The difference between HashMap in JDK1.8 and JDK1.7
conclusion
First of all, the biggest difference between HashMap in 1.7 and 1.8 is the change of underlying data structure. The underlying data structure used by HashMap in 1.7 is the form of array + Chain table, whereas in 1.8 HashMap uses the data structure of array + Chain Table + red-black tree.(When the chain length is greater than 8 and the array length is greater than or equal to 64, the chain table is converted to a red-black tree, and when the length is less than 6, the red-black tree is converted to a chain table)Red-Black Tree is a balanced binary search tree, which can maintain the balance of the tree by left-handed, right-handed and color-changing. Baidu itself is what you want to know about Red-Black Tree, which is not described here. The reason why Red-Black Tree is used is because it can greatly improve the search efficiency, the time complexity of the chain table is O(n) and the time complexity of Red-Black Tree is O(logn) So why do you want to convert a tree with a chain length greater than 8 and an array length greater than 64? Simply put, there is no need to convert the data structure when there are too few nodes, because not only converting the data structure takes time but also space. Why not use the red-black tree all the time? This is because the structure of the tree wastes too much space and only if there are enough nodesTree is the best way to show its advantages, but if there are not enough nodes, chain table is more efficient and takes less space.
How does HashMap store elements?
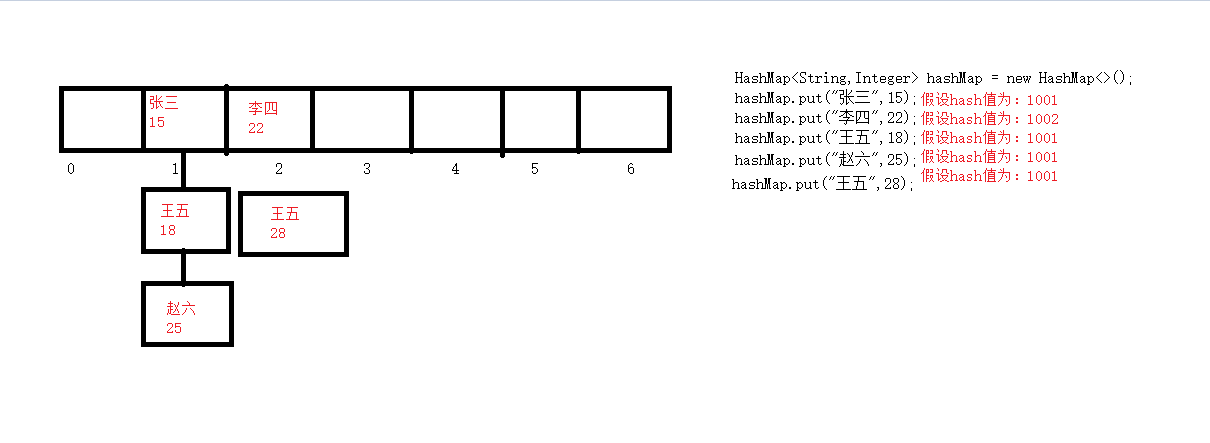
When we store data in a HashMap, we first calculate the value based on the hashCode method of the key, then combine the length of the array with algorithms (such as redundancy, bitwise operations, etc.) to calculate the index value of the location where the data is stored in the array. If there is no data in the index location, the data is placed in the index bit; if there is already data in the index location, a hash collision occurs(Two different original values get the same result after hashing)In order to resolve hash collisions, JDK1.8 used the form of array+chain table before, and JDK1.8 used the form of array+chain table+red-black tree after, for example, chain table. Since the hash value at this location is the same as the hash value of the new element, it is necessary to compare the contents of the two elements if the contents are the same, then override the operation. If the contents are different, continue to look for the next element in the chain table to compareFor example, assume that the array subscript corresponding to Zhang San, Wang Wu, Zhao Liu and Wang Wu is 1, and the array subscript corresponding to Li Si is 2. At the beginning, the index position 1 is empty, (Zhang San, 15) is placed directly in position 1, and the index position 2 is empty, (Li Si, 22) is placed directly in position 2.(Wang Wu, 18) found that index position 1 already has data, at this time call equals method and Zhang San to compare content, found that the content is different, the chain table opens up new space to store data; (Zhao Liu, 25) found that 1 location has elements, call equals and Zhang San comparison, content is different, continue to compare downward with Wang Wu, content is different, open up new space to store data;(Wang Wu, 28) Found that there are elements in 1 position. Call equals and Zhang San to compare the contents. Different, continue to compare down and (Wang Wu, 18) and find that the contents are the same. At this time, the overwrite operation will change the original (Wang Wu, 18) to (Wang Wu, 28).
