Operation ①
1. Experimental contents
- requirement:
- Master Selenium to find HTML elements, crawl Ajax web page data, wait for HTML elements, etc.
- Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
- Candidate sites: http://www.jd.com/
- Key words: Students' free choice
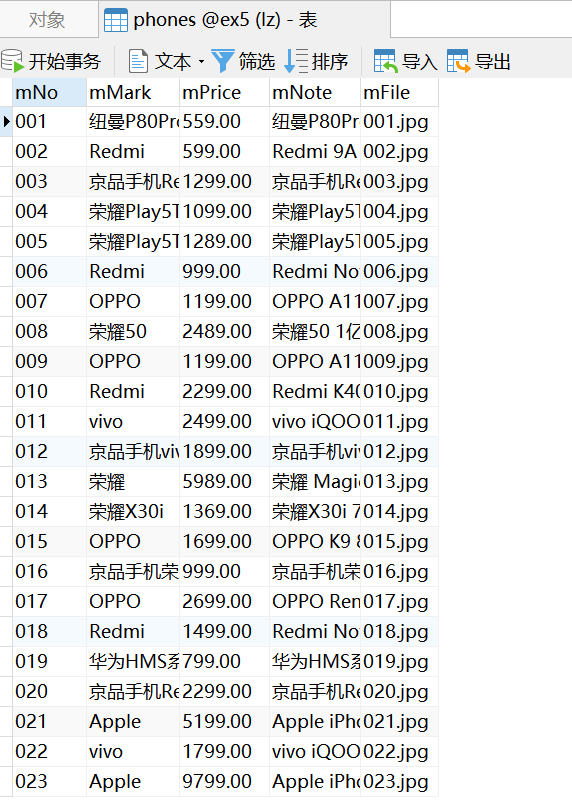
- Output information: the output information of MySQL is as follows.
| mNo | mMark | mPrice | mNote | mFile |
|---|---|---|---|---|
| 000001 | Samsung Galaxy | 9199.00 | Samsung Galaxy Note20 Ultra 5G | 000001.jpg |
| 000002...... |
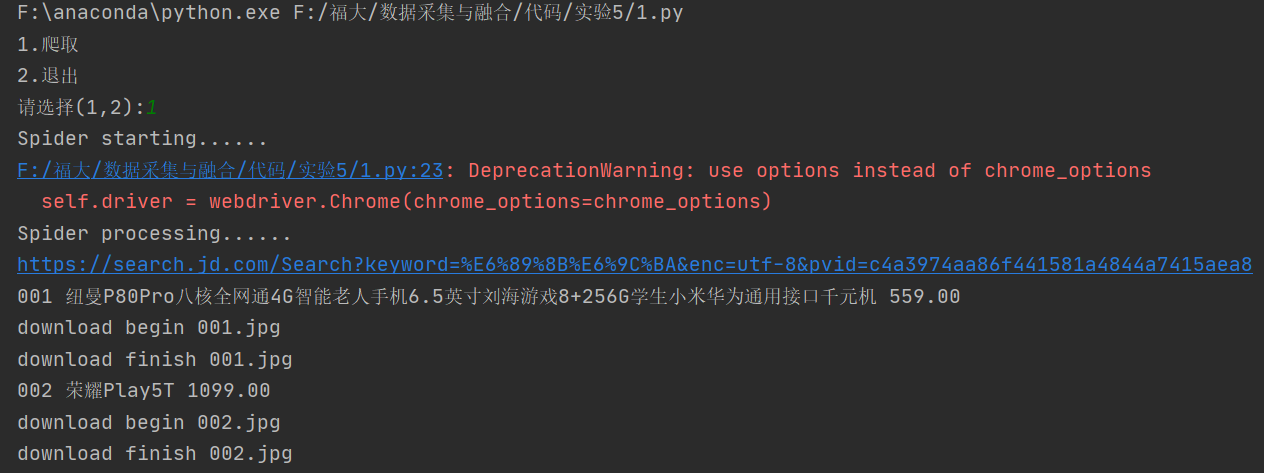
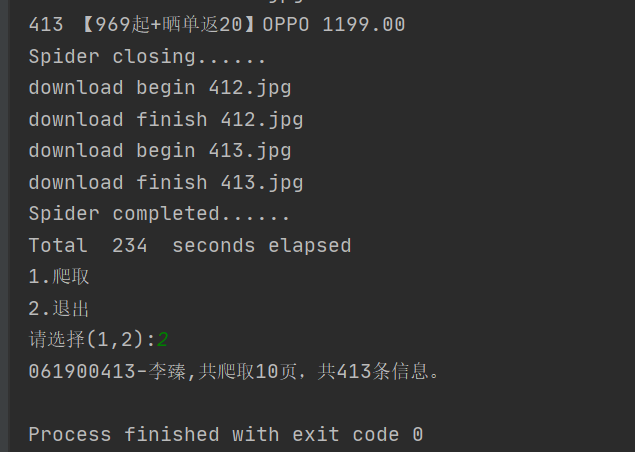
- Screenshot of operation results: (there are many operation results, and only some information is intercepted)
Screenshot of console:
Database screenshot:

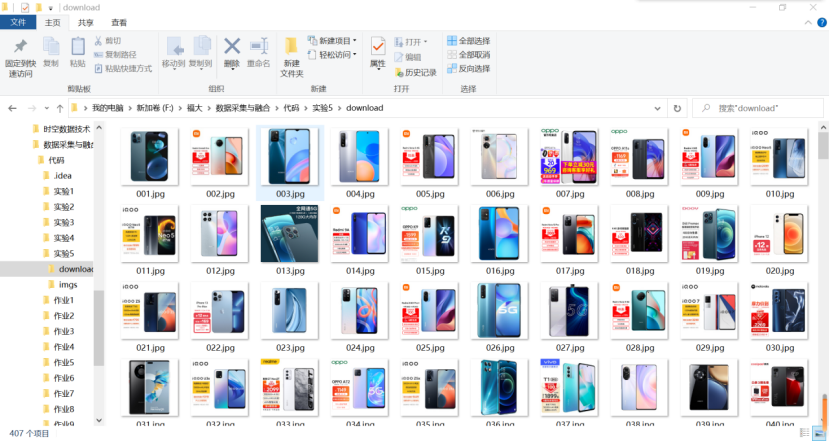
Folder screenshot:
2. Experience
(1) This topic is the reproduction of Selenium instance, which takes mobile phone as the keyword and 413 pairs of total data to crawl and page turn the website.
