The tensorflow framework is used for object recognition training. In order to achieve the training goal faster, distributed training is adopted.
PS-worker architecture
Model maintenance and training calculation are decoupled and model training is divided into two job s:
- Model related jobs, model parameters storage, distribution, summary, update, executed by PS
- Training related tasks, including reasoning calculation, gradient calculation (forward/backward propagation), are performed by worker
Under this framework, all woker s share the parameters on PS, propagate different batch data according to the same data flow graph, calculate different gradients, and submit them to PS to aggregate and update the new model parameters. The general logic is as follows:
- pull: each woker gets the latest model parameters from PS according to the topological structure of data flow graph
- feed: Each worker fills its batch data according to defined rules
- compute: Each worker calculates its batch data using the model parameters in the first step and calculates the gradient of each batch.
- push: Each worker pushes its own gradient to PS
- update: PS aggregates N-component gradients from n worker s and updates model parameters after calculating average values.
Distributed classical architecture PS-worker repeats the above steps until the loss reaches the threshold or the number of rounds reaches the threshold.
Update classification according to parameters
1. The so-called synchronous updating refers to: each computer used for parallel computing, after calculating their batch, obtains the gradient value, unifies the gradient value to the ps service machine, obtains the gradient average value by the ps service machine, updates the parameters on the ps server. It can be seen that there are three computers. The first computer is used to store parameters, share parameters and share computing. It can be simply understood as memory, computing and sharing area, i.e. ps job. The other two computers are used for parallel computing, i.e. worker task.
The disadvantage of this calculation method is that every round of gradient updating has to wait until the three computers A, B and C have been computed before the parameters can be updated. That is to say, the speed of iteration updating depends on the slowest one among the three computers A, B and C. Therefore, the method of synchronous updating is adopted, and the computing power of three computers A, B and C is recommended. I don't want to.
2. The so-called asynchronous updates refer to: as long as the PS server receives the gradient value of one machine, it updates the parameters directly without waiting for other machines. This iteration method is unstable and the convergence curve shocks badly, because when machine A calculates and updates the parameters in ps, it is possible that machine B is still using the old parameter values of the last iteration.
Distributed Training Practice
First, we need to prepare three computers: one for ps (parameter provision), one master (master server processing parameters), and one worker (processing parameters). Configuration: 8G memory 100M bandwidth 2vcpu.
Code rewriting
Next, rewrite the code train.py
All preconditions such as model are ready:
Add the following in train.py: (ps machine code)
import functools
import json
import os
import tensorflow as tf
from object_detection.builders import dataset_builder
from object_detection.builders import graph_rewriter_builder
from object_detection.builders import model_builder
from object_detection.legacy import trainer
from object_detection.utils import config_util
tf.logging.set_verbosity(tf.logging.INFO)
flags = tf.app.flags
flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
flags.DEFINE_integer('task', 0, 'task id')
flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy per worker.')
flags.DEFINE_boolean('clone_on_cpu', False,
'Force clones to be deployed on CPU. Note that even if '
'set to False (allowing ops to run on gpu), some ops may '
'still be run on the CPU if they have no GPU kernel.')
flags.DEFINE_integer('worker_replicas', 1, 'Number of worker+trainer '
'replicas.')
flags.DEFINE_integer('ps_tasks', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.')
flags.DEFINE_string('train_dir', '',
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('type', '',
'Directory to save the checkpoints and training summaries.') //add to the content
flags.DEFINE_integer('index', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.') //add to the content
flags.DEFINE_string('pipeline_config_path', '',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')
flags.DEFINE_string('train_config_path', '',
'Path to a train_pb2.TrainConfig config file.')
flags.DEFINE_string('input_config_path', '',
'Path to an input_reader_pb2.InputReader config file.')
flags.DEFINE_string('model_config_path', '',
'Path to a model_pb2.DetectionModel config file.')
flags.DEFINE_string('cluster_data', '',
'Path to a model_pb2.DetectionModel config file.')
