1. Course content
For details, please refer to the course "beauty of data structure and algorithm" on "geek time": 09 | queue: application of queue in limited resource pools such as process pool (geekbang.org)
2. After class practice

code
Array queue
package dataStruct;
/**
* @ClassName ArrayQueue
* @Version 1.0
* @Author Wulc
* @Date 2022-02-12 11:54
* @Description Array queue
*/
public class MyArrayQueue {
// Array: items, array size: n
public Object[] items;
public int n = 0;
// Head indicates the team head subscript and tail indicates the team tail subscript
public int head = 0;
public int tail = 0;
// Apply for an array of size capacity
public MyArrayQueue(int capacity) {
items = new Object[capacity];
n = capacity;
}
// Out of the team
public Object dequeue() {
// If head == tail, the queue is empty
if (head == tail) {
return null;
}
Object ret = items[head];
++head;
return ret;
}
// Join the queue and put the item at the end of the queue
public boolean enqueue(Object item) {
// tail == n indicates that there is no space at the end of the queue
if (tail == n) {
// Tail = = n & & head = = 0 indicates that the whole queue is full
if (head == 0) {
return false;
}
// Data movement, because the previous out of line operation may lead to redundant space on the left side of the array. Therefore, when entering the queue, if there is redundant space on the left side of the array, move the whole array to the left
for (int i = head; i < tail; ++i) {
items[i - head] = items[i];
}
// After the move, update the head and tail again
tail -= head;
head = 0;
}
items[tail] = item;
++tail;
return true;
}
}
List Queue
package dataStruct;
/**
* @ClassName LinkedListQueue
* @Version 1.0
* @Author Wulc
* @Date 2022-02-12 12:19
* @Description
*/
public class MyLinkedListQueue {
//Linked list
public ListNode<Object> listNode;
//Team leader
public Node<Object> head;
//Team tail
public Node<Object> tail;
//Queue size
public int n;
public MyLinkedListQueue() {
this.listNode = new ListNode<>();
//During initialization, both the head and tail pointers point to the head node of the linked list
this.head = this.listNode.head;
this.tail = this.listNode.head;
}
//Queue
public boolean enqueue(Object item) {
this.listNode.addNode(item);
//The pointer at the end of the line goes back one
this.tail = this.tail.next;
n++;
return true;
}
//Out of queue
public Object dequeue() {
// If head == tail, the queue is empty
if (this.head == this.tail) {
return null;
}
this.head = this.head.next;
this.listNode.removeLastN(n);
n--;
return this.head.data;
}
}
Circular queue (implemented with array)
package dataStruct;
/**
* @ClassName MyCircularArrayQueue
* @Version 1.0
* @Author Wulc
* @Date 2022-02-12 21:40
* @Description Array loop queue
*/
public class MyCircularArrayQueue {
// Array: items, array size: n
private String[] items;
private int n = 0;
// Head indicates the team head subscript and tail indicates the team tail subscript
private int head = 0;
private int tail = 0;
// Apply for an array of size capacity
public MyCircularArrayQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// Join the team
public boolean enqueue(String item) {
// The queue is full
if ((tail + 1) % n == head) {
return false;
}
items[tail] = item;
tail = (tail + 1) % n;
return true;
}
// Out of the team
public String dequeue() {
// If head == tail, the queue is empty
if (head == tail) {
return null;
}
String ret = items[head];
head = (head + 1) % n;
return ret;
}
}
Note: circular queues are generally implemented with arrays. In fact, it is to prevent the possible "false overflow" of ordinary array queues. Circular queue should not be implemented with linked list, because there will be no "false overflow" phenomenon in the linked list queue itself. Moreover, using linked list to construct circular queue will lead to "stack overflow".