Introduction to HashMap
1.HashMap hashMap = new HashMap();
When creating a HashMap collection object, before JDK8, an Entry[]table of 16 length was created in the construction method to store the key-value pair data. After JDK8, instead of creating an array in the HashMap construction method, an array Node[] table was created the first time the put method was called to store the key-value pair data.
Introduction to initial capacity size
When it comes to arrays, you have to mention that the member variable DEFAULT_INITIAL_CAPACITY in HashMap is also the capacity size. If not specified, it defaults to 16. If the container size is specified by a parametric construction, it must also be the square of 2, of course, if the parameter passed in is not the square of 2.(Better not, I don't really know how much capacity to write. We'll just write a default size of 16)HashMap changes it to a larger number than this and closest to the square of 2, for example, by passing in 11 it will become 16. The reason for this is that, as we know from the explanations above, when you add an element to HashMap, you need to determine its specific location in the array based on the hash value of the key. HashMap is efficient in accessing and reducing collisions.Collision means to distribute the data as evenly as possible, with each list having approximately the same length. The key to this implementation is the algorithm in which the data is stored. This algorithm is actually a modulus, hash% length, and the direct remainder in the computer is not as efficient as the displacement operation. So the source code is optimized to use hash & (length - 1), whereas hash% length is actually equal to hash &(length - 1) assumes that length is the nth power of 2.
As mentioned above, if the incoming specified size is not the n-power of 2, HashMap will change the size to a number greater than the specified size and equal to the n-power of 2. Let's see how JDK1.7 and JDK1.8 do this.
JDK1.7
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
// Move left continuously from the beginning, that is, to the n-th power of 2, until it is no smaller than the specified capacity
// 1 2 4 8 16 32.. . .
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
JDK1.8
// Assume cap is 13
static final int tableSizeFor(int cap) {
// The n=12 int type accounts for 4 bytes in memory, and one byte for 8 bits
int n = cap - 1;
/*
* 00000000 00000000 00000000 00001100 12
* 00000000 00000000 00000000 00000110 Move 1 Bit Right
* ---------------------------------------------- Or operation
* 00000000 00000000 00000000 00001110 14
*/
n |= n >>> 1; // n=14
/*
* 00000000 00000000 00000000 00001110 12
* 00000000 00000000 00000000 00000111 2 Bits Right
* ---------------------------------------------- Or operation
* 00000000 00000000 00000000 00001111 15
*/
n |= n >>> 2;//Calculate n=15
/*
* 00000000 00000000 00000000 00001111 15
* 00000000 00000000 00000000 00000000 Right Shift 4 Bits
* ---------------------------------------------- Or operation
* 00000000 00000000 00000000 00001111 15
*/
n |= n >>> 4;// Calculate n=15
/*
* 00000000 00000000 00000000 00001111 15
* 00000000 00000000 00000000 00000000 Move 8 Bits Right
* ---------------------------------------------- Or operation
* 00000000 00000000 00000000 00001111 15
*/
n |= n >>> 8;// Calculate n=15
/*
* 00000000 00000000 00000000 00001111 15
* 00000000 00000000 00000000 00000000 Right Shift 16 Bits
* ---------------------------------------------- Or operation
* 00000000 00000000 00000000 00001111 15
*/
n |= n >>> 16;// Calculate n=15
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
JDK1.8 simply means that the highest non-zero bits are all set to 1 after the bitwise operation. From the above five calculations, you can see that the final result can just fill the space of 32 bits, that is, a space of type int. This is why it must be of type int and only move 16 bits to the right unsigned at most. So why do you subtract 1 when it comes in?In order that when the parameter passed in happens to be the N-power of 2, the result is the smallest N-power that is larger than the value passed in. For example, if exactly 16 is passed in and not subtracted by one, the result will be 64, which does not match what we want. Therefore, subtracting one when passing in will prevent the result from being wrong because it happens to be the n-power.Calculate, so you can understand.
