Recently, I studied the knowledge of artificial intelligence image recognition, using the famous tensorflow tool. At the same time, in order to avoid repeated wheel building, I used the object detection api implemented by Google to realize image recognition. The download address is as follows: https://github.com/tensorflow/models
In fact, there are many tutorials on the installation of environment, but most of them are based on tensorflow1 0, based on tensorflow2 0 is not much, but the overall installation is not complicated. There are some pits, but there are not many. We will not introduce them in detail in this chapter. The main purpose of this chapter is to prepare the training data needed to train your own identification model.
For example, if we want to identify eggs, we must prepare a large number of egg images, such as 1000, including 900 train training data (including verification data) and 100 test data, and then manually label these images, which we use LabelImg This small software manually labels the pictures in train and test, as shown in the figure below.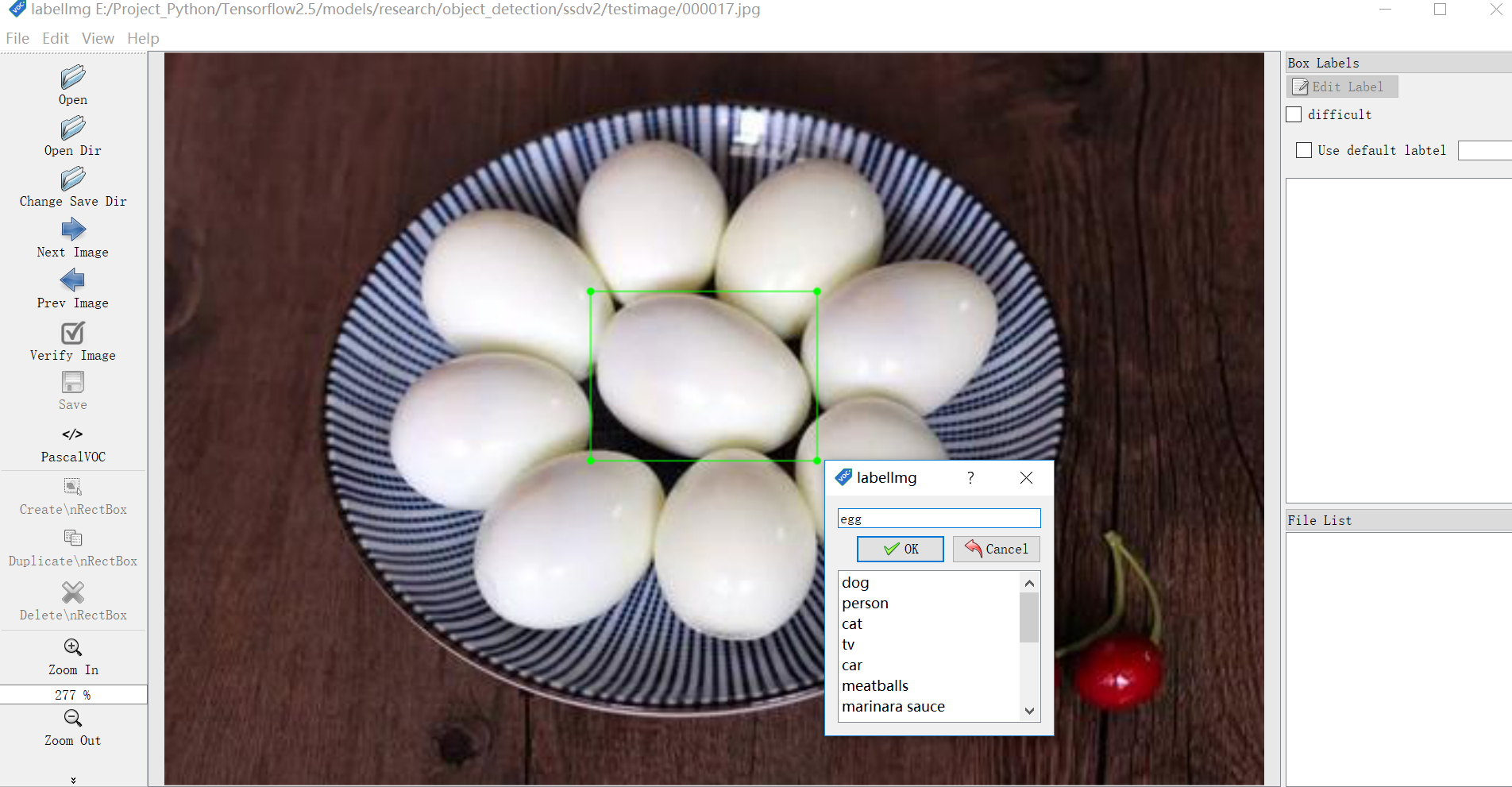
When the data is labeled, we need to place the pictures and annotation files (xml format) in the file format of VOC. The directory structure is shown in the following figure:

Annotation files are stored in Annotations:
JPEGImages to store image files:
Note that the file names of the label file and the picture file should correspond one by one.
