Implementation of BPE algorithm in the original text of BPE algorithm:
import re
import collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i], symbols[i+1]] += freq # Calculate byte pair occurrence frequency
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair)) # Escape characters in byte pairs that can be interpreted as regular operators
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') # The byte pair to be merged can only be preceded by white space characters
for word in v_in:
w_out = p.sub(''.join(pair), word) # Merge qualified byte pairs
v_out[w_out] = v_in[word]
return v_out
The above is BPE
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2,
'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get) # Select the byte pair with the highest frequency
vocab = merge_vocab(best, vocab)
print(best)

Code test
https://www.cnblogs.com/wwj99/p/12503545.html Process source
Train again according to the pre training model and check step by step according to the running order
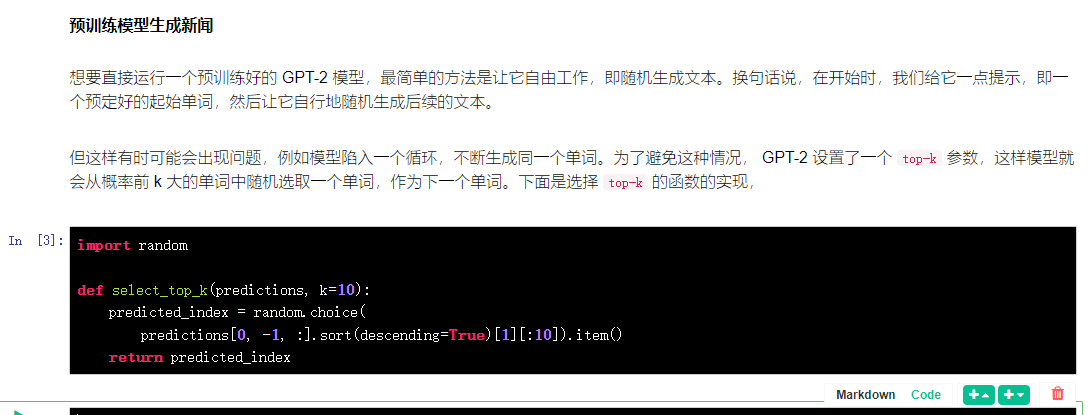
import random
def select_top_k(predictions, k=10):
predicted_index = random.choice(
predictions[0, -1, :].sort(descending=True)[1][:10]).item()
return predicted_index
