly referring to Yann LeCun's paper published in 1998. Gradient-Based Learning Applied to Document Recognition The classical LeNet5 network proposed in this paper:
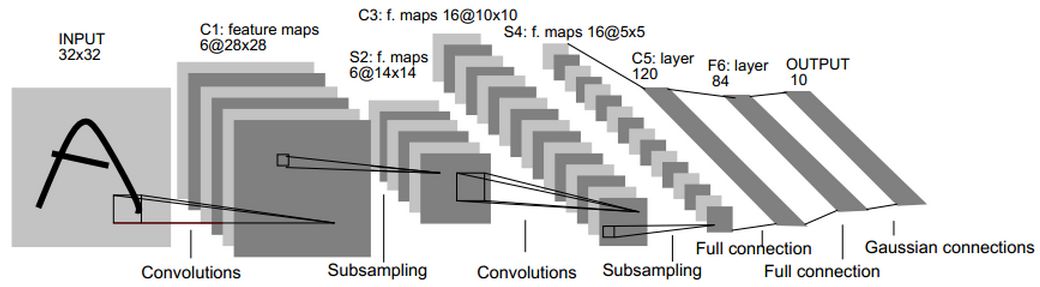
The network consists of convolution layer, pooling layer and full connection layer. The parameters are trained by gradient descent method. However, in the face of the complex problem of universal object classification, the network structure has been far from meeting the needs.
In this blog, we will analyze the improved techniques of AlexNet network for the classification of pervasive objects, which prevent model over-fitting and enhance the normalization ability.
- Data Augmentation is used for image flipping and random clipping.
- Local response normalization (LRN) is used behind the convolution-maximum pooling layer.
- Modified linear activation (ReLu), Dropout and overlapping Pooling were used.
As well as the implementation of TensorFlow code on CIFAR-10, we add pre-access queues for input data, visualization of network behavior, maintenance of sliding mean of parameters, setting learning rate decreases with iteration, and finally add L2 regular training to Losses to improve the training speed and recognition rate of the network.
The code results and network structure used in this article are as follows:
| file | Explain |
| cifar10_input.py | Read the contents of the local CIFAR-10 binary file format |
| cifar10.py | Establishment of CIFAR-10 Model |
| cifar10_train.py | Training CIFAR-10 Model on CPU or GPU |
| cifar10_multi_gpu_train.py | The CIFAR-10 model is trained on multiple GPU s. |
| cifar10_eval.py | Evaluating the predictive performance of CIFAR-10 model |
Multiple GPU versions of the model are provided in the reference code, but only CPU is used in this article.
3. Network Structure
The code of CIFAR-10 network model is located in cifar10.py. The complete training diagram contains about 765 operations. The following modules are used to construct training maps to maximize code reuse:
- Model input: including inputs(), distorted_inputs() and other operations, which are used to read CIFAR-10 images and preprocess them, respectively, as input for subsequent evaluation and training;
- Model prediction: some operations, such as inference(), are used for statistical calculation, such as classifying the images provided;
- Model training: Some operations including loss() and train() are used to calculate losses, calculate gradients, update variables and present final results.
3.1 Model Input
The input model is established by cifar10_input.inputs() and cifar10_input.distorted_inputs() functions, which read image files from CIFAR-10 binary files. The implementation is defined in cifar10_input.py and the data used is CIFAR-10 page The following 162M binary file can use the tf.FixedLengthRecordReader function because the number of bytes stored in each image is fixed.
After loading the image data, the data is augmented through the following processes:
- Uniform clipping to 24x24 pixel size, clipping the central area for evaluation or random clipping for training;
- Random left-right flip of the image;
- Random transform image brightness;
- Random transform image contrast;
- The picture will be whitened approximately.
Among them, whitening processing or standardization processing is to subtract the mean value of image data, divide by variance, ensure zero mean value of data, variance is 1, so as to reduce the redundancy of input image, remove the correlation between input features as far as possible, and make the network insensitive to the dynamic range change of image. A principle of mean file in Cafe.
View all available transformations in the list of Images pages, and add tf.summary.image for each original graph to facilitate viewing in Tensor Board:

Loading images from disk and transforming them takes a lot of processing time. To avoid these operations slowing down the training process, these operations are performed in parallel with 16 separate threads, which are sequentially arranged in a TensorFlow queue and returned to the pre-processed encapsulated tensor. Each execution generates a batch_size sample [images, labels]. The test data is generated by cifar10_input.inputs() function. The test data does not need to flip or modify the brightness and contrast of the picture. It needs to cut the 24*24 block in the middle of the picture and standardize the data.