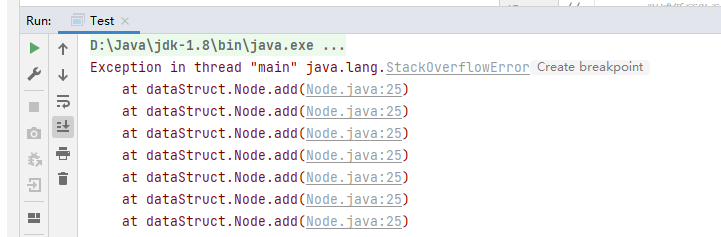
This is because if the linked list is used to realize the circular queue, the tail pointer is pointed to the head node, and there will be an endless loop. Causes "stack overflow".
3. After class thinking
Q1. In addition to thread pool, which pool structure will use queue queuing requests, do you know any similar pool structures or scenarios that will use queue queuing requests?
A1. In the operating system, process scheduling (FCFS) and page replacement algorithm (FIFO)
Q2. Today we talk about concurrent queues. There are many discussions on how to realize lockless concurrent queues on the Internet. What do you think of this problem?
A2. In fact, the so-called lock free concurrent queue refers to the implementation of atomic operations without locks. In java, a class ConcurrentLinkedQueue implements the lock free concurrent queue based on linked list. ConcurrentLinkedQueue is thread safe, because ConcurrentLinkedQueue is not thread safe through locking, so ConcurrentLinkedQueue is a "non blocking queue". The corresponding image is ArrayBlockingQueue. Because the lock is used, when some exceptions occur, such as the current queue is empty but there are still outgoing requests, the queue will be locked. As long as other threads add data to the current queue, the lock of outgoing requests will be unlocked and the outgoing operation will continue.

As shown in the figure above: put and take methods are added to the ArrayBlockingQueue class. Put is equivalent to enqueue with lock, and take is equivalent to dequeue with lock.
Take a producer / consumer example
package Practise;
import dataStruct.concurrent.MyConcurrentArrayQueueWithLock;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ConcurrentLinkedQueue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* @ClassName ThreadQueueConcurrentTest
* @Version 1.0
* @Author Wulc
* @Date 2022-02-14 15:28
* @Description
*/
public class TestArrayBlockingQueue {
static ArrayBlockingQueue<String> arrayBlockingQueue = new ArrayBlockingQueue(10);
public static void main(String[] args) throws InterruptedException {
Runnable productor = (new Runnable() {
@Override
public void run() {
try {
arrayBlockingQueue.put("commodity");
System.out.println("Insert an item into the queue");
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Runnable consumer = (new Runnable() {
@Override
public void run() {
try {
arrayBlockingQueue.take();
System.out.println("Get a product from the queue, and the remaining queue length" + (arrayBlockingQueue.size() - 1));
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
new Thread(productor).start();
new Thread(productor).start();
new Thread(consumer).start();
new Thread(consumer).start();
new Thread(consumer).start();
new Thread(consumer).start();
new Thread(consumer).start();
new Thread(consumer).start();
}
}
The producer is responsible for adding "goods" to the queue, and the consumer is responsible for taking "goods" from the queue. Because the take and put methods of ArrayBlockingQueue are used, when there is no "commodity" in the queue, the consumer thread will wait (lock the calling consumer thread so that other threads cannot call the consumer thread at that time, so as to solve the conflict) until the producer adds "commodity" to the queue, and the calling consumer thread will not be unlocked.
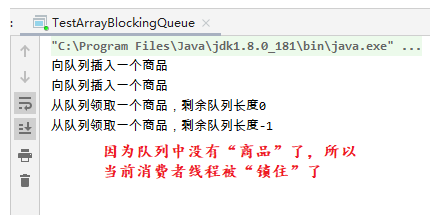

The advantage of blocking queue: when multithreading operates a common queue, there is no need for additional synchronization. In addition, the queue will automatically balance the load, that is, the processing speed on the other side (production and consumption sides) will be blocked, so as to reduce the processing speed gap between the two sides.