Load factor and threshold
Load factor static final float DEFAULT_LOAD_FACTOR = 0.75f and threshold int threshold s are used for map expansion judgment, and load factor can also be specified in the constructor (not recommended)For each put, it will be judged whether the expansion is needed. When the size exceeds the threshold = total capacity * load factor, the expansion will occur. By default, the total capacity is 16 and the load factor is 0.75. For what is 0.75, this is because a lot of experiments have proved that the coefficient is most appropriate. If set too small, HashMap put will expand once for every small amount of data.If set too large, if set to 1, capacity or 16, assuming that 15 of the arrays are already occupied, and then put data in, the probability of hash collisions will reach 15/16 when the array index is calculated, which violates the principle of HashMap to reduce hash collisions.
HashMap construction method
Parameterless construction methods in JDK1.7:
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
// Load factor
this.loadFactor = DEFAULT_LOAD_FACTOR;
// Threshold: Total capacity * Load factor
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// Store entry for key-value pairs
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
Construction methods in JDK1.8:
public HashMap() {
// Setting the load factor to the default of 0.75f does not create an array of Entry s in the construction method, but puts them into the put method
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity, float loadFactor) {
// Is the initial size given less than 0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// Whether the maximum capacity is exceeded or not, if yes, the maximum capacity is directly assigned
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// Is the factor given a number greater than 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Set the size of the load factor
this.loadFactor = loadFactor;
// Adjust the size of a given array
this.threshold = tableSizeFor(initialCapacity);
}
this.threshold = tableSizeFor(initialCapacity);Determine if the specified initialization capacity is the n-power of 2, or if it is not, it will become the smallest n-power of 2 that is larger than the specified initialization capacity. Note, however, that the calculated data is returned to the call inside the tableSizeFormethod and is directly assigned to the threshold boundary value. Some people will think this is a bug and should write as follows: this.threshold =TableSizeFor (initialCapacity) * this.loadFactor;This is what thresholds mean (expanded when HashMap's size reaches the threshold of thresholds). Note, however, that in construction methods after jdk8, the member variable table is not initialized, table initialization is deferred to the put method, and thresholds are recalculated in the put method.
put method in JDK1.8
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
.......
// Node holding key-value pairs
Node<K,V>[] tab;
.......
}
PuVal (hash(key), key, value, false, true) is also called in the put method;And the hash(key) method, let's first look at the hash(key) method
static final int hash(Object key) {
int h;
// hash value is 0 if key is null
//(h = key.hashCode()) ^ (h >>> 16)
// Get the hashCode of the key and assign it to h, then move it 16 bits to the right with H and h, then do XOR to get the hash value
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Here is a step (h=key.hashCode()) ^ (h >>> 16), why do you want to get hashCode() after assigning it to h and do exclusive OR with H shifting 16 bits to the right? Let H = key.hashCode()No? Actually, this is to avoid hash conflicts as much as possible when putting. As mentioned earlier, looking for array subscripts when storing elements is actually a hash value that balances the length of the array, (n - 1) when the length of the array is n powers of 2.& hash and hash%n are equivalent and more efficient than the remainder. Simply put, this is because a XOR is made at 16 bits high, 16 bits low and 16 bits high (the resulting hashCode is converted to 32-bit binary, and a XOR is made at 16 bits low and 16 bits high)You can see from the calculation below that it does understand a little deeply, but this is also a powerful point.