FLAGS = flags.FLAGS
@tf.contrib.framework.deprecated(None, 'Use object_detection/model_main.py.')
def main(_):
assert FLAGS.train_dir, '`train_dir` is missing.'
if FLAGS.task == 0: tf.gfile.MakeDirs(FLAGS.train_dir)
if FLAGS.pipeline_config_path:
configs = config_util.get_configs_from_pipeline_file(
FLAGS.pipeline_config_path)
if FLAGS.task == 0:
tf.gfile.Copy(FLAGS.pipeline_config_path,
os.path.join(FLAGS.train_dir, 'pipeline.config'),
overwrite=True)
else:
configs = config_util.get_configs_from_multiple_files(
model_config_path=FLAGS.model_config_path,
train_config_path=FLAGS.train_config_path,
train_input_config_path=FLAGS.input_config_path)
if FLAGS.task == 0:
for name, config in [('model.config', FLAGS.model_config_path),
('train.config', FLAGS.train_config_path),
('input.config', FLAGS.input_config_path)]:
tf.gfile.Copy(config, os.path.join(FLAGS.train_dir, name),
overwrite=True)
model_config = configs['model']
train_config = configs['train_config']
input_config = configs['train_input_config']
model_fn = functools.partial(
model_builder.build,
model_config=model_config,
is_training=True)
def get_next(config):
return dataset_builder.make_initializable_iterator(
dataset_builder.build(config)).get_next()
create_input_dict_fn = functools.partial(get_next, input_config)
env = json.loads(os.environ.get('TF_CONFIG', '{}'))
cluster_data = { //Change content
"worker":[
"192.168.1.109:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]
}
#cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
task_data = env.get('task', None) or {'type': 'master', 'index': 0}
task_info = type('TaskSpec', (object,), task_data)
# Parameters for a single worker.
ps_tasks = 0
worker_replicas = 1
worker_job_name = 'lonely_worker'
task = 0
is_chief = True
master = ''
task_info.type=FLAGS.type //add to the content
task_info.index = FLAGS.index //add to the content
if cluster_data and 'worker' in cluster_data:
# Number of total worker replicas include "worker"s and the "master".
worker_replicas = len(cluster_data['worker']) + 1
if cluster_data and 'ps' in cluster_data:
ps_tasks = len(cluster_data['ps'])
print('ps_tasks%d',ps_tasks)
if worker_replicas > 1 and ps_tasks < 1:
raise ValueError('At least 1 ps task is needed for distributed training.')
if worker_replicas >= 1 and ps_tasks > 0:
# Set up distributed training. // commented out
# server = tf.train.Server(tf.train.ClusterSpec(cluster), protocol='grpc',
# job_name=task_info.type,
# task_index=task_info.index)
#server = tf.train.Server(cluster, job_name="worker", task_index=0)
#print('Enter worker%d',worker_replicas)
if task_info.type == 'ps' or True: //As a ps machine
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index)
print('Get into ps')
server.join()
worker_job_name = '%s/task:%d' % (task_info.type, task_info.index)
task = task_info.index
is_chief = (task_info.type == 'master')
master = server.target
graph_rewriter_fn = None
if 'graph_rewriter_config' in configs:
graph_rewriter_fn = graph_rewriter_builder.build(
configs['graph_rewriter_config'], is_training=True)
trainer.train(
create_input_dict_fn,
model_fn,
train_config,
master,
task,
FLAGS.num_clones,
worker_replicas,
FLAGS.clone_on_cpu,
ps_tasks,
worker_job_name,
is_chief,
FLAGS.train_dir,
graph_hook_fn=graph_rewriter_fn)
if __name__ == '__main__':
tf.app.run()
worker and master Codes
import functools
import json
import os
import tensorflow as tf
from object_detection.builders import dataset_builder
from object_detection.builders import graph_rewriter_builder
from object_detection.builders import model_builder
from object_detection.legacy import trainer
from object_detection.utils import config_util
tf.logging.set_verbosity(tf.logging.INFO)
flags = tf.app.flags
flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
flags.DEFINE_integer('task', 0, 'task id')
flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy per worker.')
