Basic concepts
In order to meet the real-time performance of search, ES will speed up the return of results by losing accuracy in some scenarios of aggregation analysis. This is actually a trade-off between real-time and accuracy.
It should be clear that not all aggregation analysis will lose accuracy, such as min,max and so on.
It may be difficult to understand this directly. A detailed analysis will be given below.
Problem description
We introduce the problem through an example.
First, I will reindex kibana's own flight information index (named kibana_sample_data_flights) into an index I customize (named my_flights). My mapping is exactly the same as my own index. The only difference is that I set 20 slices. The index settings are as follows:
PUT my_flights
{
"settings": {
"number_of_shards": 20
},
"mappings" : {
"properties" : {
"AvgTicketPrice" : {
"type" : "float"
},
Omit other parts
The process of reindex (there will be a special article on reindex in the future) is relatively slow. My computer takes about a minute.
POST _reindex
{
"source": {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "my_flights"
}
}
Then we execute the query of aggregation analysis, which divides barrels according to the destination of flights.
GET my_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
}
}
}
}
give the result as follows
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 20,
"successful" : 20,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 52,
"sum_other_doc_count" : 3187,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
{
"key" : "US",
"doc_count" : 1987
},
Other parts are omitted
In the aggregations of the returned results, there are two values: doc_count_error_upper_bound and sum_other_doc_count, let me explain first,
doc_count_error_upper_bound: indicates potential aggregation results that are not returned in this aggregation but may exist.
sum_other_doc_count: indicates the number of documents not counted in this aggregation. This is easy to understand, because by default, only the top 10 buckets will be displayed according to the count during ES statistics. If there are many categories (here is the destination), naturally there will be documents that have not been counted.
And this doc_count_error_upper_bound is the focus of this article. This indicator is actually to tell users how imprecise the aggregation results are.
problem analysis
ES is based on distributed, and the requests for aggregation analysis are distributed to all slices for separate processing, and finally the results are summarized. The terms aggregation of ES itself is the result of the first few (size specified), which leads to the inevitable error of the result.
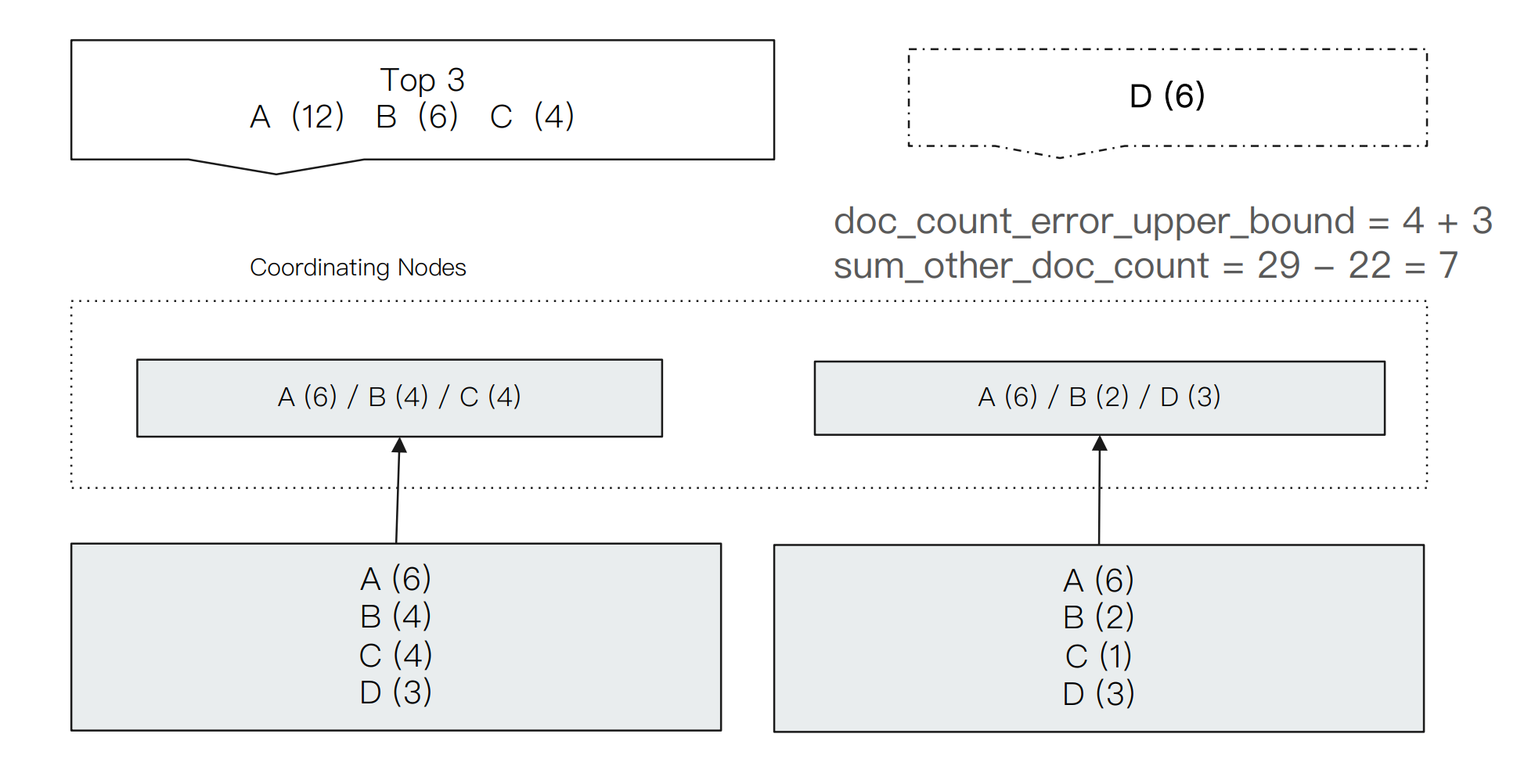
As shown in the figure above, we perform A bucket query of terms and take the first three results. The results given by ES are three terms A, B and C, and the number of documents is 12, 6 and 4 respectively.