Assume: Array size n=16=0000 0000 0000 0000 0000 0000 0001 0000 1.hypothesis hash Direct and h Equal call hashCode()Method h=h.hashCode(): h=h.hashCode()=1111 1111 1111 1111 1111 0000 1110 1010 hash=1111 1111 1111 1111 1111 0000 1110 1010 Calculate array subscripts:(n-1)&hash (n-1):0000 0000 0000 0000 0000 0000 0000 1111 hash: 1111 1111 1111 1111 1111 0000 1110 1010 --------------------------------------------- (n-1)&hash=0000 0000 0000 0000 0000 0000 0000 1010=10 We see that only the last four bits actually participate in the operation, that is, the other high bits are not involved in the operation Then there's a situation where you call hashCode()The value highs obtained by the method are constantly changing but No change in status will result(n-1)&hash The results will be consistent, resulting in hash Conflict. 2.hypothesis hash = h^(h>>>16): call hashCode()Method h=h.hashCode(): h=h.hashCode()=1111 1111 1111 1111 1111 0000 1110 1010 (h>>>16): 0000 0000 0000 0000 1111 1111 1111 1111 hash = h^(h>>>16): 1111 1111 1111 1111 0000 1111 0001 0101 Calculate array subscripts:(n-1)&hash (n-1):0000 0000 0000 0000 0000 0000 0000 1111 hash:1111 1111 1111 1111 0000 1111 0001 0101 ------------------------------------------------ (n-1)&hash=0000 0000 0000 0000 0000 0000 0000 0101=5 Simply put, by moving 16 bits to the right, and by XOR operations, all the high places are involved in the operation as little as possible hash conflict
Next, look at the putVal method
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
/*
Node<K,V>[] tab: Array holding elements
Node<K,V> p: The element used to hold the index position
int n: n Length used to record arrays
int i: i Location used to record the index
*/
Node<K,V>[] tab; Node<K,V> p; int n, i;
/*
1.table: transient Node<K,V>[] table; Array holding elements
2.(tab = table) == null Assign table to tab and determine if NULL must be null for the first put
3.(n = tab.length) == 0 Assign the length of the array to n and determine if it is 0
*/
if ((tab = table) == null || (n = tab.length) == 0)
// Tab is null or tab length is 0 for expansion
n = (tab = resize()).length;
/*
(n - 1) & hash: Previously, when n is the n-th power of 2, this operation is equivalent to hash%n, where the hash value balances the length of the array
i = (n - 1) & hash: Array index subscripts holding elements
If no element exists at the index position, a new node is created at the index position
p is assigned here, p is null if no element exists
*/
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
/* Executing else indicates that tab[i] is not equal to null, indicating that the location already has a value
Node<K,V> e: Nodes that hold data
K k: Save key
*/
Node<K,V> e; K k;
/*
1.p.hash == hash: p Hash value==incoming hash value
2.(k = p.key) == key: Assign the key of p to k ==present key
3.key != null && key.equals(k))): key Not Empty &key has the same content as the current key
If both 1, 2 or 3 are satisfied, then the p-node is assigned to e
*/
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
/*
Determine whether p is a red-black tree node
*/
else if (p instanceof TreeNode)
/*
Insert a node into the tree and assign it to e
*/
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
/*
binCount: Record the number of traversed nodes
*/
for (int binCount = 0; ; ++binCount) {
/*
1)e = p.next Gets the next element of p and assigns it to e.
2)(e = p.next) == null Determining whether p.next equals null or not means that P has no next element.
Then the end of the list is reached and no duplicate key has been found, indicating that HashMap does not contain the key and inserts the key-value pair into the list.
*/
if ((e = p.next) == null) {
/*
Last node, so next is null
JDK8 New nodes with tail interpolation, before JDK8 head interpolation
*/
p.next = newNode(hash, key, value, null);
/*
Determine if you want to convert to a red-black tree
binCount Self-increasing from 0, when binCount = 7 there are already 8 nodes
Add the node you just inserted so there are nine, so when the chain length is longer than 8, it turns into a red-black tree
*/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// Turn into a mahogany tree
treeifyBin(tab, hash);
break;
}
/*
Execute here to indicate that e = p.next is not null, not the last element. Continue to determine if the key value of the node in the chain table is equal to the key value of the inserted element.