ConcurrentLinkedQueue is a non blocking queue. To solve thread conflicts, CAS makes a version comparison based on "optimistic lock", that is, CAS, to solve possible conflicts.
After a general review, it should be a process like this.
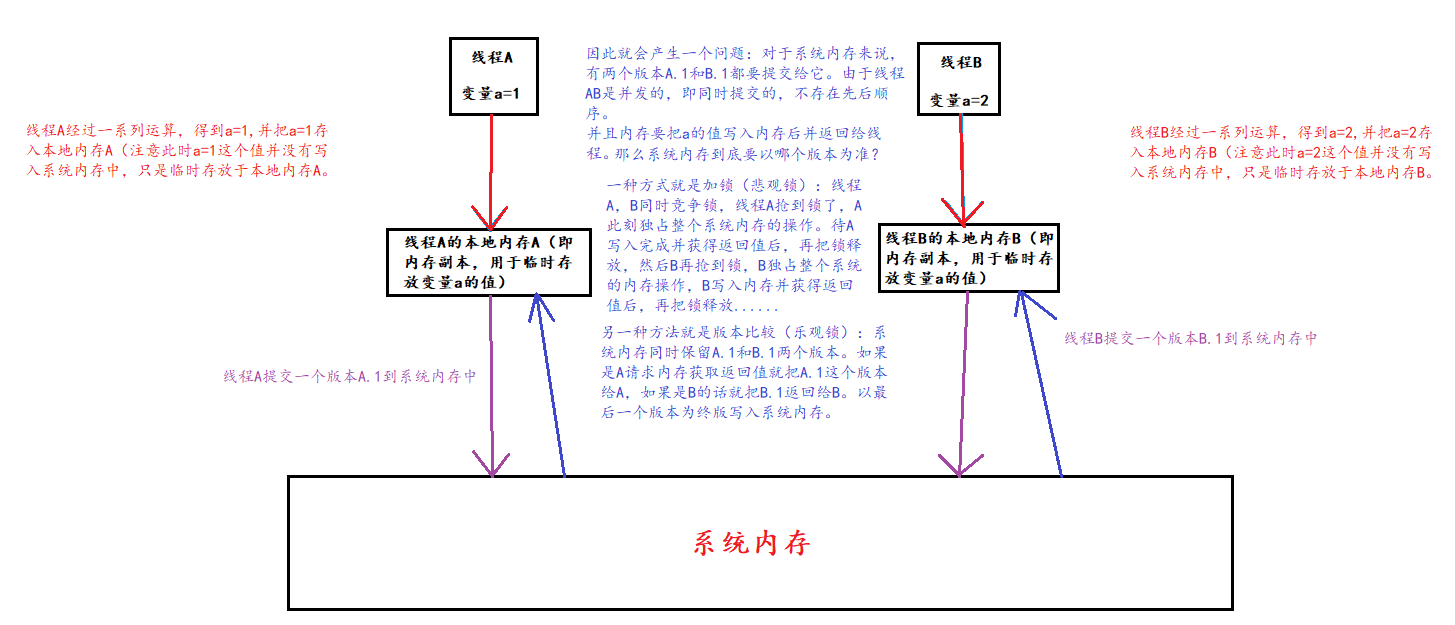
In my opinion, the ConcurrentLinkedQueue class realizes the thread safety of the head and tail pointers of the linked list queue through the compareAndSwap algorithm of volatile+Unsafe class.
volatile keyword is used to prevent "instruction rearrangement" during compilation. In fact, I don't quite understand why "instruction rearrangement" will affect thread safety. I read an article saying that in the case of concurrency, the CPU may rearrange the order of some existing instructions in order to facilitate execution.
The most complete summary of Java volatile Keywords: Principle Analysis and example explanation (easy to understand)_ Summer breeze - CSDN blog_ java volatile I read that the article mentioned "allocate memory", "initialize object" and "set address".