However, when we look at the document distribution on the bottom two slices, we can also see that in fact, D should be in the result. Because there are 6 documents in D, which is more than C, the more accurate result should be A, B and D.
The reason for the problem is that when ES processes each partition separately, the results of the first partition are a, B and C, the second partition is a, B and D, and the number of documents of C in the first partition is greater than D. So the results after summary are a, B and C.
How to improve accuracy
After the discussion, let's see how to solve the problem. There are several general schemes:
Undivided
Set the main partition to 1, that is, no partition. It is obvious that the core reason for the inaccuracy of aggregation in the above analysis lies in fragmentation, so non fragmentation can certainly solve the problem. However, the disadvantages are also obvious. It is only applicable to the case of small amount of data. If the amount of data is mostly on one slice, the performance of ES will be affected.
Let's do a test to see the effect of non segmentation. We use our own kibana_sample_data_flights index to perform bucket aggregation.
GET kibana_sample_data_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
, "size": 3
}
}
}
}
The result is:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 7605,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
Other parts are omitted
Because kibana_ sample_ data_ The number of slices in the flights index is 1, so there is no loss of accuracy.
Increase the number of aggregations
As shown below, set the size to 20 (the default is 10) to aggregate queries. Size is the number of results returned by the specified aggregation. The more results returned, the higher the accuracy.
GET my_flights/_search
{
"size": 0,
"aggs": {
"dest": {
"terms": {
"field": "DestCountry"
, "size": 20
}
}
}
}
result,
"aggregations" : {
"dest" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 571,
"buckets" : [
{
"key" : "IT",
"doc_count" : 2371
},
Other parts are omitted
As a result, there is no loss of accuracy.
Turn up shard_size value
This value indicates the number of documents to be calculated from the slice. By default, it is the same as size. The larger the value of size, the more accurate the result will be, but it will obviously affect the performance.
summary
Some aggregation statistics of ES will lose accuracy
The reason for the loss of accuracy is the error caused by the intermediate results of slice processing and summary, which is the trade-off between ES real-time and accuracy
You can turn up the shard_size and other methods to increase accuracy
reference resources:
Geek time "Elasticsearch core technology and practice"