*/
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// Equal, out of cycle
break;
// Assign e to p to continue looking for the next node
p = e;
}
}
/*
If e!=null indicates that duplicate key s were found through a series of operations above, so
This is to replace the old key value with the new value and return the old value
*/
if (e != null) { // existing mapping for key
// Get old values
V oldValue = e.value;
// onlyIfAbsent is false or oldValue is null
if (!onlyIfAbsent || oldValue == null)
// Save new values
e.value = value;
// Callback after access, point in will find an empty method to inherit the LinkedHashMap class service of HashMap
afterNodeAccess(e);
// Return Old Value
return oldValue;
}
}
// This variable is used to record the number of modifications
++modCount;
// Determine if the size of the new element is larger than the threshold and, if so, expand it
if (++size > threshold)
resize();
// Callback after insertion, point in will find an empty method to inherit the LinkedHashMap class service of HashMap
afterNodeInsertion(evict);
return null;
}
_u treeifyBin() u Method for Converting to Red-Black Tree
/**
* Turn into a mahogany tree
* @param tab
* @param hash
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
/*
Expansion if array tab is not empty or array length is less than 64
n = tab.length:Array length is assigned to n
*/
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
/*
Convert to Black and Red Tree Operation
e = tab[index = (n - 1) & hash]): Get Index Location Element
*/
else if ((e = tab[index = (n - 1) & hash]) != null) {
/*
hd: Store the tree's head node
tl: Used to store temporary nodes
*/
TreeNode<K,V> hd = null, tl = null;
do {
// Convert a list node to a tree node
TreeNode<K,V> p = replacementTreeNode(e, null);
/*
tl: First temporary node must be empty
Assigning p nodes to header nodes
*/
if (tl == null)
hd = p;
else {
/*
Temporary tl node is not empty:
p.prev = tl: Assign tl to the prev node of p
tl.next = p: Assign p node to next node of tl
*/
p.prev = tl;
tl.next = p;
}
// Assign p node to tl node
tl = p;
} while ((e = e.next) != null); // Loop until Next node does not exist
/*
(tab[index] = hd): Assign the tree's head node to the array index position
*/
if ((tab[index] = hd) != null)
/*
What to do to turn into a red-black tree
*/
hd.treeify(tab);
}
}
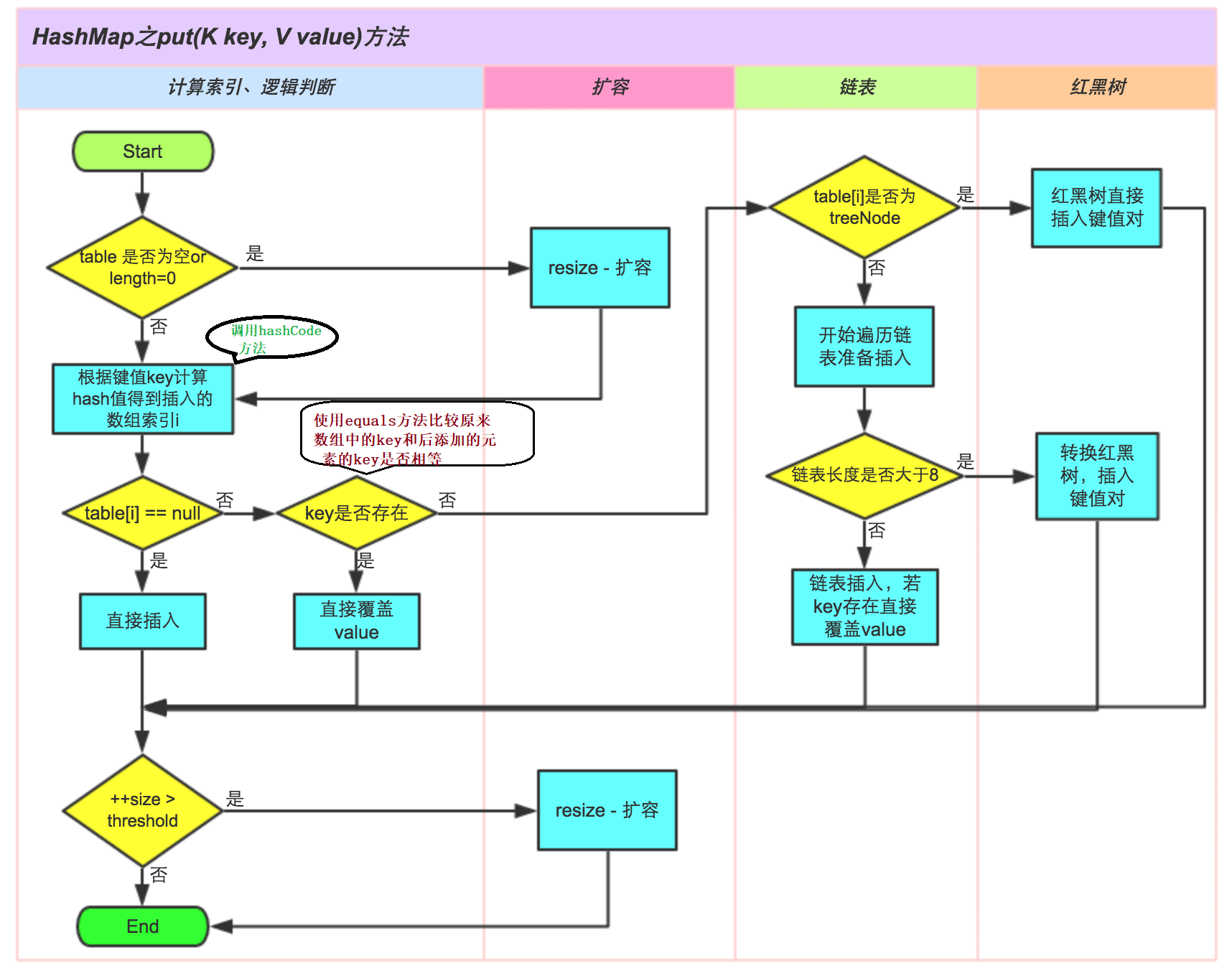
Explain
- The size represents the real-time number of key-value pairs in HashMap, which is not equal to the length of the array
- threshold = capacity * loadFactor. This is the maximum length of the array that is currently occupied. When size exceeds this value, the HashMap capacity is resize d again, double that of the previous capacity.