flags.DEFINE_boolean('clone_on_cpu', False,
'Force clones to be deployed on CPU. Note that even if '
'set to False (allowing ops to run on gpu), some ops may '
'still be run on the CPU if they have no GPU kernel.')
flags.DEFINE_integer('worker_replicas', 1, 'Number of worker+trainer '
'replicas.')
flags.DEFINE_integer('ps_tasks', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.')
flags.DEFINE_string('train_dir', '',
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('type', '',
'Directory to save the checkpoints and training summaries.') //add to the content
flags.DEFINE_integer('index', 0,
'Number of parameter server tasks. If None, does not use '
'a parameter server.') //add to the content
flags.DEFINE_string('pipeline_config_path', '',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')
flags.DEFINE_string('train_config_path', '',
'Path to a train_pb2.TrainConfig config file.')
flags.DEFINE_string('input_config_path', '',
'Path to an input_reader_pb2.InputReader config file.')
flags.DEFINE_string('model_config_path', '',
'Path to a model_pb2.DetectionModel config file.')
flags.DEFINE_string('cluster_data', '',
'Path to a model_pb2.DetectionModel config file.')
FLAGS = flags.FLAGS
@tf.contrib.framework.deprecated(None, 'Use object_detection/model_main.py.')
def main(_):
assert FLAGS.train_dir, '`train_dir` is missing.'
if FLAGS.task == 0: tf.gfile.MakeDirs(FLAGS.train_dir)
if FLAGS.pipeline_config_path:
configs = config_util.get_configs_from_pipeline_file(
FLAGS.pipeline_config_path)
if FLAGS.task == 0:
tf.gfile.Copy(FLAGS.pipeline_config_path,
os.path.join(FLAGS.train_dir, 'pipeline.config'),
overwrite=True)
else:
configs = config_util.get_configs_from_multiple_files(
model_config_path=FLAGS.model_config_path,
train_config_path=FLAGS.train_config_path,
train_input_config_path=FLAGS.input_config_path)
if FLAGS.task == 0:
for name, config in [('model.config', FLAGS.model_config_path),
('train.config', FLAGS.train_config_path),
('input.config', FLAGS.input_config_path)]:
tf.gfile.Copy(config, os.path.join(FLAGS.train_dir, name),
overwrite=True)
model_config = configs['model']
train_config = configs['train_config']
input_config = configs['train_input_config']
model_fn = functools.partial(
model_builder.build,
model_config=model_config,
is_training=True)
def get_next(config):
return dataset_builder.make_initializable_iterator(
dataset_builder.build(config)).get_next()
create_input_dict_fn = functools.partial(get_next, input_config)
env = json.loads(os.environ.get('TF_CONFIG', '{}'))
cluster_data = { //Change content
"worker":[
"192.168.1.109:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]
}
#cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
cluster = tf.train.ClusterSpec(cluster_data) if cluster_data else None
task_data = env.get('task', None) or {'type': 'master', 'index': 0}
task_info = type('TaskSpec', (object,), task_data)
# Parameters for a single worker.
ps_tasks = 0
worker_replicas = 1
worker_job_name = 'lonely_worker'
task = 0
is_chief = True
master = ''
task_info.type=FLAGS.type //add to the content
task_info.index = FLAGS.index //add to the content
if cluster_data and 'worker' in cluster_data:
# Number of total worker replicas include "worker"s and the "master".
worker_replicas = len(cluster_data['worker']) + 1
if cluster_data and 'ps' in cluster_data:
ps_tasks = len(cluster_data['ps'])
print('ps_tasks%d',ps_tasks)
if worker_replicas > 1 and ps_tasks < 1:
raise ValueError('At least 1 ps task is needed for distributed training.')