Following the introduction of the GPT-2 model, we will use the GPT2Tokenizer() and GPT2LMHeadModel() classes encapsulated in the pytorch transformers model library to actually see the ability of GPT-2 to predict the next word after pre training. First, you need to install pytorch transformers.
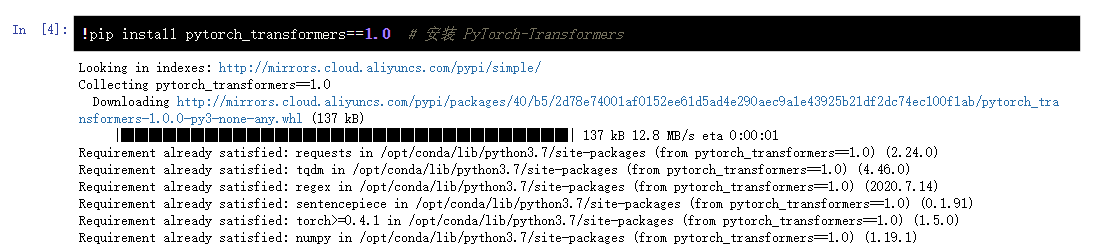
Using the pytorch transformers model library, first set the example of preparing the input model, and use GPT2Tokenizer() to establish a word breaker object to encode the original sentence.
import torch
from pytorch_transformers import GPT2Tokenizer
import logging
logging.basicConfig(level=logging.INFO)
# Word splitter loaded with pre training model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Use GPT2Tokenizer to encode the input
text = "Yesterday, a man named Jack said he saw an alien,"
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
tokens_tensor.shape
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/gpt2-shiyanlou.zip" !unzip -o "gpt2-shiyanlou.zip"
from pytorch_transformers import GPT2LMHeadModel
# Read GPT-2 pre training model
model = GPT2LMHeadModel.from_pretrained("./")
model.eval()
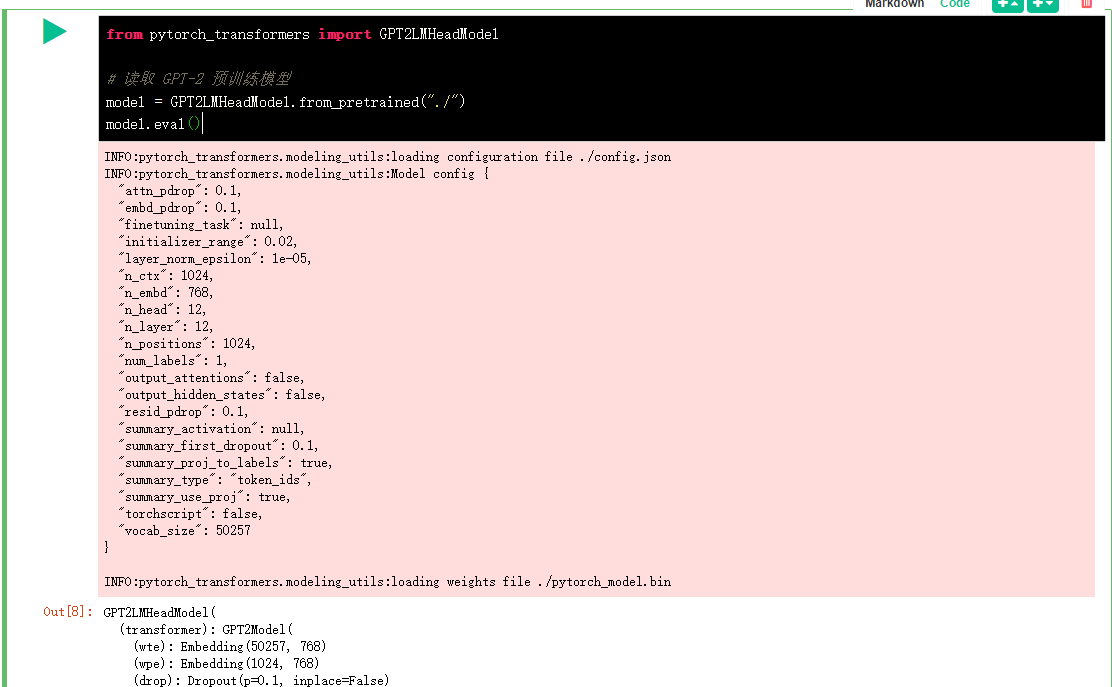
I'm curious about what the pre training model downloaded has. Check it out.

