Author: a Shui, member of Datawhale, Beijing University of Aeronautics and Astronautics
Taking the ECG intelligent diagnosis competition of the world AI innovation competition (AIWIN) as the practice background, this paper gives the common ideas and processes of data mining practice. This project uses TextCNN model for practice.
Code address:
https://aistudio.baidu.com/aistudio/projectdetail/2653802
Competition background and tasks
ECG is the most basic clinical examination item, because it is safe and convenient, it has become a sharp tool for heart disease diagnosis. Due to the high standardization of ECG data and diagnosis, it is relatively easy to use artificial intelligence technology to develop intelligent diagnosis algorithm. This practice outputs binary (normal v.s abnormal) classification labels for ECG data.
Competition address: http://ailab.aiwin.org.cn/competitions/64
Competition data
The data will be divided into two parts: the training set with visible tags and the test set with invisible tags. The training data provides 1600 ECG data in MAT format and its corresponding diagnostic classification labels ("normal" or "abnormal", csv format); The test data provides 400 ECG data in MAT format.
- Data directory
DATA |- trainreference.csv TRAIN Data in directory LABEL
|- TRAIN Training data
|- VAL test data
- data format
- 12 lead data, saved in matlab format file. The data format is (12, 5000).
- Sampling 500HZ, 10S length valid data. Refer to the following code for the specific reading method.
- 0.. 12 are I, II, III, aVR, aVL, aVF, V1, V2, V3, V4, V5 and V6 data. The unit is mV.
import scipy.io as sio
ecgdata = sio.loadmat("TEST0001.MAT")['ecgdata']
- trainreference.csv format: one file per line. Format: file name, LABEL (0 normal ECG, 1 abnormal ECG)
Practical ideas
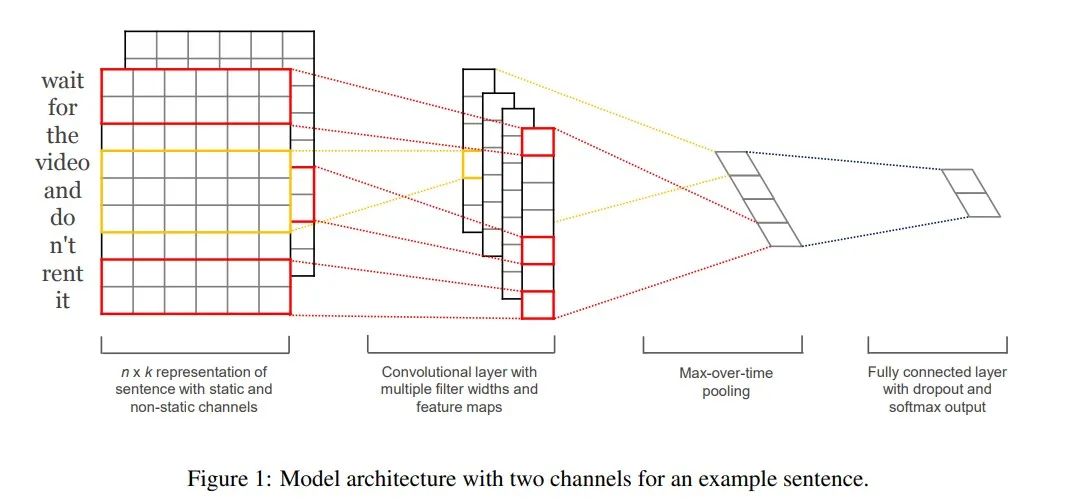
TextCNN model is the revolutionary neural networks for sense classification published by Yoon Kim of Harvard NLP group in 2014 The model proposed in this paper, because CNN is often used to extract the local feature map of image in computer vision, and has played a good effect, the author introduces it into NLP and applies it to the text classification task, trying to use CNN to capture the relationship between words in the text.
This practice uses TextCNN model to classify ECG data.
Improvement ideas
- Multi fold cross validation is used to train multiple models and predict the test set many times.
- When reading data, add noise or mixup data amplification.
- Using a more powerful model, textcnn is still too simple here.