if worker_replicas >= 1 and ps_tasks > 0:
# Set up distributed training. // commented out
# server = tf.train.Server(tf.train.ClusterSpec(cluster), protocol='grpc',
# job_name=task_info.type,
# task_index=task_info.index)
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index) //Change content
print('Get into worker%d',worker_replicas)
if task_info.type == 'ps' :
server = tf.train.Server(cluster, job_name=task_info.type, task_index=task_info.index)
print('Get into ps')
server.join()
worker_job_name = '%s/task:%d' % (task_info.type, task_info.index)
task = task_info.index
is_chief = (task_info.type == 'master')
master = server.target
graph_rewriter_fn = None
if 'graph_rewriter_config' in configs:
graph_rewriter_fn = graph_rewriter_builder.build(
configs['graph_rewriter_config'], is_training=True)
trainer.train(
create_input_dict_fn,
model_fn,
train_config,
master,
task,
FLAGS.num_clones,
worker_replicas,
FLAGS.clone_on_cpu,
ps_tasks,
worker_job_name,
is_chief,
FLAGS.train_dir,
graph_hook_fn=graph_rewriter_fn)
if __name__ == '__main__':
tf.app.run()
Execution of orders
After the code has been written, execute the relevant commands:
ps machine execution code: enter the virtual environment and at the same level as the train file.
c:\TFWS\VENVGPU\Scripts\activate cd C:\TFWS\models\research\object_detection\legacy python train.py --logtostderr --train_dir=C:\TFWS\models\research\object_detection\do_data\training --pipeline_config_path=C:\TFWS\models\research\object_detection\do_data\training\ssd_mobilenet_v1_coco.config --type=ps --index=0
The master executes the code: Enter the virtual environment and be at the same level as the train file.
c:\TFWS\VENVGPU\Scripts\activate cd C:\TFWS\models\research\object_detection\legacy python train.py --logtostderr --train_dir=C:\TFWS\models\research\object_detection\do_data\training --pipeline_config_path=C:\TFWS\models\research\object_detection\do_data\training\ssd_mobilenet_v1_coco.config --type=master --index=0
worker Execution Code: Enter the virtual environment and be at the same level as the train file.
c:\TFWS\VENVGPU\Scripts\activate cd C:\TFWS\models\research\object_detection\legacy python train.py --logtostderr --train_dir=C:\TFWS\models\research\object_detection\do_data\training --pipeline_config_path=C:\TFWS\models\research\object_detection\do_data\training\ssd_mobilenet_v1_coco.config --type=worker --index=0
The order of execution is: first execute the ps machine, then execute the master machine, and then execute the worker machine.
When the ps machine starts successfully, it shows:

When the master machine starts successfully, it shows that it is waiting for the access of the worker machine.

When the worker machine starts up successfully, the master machine displays:

worker and master are trained at the same time to achieve distributed (asynchronous) effect.
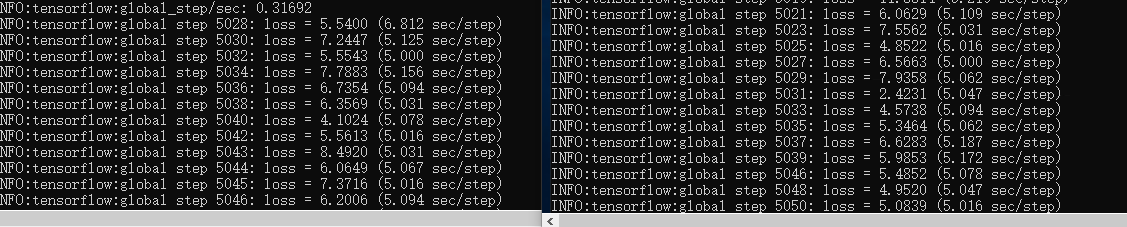
When there are more than one worker, the order cannot be reversed, for example:
"worker":[
"192.168.1.109:2222",
"192.168.1.111:2222",
"192.168.1.113:2222"
],
"ps":[
"192.168.1.116:2224"
],
"master":[
"192.168.1.108:2223"
]Then workerindex=0 must be the first, index=1 must be the second, and so on.
Configuration screenshot
The following picture shows the ps machine
The following illustrations show worker and master machines