put method in JDK1.7
public V put(K key, V value) {
/*
If Key is null, call the putForNullKey method
putForNullKey: Add if there is no Entry with null as key, replace the original value and return if it exists
*/
if (key == null)
return putForNullKey(value);
/*
key.hashCode(): Call hashCode() of key to get hashCode
hash(key.hashCode()):Get hash value by calling hash method
This operation is actually similar to the hash(key) of the HashMap of JDK1.8, which also allows high and low levels to participate
hash Computing to avoid hash conflicts, you can refer to the HashMap above for JDK1.8
*/
int hash = hash(key.hashCode());
/*
This step calculates the index subscript of the array
Calculating method is the same as JDK8
*/
int i = indexFor(hash, table.length);
/*
Entry<K,V> e = table[i]: Assign elements corresponding to index subscripts to Entry
This step actually traverses the list to find elements
*/
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
/*
e The hash value of the same and the hash value of the new element are the same, which means the key is the same
Replace the old value in the node with the new value and return the old value
*/
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// This variable is used to record the number of modifications
modCount++;
// To illustrate that there are no key duplicate elements, add elements
addEntry(hash, key, value, i);
return null;
}
addEntry method for new elements
void addEntry(int hash, K key, V value, int bucketIndex) {
/*
Get the Entry of the index location
*/
Entry<K,V> e = table[bucketIndex];
/*
Inserting elements into a chain table using header interpolation
Assign e to next after inserting a new node
*/
table[bucketIndex] = new Entry<>(hash, key, value, e);
// Determine if the size of the array exceeds the threshold after adding an element
if (size++ >= threshold)
// Expansion method, which will expand to twice the size of the original array
resize(2 * table.length);
}
Expansion method resize()
When HashMap expands, it is twice the size of the original array each time it expands, and then assigns the elements in the original array to the new array. How does HashMap allocate them? Since each expansion is twice the size of the original, the table subscript is calculated by hash & (newTable.length-1), which is hash & (oldTable.length*2-1)So we conclude that if the old and new subscripts are calculated twice, they will either be the same or they will be equal to the old subscripts plus the length of the old array.
Old Array Length: n=16 n: 0000 0000 0000 0000 0000 0000 0001 0000 n-1: 0000 0000 0000 0000 0000 0000 0000 1111 Suppose you have two elements hash Value is: hash1: 1111 1111 1111 1111 0000 1111 0000 0101 hash2: 1111 1111 1111 1111 0000 1111 0001 0101 Calculate two hash Index position of corresponding array:(n-1)*hash index1: 0000 0000 0000 0000 0000 0000 0000 0101 index2: 0000 0000 0000 0000 0000 0000 0000 0101 In the original array hash1 and hash2 By calculating the corresponding array index positions are all 5(0101) ================================================================ New expanded array: n=2*n=32 n: 0000 0000 0000 0000 0000 0000 0010 0000 n-1: 0000 0000 0000 0000 0000 0000 0001 1111 The element is also the previous element, that is to say hash Or before hash: hash1: 1111 1111 1111 1111 0000 1111 0000 0101 hash2: 1111 1111 1111 1111 0000 1111 0001 0101 Calculate two hash Index position of corresponding array:(n-1)*hash index1: 0000 0000 0000 0000 0000 0000 0000 0101(5) index2: 0000 0000 0000 0000 0000 0000 0001 0101(21) As a result, the two elements placed in the same index position in the original array are resized After allocation, hash1 The calculated index position is also the position in the original array. hash2 Calculated cable Quote position is the position in the original array+Original Array Length
In fact, if the new array subscript corresponding to the hash value needs to add the length of the old array, just check if the hash value-the old array length (hash&oldTable.length) is 1. If it is 1, it is the position in the original array + the length of the original array, and if it is 0, it is the position in the original array.