Practice code
data fetch
!\rm -rf val train trainreference.csv Data description.txt ! unzip 2021A_T2_Task1_The data set includes training set and test set.zip > out.log import codecs, glob, os import numpy as np import pandas as pd import paddle import paddle.nn as nn from paddle.io import DataLoader, Dataset import paddle.optimizer as optim from paddlenlp.data import Pad import scipy.io as sio
train_mat = glob.glob('./train/*.mat')
train_mat.sort()
train_mat = [sio.loadmat(x)['ecgdata'].reshape(1, 12, 5000) for x in train_mat]
test_mat = glob.glob('./val/*.mat')
test_mat.sort()
test_mat = [sio.loadmat(x)['ecgdata'].reshape(1, 12, 5000) for x in test_mat]
train_df = pd.read_csv('trainreference.csv')
train_df['tag'] = train_df['tag'].astype(np.float32)
class MyDataset(Dataset):
def __init__(self, mat, label, mat_dim=3000):
super(MyDataset, self).__init__()
self.mat = mat
self.label = label
self.mat_dim = mat_dim
def __len__(self):
return len(self.mat)
def __getitem__(self, index):
idx = np.random.randint(0, 5000-self.mat_dim)
return paddle.to_tensor(self.mat[index][:, :, idx:idx+self.mat_dim]), self.label[index]
model building
class TextCNN(paddle.nn.Layer):
def __init__(self, kernel_num=30, kernel_size=[3, 4, 5], dropout=0.5):
super(TextCNN, self).__init__()
self.kernel_num = kernel_num
self.kernel_size = kernel_size
self.dropout = dropout
self.convs = nn.LayerList([nn.Conv2D(1, self.kernel_num, (kernel_size_, 3000))
for kernel_size_ in self.kernel_size])
self.dropout = nn.Dropout(self.dropout)
self.linear = nn.Linear(3 * self.kernel_num, 1)
def forward(self, x):
convs = [nn.ReLU()(conv(x)).squeeze(3) for conv in self.convs]
pool_out = [nn.MaxPool1D(block.shape[2])(block).squeeze(2) for block in convs]
pool_out = paddle.concat(pool_out, 1)
logits = self.linear(pool_out)
return logits
model = TextCNN() BATCH_SIZE = 30 EPOCHS = 200 LEARNING_RATE = 0.0005 device = paddle.device.get_device() print(device) gpu:0
model training
Train_Loader = DataLoader(MyDataset(train_mat[:-100], paddle.to_tensor(train_df['tag'].values[:-100])), batch_size=BATCH_SIZE, shuffle=True)
Val_Loader = DataLoader(MyDataset(train_mat[-100:], paddle.to_tensor(train_df['tag'].values[-100:])), batch_size=BATCH_SIZE, shuffle=True)
model = TextCNN()
optimizer = optim.Adam(parameters=model.parameters(), learning_rate=LEARNING_RATE)
criterion = nn.BCEWithLogitsLoss()
Test_best_Acc = 0
for epoch in range(0, EPOCHS):
Train_Loss, Test_Loss = [], []
Train_Acc, Test_Acc = [], []
model.train()
for i, (x, y) in enumerate(Train_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
loss = criterion(pred, y)
Train_Loss.append(loss.item())
pred = (paddle.nn.functional.sigmoid(pred)>0.5).astype(int)
Train_Acc.append((pred.numpy() == y.numpy()).mean())
loss.backward()
optimizer.step()
optimizer.clear_grad()
model.eval()
for i, (x, y) in enumerate(Val_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
Test_Loss.append(criterion(pred, y).item())
pred = (paddle.nn.functional.sigmoid(pred)>0.5).astype(int)
Test_Acc.append((pred.numpy() == y.numpy()).mean())
print(
"Epoch: [{}/{}] TrainLoss/TestLoss: {:.4f}/{:.4f} TrainAcc/TestAcc: {:.4f}/{:.4f}".format( \
epoch + 1, EPOCHS, \
np.mean(Train_Loss), np.mean(Test_Loss), \
np.mean(Train_Acc), np.mean(Test_Acc) \
) \
)
if Test_best_Acc < np.mean(Test_Acc):
print(f'Acc imporve from {Test_best_Acc} to {np.mean(Test_Acc)} Save Model...')
paddle.save(model.state_dict(), "model.pdparams")
Test_best_Acc = np.mean(Test_Acc)
Result prediction
Test_Loader = DataLoader(MyDataset(test_mat, paddle.to_tensor([0]*len(test_mat))),
batch_size=BATCH_SIZE, shuffle=False)
layer_state_dict = paddle.load("model.pdparams")
model.set_state_dict(layer_state_dict)
test_perd = np.zeros(len(test_mat))
for tta in range(10):
test_pred_list = []
for i, (x, y) in enumerate(Test_Loader):
if device == 'gpu':
x = x.cuda()
y = y.cuda()
pred = model(x)
test_pred_list.append(
paddle.nn.functional.sigmoid(pred).numpy()
)
test_perd += np.vstack(test_pred_list)[:, 0]
print(f'Test TTA {tta}')
test_perd /= 10
test_path = glob.glob('./val/*.mat')
test_path = [os.path.basename(x)[:-4] for x in test_path]
test_path.sort()
test_answer = pd.DataFrame({
'name': test_path,
'tag': (test_perd > 0.5).astype(int)
})