Finally, create four text files in the Main subdirectory of ImageSet as follows:
 So far, even if the first step of our data processing is ready, the next step needs to generate the data of the text file in {ImageSet/Main through the code. In fact, this step is to divide all the pictures into three parts: training set, verification set and test set, and write the segmented information into the corresponding text file in Main. The segmentation code is as follows:
So far, even if the first step of our data processing is ready, the next step needs to generate the data of the text file in {ImageSet/Main through the code. In fact, this step is to divide all the pictures into three parts: training set, verification set and test set, and write the segmented information into the corresponding text file in Main. The segmentation code is as follows:
import xml.etree.ElementTree as ET
import os
import random
import cv2 as cv
def change_image_format(old_format='.png', new_format='.jpg'):
img_dir = "../VOC2012/JPEGImages/"
files = os.listdir(img_dir)
for img_file in files:
if os.path.isfile(os.path.join(img_dir, img_file)):
image_path = os.path.join(img_dir, img_file)
# print(image_path)
image = cv.imread(image_path)
new_image_path = image_path.replace(old_format, new_format)
cv.imwrite(new_image_path, image, [cv.IMWRITE_JPEG_QUALITY, 100])
print("processed image : %s" % (new_image_path))
def xml_modification():
ann_dir = "../VOC2012/Annotations/"
img_dir = "E:/Project_Python/TensorflowTest/models/research/object_detection/ssd_model/VOCdevkit/VOC2012/JPEGImages/" #Change to your own directory
files = os.listdir(ann_dir)
for xml_file in files:
if os.path.isfile(os.path.join(ann_dir, xml_file)):
xml_path = os.path.join(ann_dir, xml_file)
# print(xml_path)
tree = ET.parse(xml_path)
root = tree.getroot()
for elem in root.iter('folder'):
elem.text = 'voc2012'
for elem in root.iter('filename'):
pass
for elem in root.iter('path'):
path = elem.text
filename = path.split('/')[-1]
new_path = img_dir + filename
elem.text = new_path
tree.write(xml_path)
print("processed xml : %s" % (xml_path))
def generate_train_val_test_txt():
xml_file_path = "../VOC2012/Annotations/"
save_Path = "../VOC2012/ImageSets/Main/"
trainval_percent = 0.9
train_percent = 0.9
total_xml = os.listdir(xml_file_path)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("train size", tr)
ftrainval = open(os.path.join(save_Path, 'trainval.txt'), 'w')
ftest = open(os.path.join(save_Path, 'test.txt'), 'w')
ftrain = open(os.path.join(save_Path, 'train.txt'), 'w')
fval = open(os.path.join(save_Path, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
xml_modification()
generate_train_val_test_txt()
After completing this step, the last part of the conversion will be done later. For the image recognition of tensorflow, the training data is required to be in the format of tfrecord. Most of the online tutorials are based on tensorflow 1 0, so the format conversion needs to be transferred through csv files, which is troublesome. Fortunately, tesnorflow2 After 0, the object detection api has provided us with a tool for direct conversion. The conversion can be completed with two simple commands:
Python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=object_detection/ssdv2/pascal_label_map.pbtxt --data_dir=object_detection/ssdv2/VOCdevkit --year=VOC2012 --set=train --output_path=object_detection/ssdv2/egg_train.record Python object_detection/dataset_tools/create_pascal_tf_record.py --label_map_path=object_detection/ssdv2/pascal_label_map.pbtxt --data_dir=object_detection/ssdv2/VOCdevkit --year=VOC2012 --set=val --output_path=object_detection/ssdv2/egg_val.record
Pascal here_ label_ map. Pbtxt file needs to be prepared in advance, which is the record of marking results.
When you see that two record files are generated, congratulations. Even if the training data is completely ready, let's go next!