My understanding is: when you create a new object, you will first open up a space in memory. With this space, you will initialize the object, and then point the object to the newly opened space in memory. Then, in the case of high concurrency, a large number of new objects will be required in a very short time. For processing convenience, the CPU may not separately perform operations such as "allocate memory" - > "initialize object" - > "set address" for each object to be new. For example, the CPU first applies for a piece of memory space and then initializes the object. It is found that the previously applied memory space is not enough, so some objects cannot be initialized. Even if initialized, there is no extra space allocation for the time being, and the CPU can only re apply for a new piece of space, Therefore, the execution sequence is from "allocate memory first and then initialize the object" to "initialize the object first. It is found that there is no memory space, so the CPU allocates memory again". So back and forth.

compareAndSwap of Unsafe class, also referred to as "CAS algorithm".

The methods related to compareAndSwap are modified with "native". CAS itself is not implemented by java. java is just used. CAS algorithm is implemented in C language, which is closer to the operating system. Through the pointer of C language, it directly points to the memory address. Because the pointer directly operates the memory, the pointer of each address space is always unique no matter how many concurrent there are. Use the uniqueness of pointers to achieve thread safety.
Note: the understanding of volatile and CAS in this article is not necessarily accurate. I understand it according to the information found and my own knowledge reserve. There will be some mistakes. I will make supplementary corrections after I have learned the "java Memory Model".
In addition, the mention of thread safety also reminds me of a very popular interview question:
In fact, to put it bluntly, it is caused by dirty data caused by no real-time synchronization in memory.
Solution: one is to lock (pessimistic lock). The second is to use AtomicInteger to ensure the atomization of variables.
Reference code:
package Practise;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @ClassName Thread
* @Version 1.0
* @Author Wulc
* @Date 2022-02-12 15:30
* @Description
*/
public class MyThread {
static int count01 = 0;
static int count02 = 0;
static AtomicInteger count03 = new AtomicInteger(0);
static volatile int count04 = 0;
public static void main(String[] args) {
Runnable runnable01 = (new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
count01++;
try {
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("count01=" + count01);
}
});
Runnable runnable02 = (new Runnable() {
@Override
public synchronized void run() {
for (int i = 0; i < 100; i++) {
count02++;
try {
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("count02=" + count02);
}
});
Runnable runnable03 = (new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
count03.getAndAdd(1);
try {
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("count03=" + count03);
}
});
Runnable runnable04 = (new Runnable() {
@Override
public void run() {
for (int i = 0; i < 100; i++) {
count04++;
try {
Thread.sleep(30);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("count04=" + count04);
}
});
new Thread(runnable01).start();
new Thread(runnable01).start();
new Thread(runnable02).start();
new Thread(runnable02).start();
new Thread(runnable03).start();
new Thread(runnable03).start();
new Thread(runnable04).start();
new Thread(runnable04).start();
}
}
4. Summary
When it comes to "high concurrency", the first thing I think of is: "cache" + "queue" + "lock". However, how to organically combine the three to maximize their efficacy is a big problem, which needs to be explored and studied slowly in the future.
5. References
- Two threads execute i++100 times at the same time_ qq_35925750 blog - CSDN blog_ Two threads call i++10 cycles at the same time
- The usage of Java and the role of maratile in the youth blog
- The most complete summary of Java volatile Keywords: Principle Analysis and example explanation (easy to understand)_ Summer breeze - CSDN blog_ java volatile
- https://www.iteye.com/blog/flychao88-2269438
- Introduction to compareandswap in java Unsafe class_ sherld's column - CSDN blog_ compareandswap
- Thread safe queue for java multithreading summary_ Bieleyang's blog - CSDN blog_ java thread safe queue
- Self implementation of lockless high concurrency queue - simple book
- Blocking queue and non blocking queue_ Big drumstick blog - CSDN blog_ The difference between blocking queue and non blocking queue