First let's look at the characteristics of NiN networks:
(1) Use of 1 x 1 convolution
Use the mlpconv network layer instead of the traditional convolution layer.The mlp layer is actually a convolution plus traditional mlp (Multilayer Perceptor), because convolution is linear and mlp is nonlinear, which can be more abstract and more generalizable.In the case of cross channel (cross feature map), mlpconv is equivalent to convolution layer + 1 x 1 convolution layer, so mlpconv layer is also called cccp layer (cascaded cross channel parametric pooling).
(2) No use of FC layer in CNN network (full connection layer)
Global Average Pooling is proposed to replace the final full-join layer because it has many parameters and is easy to fit.This removes the full connection layer and adds an Average Pooling layer to the last layer (using mlpconv).
The above two points are important because they reduce the number of parameters to a large extent and can really get a good result.The reduction of parameter size not only limits the increase of network layers due to too many parameters, too large network size, insufficient GPU memory and so on, thus limiting the generalization ability of the model, but also improves the training time.
(1) NiN blocks
NiN uses a 1 x 1 convolution layer instead of a full connection layer, allowing spatial information to be naturally transferred to the later layers.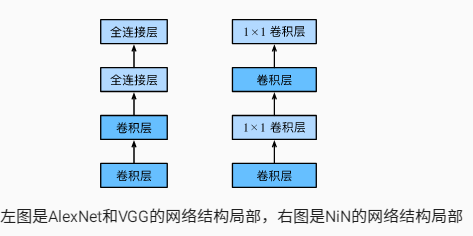
Defines a NiN block, which consists of one convolution layer and two 1*1 convolution layers acting as fully connected layers
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
def nin_block(num_channels, kernel_size, strides, padding):
blk = nn.Sequential()
blk.add(nn.Conv2D(num_channels, kernel_size,
strides, padding, activation='relu'),
nn.Conv2D(num_channels, kernel_size=1, activation='relu'),
nn.Conv2D(num_channels, kernel_size=1, activation='relu'))
return blk
(2) NiN model layer
NiN replaces AlexNet's last three full connection layers by using NiN blocks with output channels equal to label categories, then averaging all elements in each channel using a global average pooling layer and directly classifying them.
Problems with full connection: too many parameters, reduced training speed, and easy to over-fit
About global average pooling:
It is mainly used to solve the problem of full connection. It is mainly to pool the feature map of the last layer into a mean value of the whole graph to form a feature point, and make these feature points into the final feature vector for calculation in softmax.
The real meaning of GAP is to regularize the structure of the entire network to prevent overfitting.It directly eliminates the characteristics of black boxes in the full connection layer and gives each channel a real meaning.
Practice has proved that the effect is considerable, and GAP can be used to input any image size.However, it is worth noting that the use of gap may slow down the convergence rate.

net = nn.Sequential()
net.add(nin_block(96, kernel_size=11, strides=4, padding=0), #NiN Block
nn.MaxPool2D(pool_size=3, strides=2),
nin_block(256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2D(pool_size=3, strides=2),
nin_block(384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2D(pool_size=3, strides=2), nn.Dropout(0.5),
nin_block(10, kernel_size=3, strides=1, padding=1), # Number of label categories is 10
nn.GlobalAvgPool2D(), # Global Average Pooling Layer automatically sets the window shape to the height and width of the input
nn.Flatten()) # Converts a four-dimensional output to a two-dimensional output in the shape of (batch size, 10)
X = nd.random.uniform(shape=(1, 1, 224, 224))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)
 (3) Acquiring data and training models:
(3) Acquiring data and training models:
lr, num_epochs, batch_size, ctx = 0.1, 5, 128, d2l.try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx,
num_epochs)