Extension Methods in JDK1.7
void resize(int newCapacity) {
// Get Source Array
Entry[] oldTable = table;
// Original Array Capacity Size
int oldCapacity = oldTable.length;
// Determine if the original capacity is already the maximum
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// The new array size is twice the size of the original array
Entry[] newTable = new Entry[newCapacity];
/*
Key to the expansion method, recalculating index allocation locations
*/
transfer(newTable);
// New Array Replace Original Array
table = newTable;
// New Threshold
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
// Source Array
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
// Assigning an element to e
Entry<K,V> e = src[j];
if (e != null) {
// null elements in original position for GC convenience
src[j] = null;
do {
Entry<K,V> next = e.next;
// Recalculate the position of elements in the new array
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
static int indexFor(int h, int length) {
return h & (length-1);
}
Expansion Method in JDK1.8
final Node<K, V>[] resize() {
// Source Array
Node<K, V>[] oldTab = table;
// Original Array Capacity
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// Threshold of original array
int oldThr = threshold;
/*
newCap: Capacity of the new array, initial value 0
newThr: Threshold for new array, initial value is 0
*/
int newCap, newThr = 0;
// Determine if the original array size is not zero
if (oldCap > 0) {
/*
The capacity of the original array is already greater than or equal to the maximum capacity
Assign the maximum value to the original threshold and return to the original array
*/
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
/*
(newCap = oldCap << 1): Move the original array one bit to the left, that is, double the original size and assign it to the new capacity newCap
The threshold is increased if the new capacity is less than the maximum capacity and the original array capacity is greater than the default initial capacity of 16
*/
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// Double the threshold
newThr = oldThr << 1; // double threshold
}
/*
The original threshold greater than 0 is assigned to the new capacity
There may be a question here as to why the original array threshold size should be assigned to the new capacity?
Looking at the parametric construction method in the previous JDK1.8, you can see that,
The calculated data is directly assigned to the threshold boundary value inside the tableSizeFor method body
*/
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
/*
Entering else means that the capacity and threshold of the original array are both 0, then initialization default is made
newCap: Assignment Initial Value 16
newThr: New threshold=0.75*16=12
*/
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
/*
New threshold or initial value 0 calculates new threshold
*/
if (newThr == 0) {
// ft = new capacity * load factor
float ft = (float) newCap * loadFactor;
// If the new array capacity does not exceed the maximum and FT is less than the maximum, then ft is taken as the new threshold.
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?
(int) ft : Integer.MAX_VALUE);
}
// Assigning a new threshold to the member variable threshold
threshold = newThr;
// Create a new length array newTab
@SuppressWarnings({"rawtypes", "unchecked"})
Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap];
// Assigning a new array to a member variable table
table = newTab;
if (oldTab != null) {
// Traverse through the original array and put the data into a new array
for (int j = 0; j < oldCap; ++j) {
// Used to save elements in traversal
Node<K, V> e;
if ((e = oldTab[j]) != null) {
/*
After assigning an element of the index position in the original array to e, null the element of the index position for GC convenience
*/
oldTab[j] = null;
/*
Determine if the array has the next reference, and if e.next is empty it means it's not a list of chains, just place the element in the array
*/
if (e.next == null)
/*
Place the primitives in the original array into the new array
e.hash & (newCap - 1): This step is to calculate the index position of the element in the new array
*/
newTab[e.hash & (newCap - 1)] = e;
/*
Determine if it's a red-black tree
*/
else if (e instanceof TreeNode)
// If the description is a red-black tree, the related method is called to process it
((TreeNode<K, V>) e).split(this, newTab, j, oldCap);
else {
/*
To else it means a list of chains
loHead: Chain header with subscript unchanged
loTail: End of chain with subscript unchanged
hiHead: Chain Header with Subscript Change
hiTail: End of chain with subscript change
*/
Node<K, V> loHead = null, loTail = null;
Node<K, V> hiHead = null, hiTail = null;
Node<K, V> next;
do {
// Assign the next node of e to the next variable
next = e.next;
// This is to determine if the node equal to true does not need to be moved after resize, that is, the corresponding array subscript remains unchanged, that is, whether the new index position = the length of the original array + the position of the original array
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
} else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);// Assign next to e and continue looping until next is empty
// Place original index in array
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// Place the original index + oldCap in the array
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
The latter remove and get methods are relatively easy. The following are examples of JDK8, you can see the source code comparison for yourself.