Test the text writing with the short text above:
total_predicted_text = text
n = 100 # Number of cycles in the prediction process
for _ in range(n):
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# If the end of text flag appears, the text generation ends
break
indexed_tokens += [predicted_index]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)

After running, we observe the text generated by the model. We can see that it generally feels like a normal text. However, if we look carefully, we will find the logic problems in the statement, which will be solved by researchers in the future.
Next, we will use some drama scripts to fine tune GPT-2. Since the open source GPT-2 model pre training parameters of OpenAI team are obtained after pre training with English data sets, although Chinese data sets can be used during fine-tuning, it takes a lot of data and time to have good results. Therefore, we use English data sets for fine-tuning, so as to better show the ability of GPT-2 model.
First, download the training data set. Here, Shakespeare's play Romeo and Juliet is used as the training sample. We have downloaded the dataset in advance and put it in the blue bridge cloud course server. You can download it through the following command.
!wget -nc "https://labfile.oss.aliyuncs.com/courses/1372/romeo_and_juliet.zip" !unzip -o "romeo_and_juliet.zip"
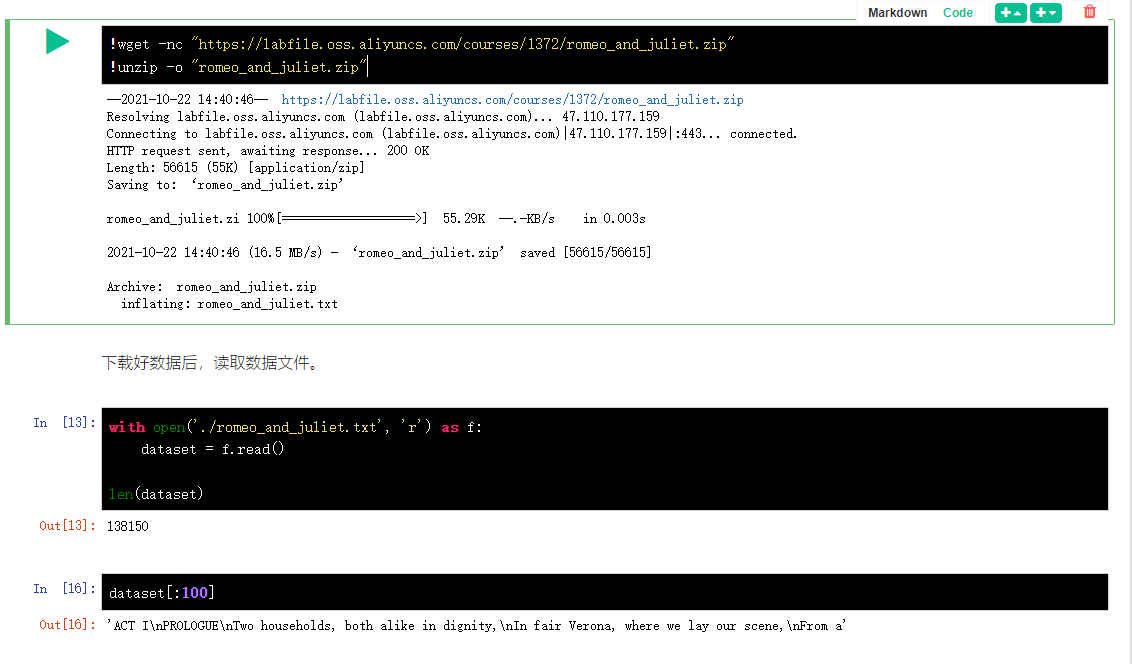
The data set read is a string.
Preprocess the training set, encode and segment the training set.
indexed_text = tokenizer.encode(dataset)
del(dataset)
dataset_cut = []
for i in range(len(indexed_text)//512):
# Segment the string to 512
dataset_cut.append(indexed_text[i*512:i*512+512])
del(indexed_text)
dataset_tensor = torch.tensor(dataset_cut)
dataset_tensor.shape
Here I run the tests separately
First encode the character tokenizer: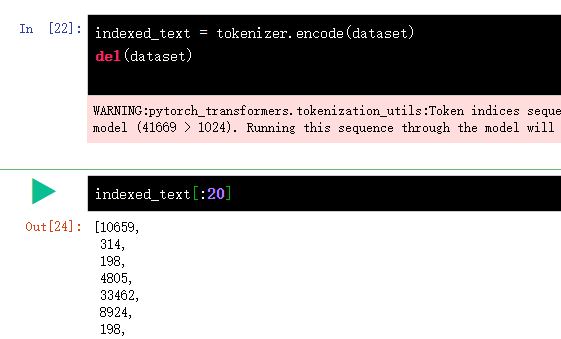
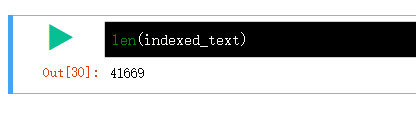
A total of 41669 is constructed as 81 * 512 = 41472, some characters are missing.
Check the data format. The data should not be completely divided. What if there is no division in the end?


Set dataset_ Convert cut to tensor format in pytorch
Here, we use the DataLoader() provided by PyTorch to build the training set data set representation, and use TensorDataset() to build the training set data iterator.
from torch.utils.data import DataLoader, TensorDataset
# Build data sets and data iterators, and set batch_ The size is 2
train_set = TensorDataset(dataset_tensor,
dataset_tensor) # The label is the same as the sample data
train_loader = DataLoader(dataset=train_set,
batch_size=2,
shuffle=False)
train_loader
Input in training set data = output,
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

Start training.
from torch import nn
from torch.autograd import Variable
import time
pre = time.time()
epoch = 30 # Cycle learning 30 times
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5) # Define optimizer
for i in range(epoch):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target).to(device)
optimizer.zero_grad()
loss, logits, _ = model(data, labels=target)
total_loss += loss
loss.backward()
optimizer.step()
if batch_idx == len(train_loader)-1:
# Output the results at the end of each Epoch
print('average loss:', total_loss/len(train_loader))
print('Training time:', time.time()-pre)

text = "From fairest creatures we desire" # You can also enter different English texts here indexed_tokens = tokenizer.encode(text) tokens_tensor = torch.tensor([indexed_tokens])
model.eval()
total_predicted_text = text
# Make the trained model predict 500 times
for _ in range(500):
tokens_tensor = tokens_tensor.to('cuda')
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '<|endoftext|>' in total_predicted_text:
# If the end of text flag appears, the text generation ends
break
indexed_tokens += [predicted_index]
if len(indexed_tokens) > 1023:
# The longest input length of the model is 1024. If the length is too long, it will be truncated
indexed_tokens = indexed_tokens[-1023:]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)