The main functions are used as follows:
3.2 Model Prediction
The prediction process of the model is constructed by inference(), input is images and output is logits of the last layer.
Before building the model, we construct the weight constructor _variable_with_weight_decay(name, shape, stddev, wd), where WD is used to add L2 regularization to losses, which can prevent over-fitting and improve generalization ability:
In the second layer and the first layer, besides the change of input parameters, the biases values are all initialized to 0.1. The order of maximum pooling and LRN layer is changed. First, LRN is carried out, and then the maximum pooling layer is used.
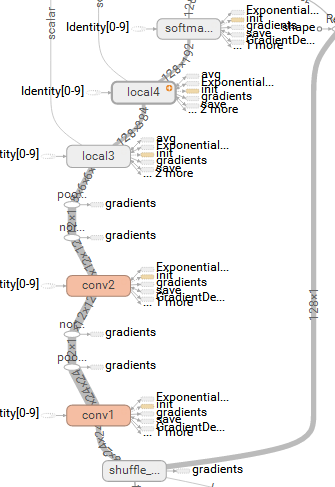
At this point, the inference of the entire network has been built, and the structure can be viewed with Tensor Board:
3.3 Loss Function
We recall the previous method of calculating loss using cross entropy:
Here y_conv is the logits value after tf.nn.softmax (the probability value belonging to each category), shape is [batch_size, num_classes], the sum of logit vector elements of each sample is 1; y_is the labels value after one hot encoding, shape is [batch_size, num_classes], only one label element in each sample is 1, the rest is 0. In later versions, TensorFlow provides a more convenient API that combines software Max and cross entropy. Calculations:
The shape of labels here is [batch_size, 1]. Then use tf.add_to_collection to add cross entropy's loss to the overall losses collection. Finally, tf.add_n is used to sum all the loss in the collection of the overall losses to get the final loss. It also returns, which contains cross entropy loss and L2 loss of weight in the last two full connection layers.
After defining loss, we need to define train() that accepts loss and returns train op.
Firstly, the learning rate is defined, and it decreases with the number of iterations, and summary:
Then, we define the training methods and objectives. tf.control_dependencies is a context manager, which controls the execution order of nodes. First, we execute the operations in [] and then the operations in context:
4. Training process
The above steps complete the definition of data input, model prediction, loss and training, and then call in turn to establish the training and summary process:
It's important to note that you must run start_queue_runners to start the previously mentioned thread for image data augmentation, which uses 16 threads for acceleration.
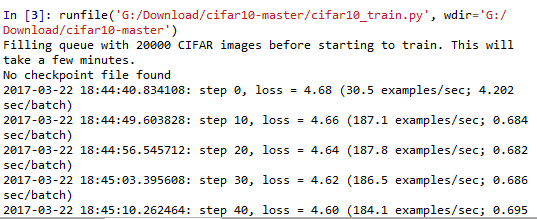
In the training process of each step, we need to use session run method to perform the calculation of images, labels, train_op and loss, record the time spent on each step, calculate and display the current loss every 10 steps, the number of training samples per second, and the time spent on training a batch data. It is more convenient to monitor the whole training process.
By executing scripts Python cifar10_train.py starts the training process. When any task is started on CIFAR-10 for the first time, the CIFAR-10 dataset will be downloaded automatically. The dataset is about 160M in size, and then output:
5. Model evaluation
cifar10_train.py periodically saves all the parameters in the model in the checkpoint file, but does not evaluate the model. cifar10_eval.py uses this checkpoint file on another part of the data set test Prediction performance. utilize The inference() function reconstructs the model and tests it with all 10,000 CIFAR-10 images in the evaluation data set. The final calculated accuracy is 1:N, N = the highest confidence item in the predicted value and the frequency matched with the real label of the picture. In order to monitor the improvement of the model in the training process, the script files used for evaluation will run periodically on the latest checkpoint files, which are generated by the cifar10_train.py mentioned above.
After running the cifar10_eval.py file, we can get output like this:
The script only returns the precision @ 1 periodically, and the accuracy rate returned in this case is 9.9% due to the few iterations. cifar10_eval.py also returns some other brief information that can be visualized in TensorBoard, which can be used to further understand the model during the evaluation process.
Our training script calculates the Moving Average for all learning variables, and the evaluation script directly replaces all learning model parameters with corresponding sliding average, which can improve the performance of the model in the evaluation process.