Delete method remove()
The deletion method is to find the location of the element first, and then delete it after traversing the chain table to find the element if it is a chain table. If it is a red-black tree, it traverses the tree and deletes it after it is found. When the tree is less than 6, it needs to go to the chain table.
Find element method get()
Mainly the getNode method
public V get(Object key) {
Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K, V> getNode(int hash, Object key) {
// Save Array
Node<K, V>[] tab;
// first: save the header node e: save the next node
Node<K, V> first, e;
// Save Array Length
int n;
// Save key value
K k;
/*
tab = table: Assigning an array to a tab
n = tab.length: Record Array Length
first = tab[(n - 1) & hash]: Assign the element in the index position corresponding to the key to first
*/
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// Determine if the header node is the element to find, and return directly if it is
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
/*
Assign next node to e
*/
if ((e = first.next) != null) {
/*
To determine if it is a red-black tree node, if it is, find the node from the tree and return the data
*/
if (first instanceof TreeNode)
return ((TreeNode<K, V>) first).getTreeNode(hash, key);
/*
Traverse the list of chains to find data and return
*/
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Several ways to traverse HashMap
public static void main(String[] args){
HashMap<String,Integer> hashMap = new HashMap<>(16);
hashMap.put("Kobe",36);
hashMap.put("Wade",23);
hashMap.put("James",38);
hashMap.put("Anthony",30);
hashMap.put("Paul",25);
// Traverse key and values, respectively
iteratorMap_1(hashMap);
// Traversing using an iterator
iteratorMap_2(hashMap);
// By get
iteratorMap_3(hashMap);
// Via lambda
iteratorMap_4(hashMap);
}
1. Traverse key and value, respectively (not commonly used)
/**
* Traverse key and values, respectively
* @param hashMap
*/
private static void iteratorMap_1(HashMap<String, Integer> hashMap) {
for (String key : hashMap.keySet()) {
System.out.println(key);
}
for (Integer value : hashMap.values()) {
System.out.println(value);
}
}
2. Iterate through iterators (recommended)
/**
* Traversing using an iterator
* @param hashMap
*/
private static void iteratorMap_2(HashMap<String, Integer> hashMap) {
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey()+"=====>"+entry.getValue());
}
}
3. By get (not recommended)
According to the Ali Development Manual, this is not recommended because of two iterations. KeSet takes Iterator once and iterates again through get, which reduces performance.
/**
* By get
* @param hashMap
*/
private static void iteratorMap_3(HashMap<String, Integer> hashMap) {
for (String key : hashMap.keySet()) {
Integer value = hashMap.get(key);
System.out.println(key+"=====>"+value);
}
}
4. Traverse using lambda expressions (recommended)
/**
* Through lambda
* @param hashMap
*/
private static void iteratorMap_4(HashMap<String, Integer> hashMap) {
hashMap.forEach((key,value)->System.out.println(key+"=====>"+value));
}
How to set the correct initial capacity for HashMap

As we mentioned above, the extension mechanism of HashMap is to expand when the expansion condition is reached. The extension condition of HashMap is when the number of elements (size) in HashMap exceeds the threshold value.So if we don't set the initial capacity size, HashMap may expand several times as the elements increase, and the expansion mechanism in HashMap determines that hash needs to be rebuilt for each expansionTables, for example, have seven elements to store, we set the initial capacity to 7, which will be set to 8 by HashMap, but we know that when the number of elements exceeds 8*0.75=6, there will be an expansion, which means that the initial capacity 7 we set is actually wrong.
So initializing capacity can also affect performance depending on the number of values set, so how good is the capacity set when we know the number of Key s and Value s that will be stored in HashMap?
About setting the initial capacity size of HashMap: It can be thought that setting the default capacity to initialCapacity/ 0.75F + 1.0F is a relatively good performance option when we know exactly how many elements there are in HashMap, but it also sacrifices some memory. Jdk Instead of directly using the number passed in by the user as the default capacity, a calculation will be performed to get a power of 2 to n. Agree to take 7 for example, 7/0.75+1=10, our incoming 10 will be processed by HashMap to give a HashMap of 16 size, which will avoid frequent expansion, but will waste some space.