(2) Establish a connection with Chrome
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
(3) Establish database links and create tables
try:#Connect to database
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",passwd="123456", db="ex5", charset="utf8")
self.cursor = self.con.cursor()
try:
# If there are tables, delete them
self.cursor.execute("drop table phones")
except:
pass
try: #Create a table and set mNo as the primary key
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
(4) Create a folder to store downloaded pictures
try: #Create a folder for downloading pictures
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
(5) Visit the web page to check the elements of the input keywords
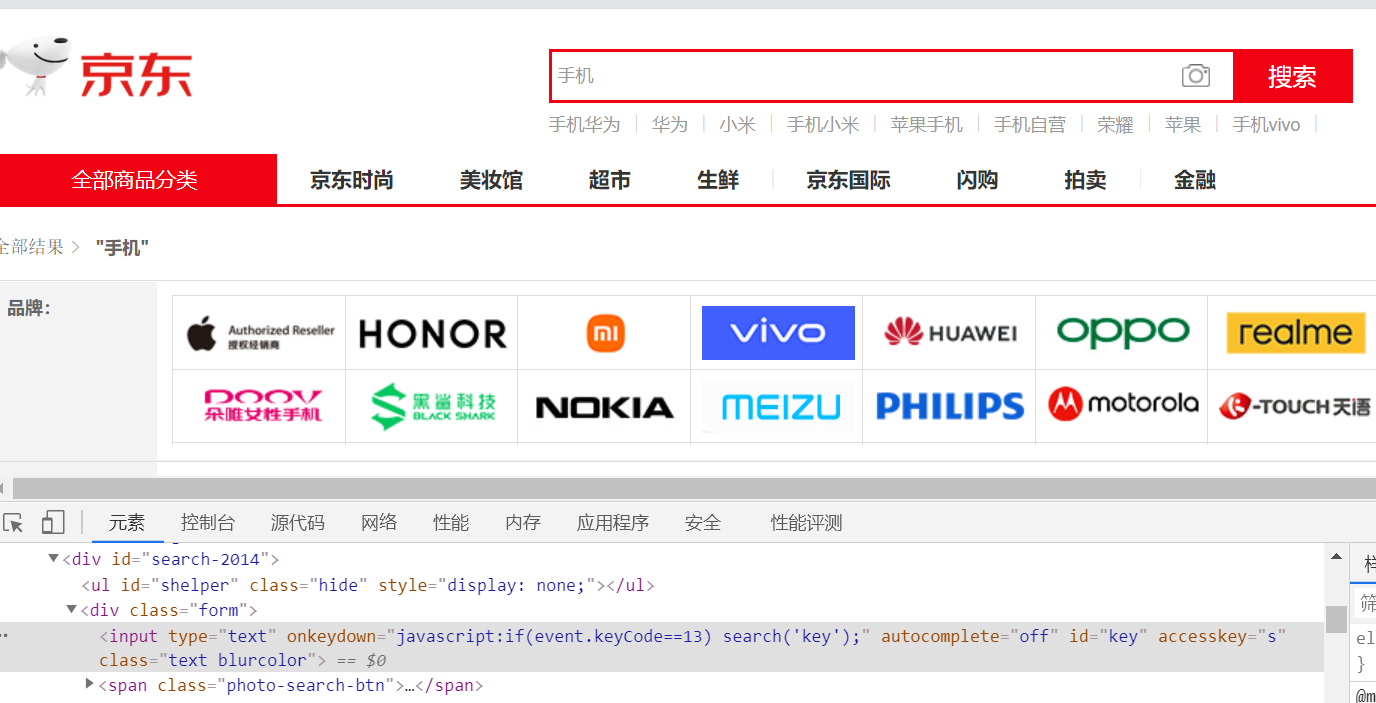
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
(6) Checking the network element, we can find that each data is contained in the li tag attribute class="gl- item" under the div tag attribute id="J_goodsList"
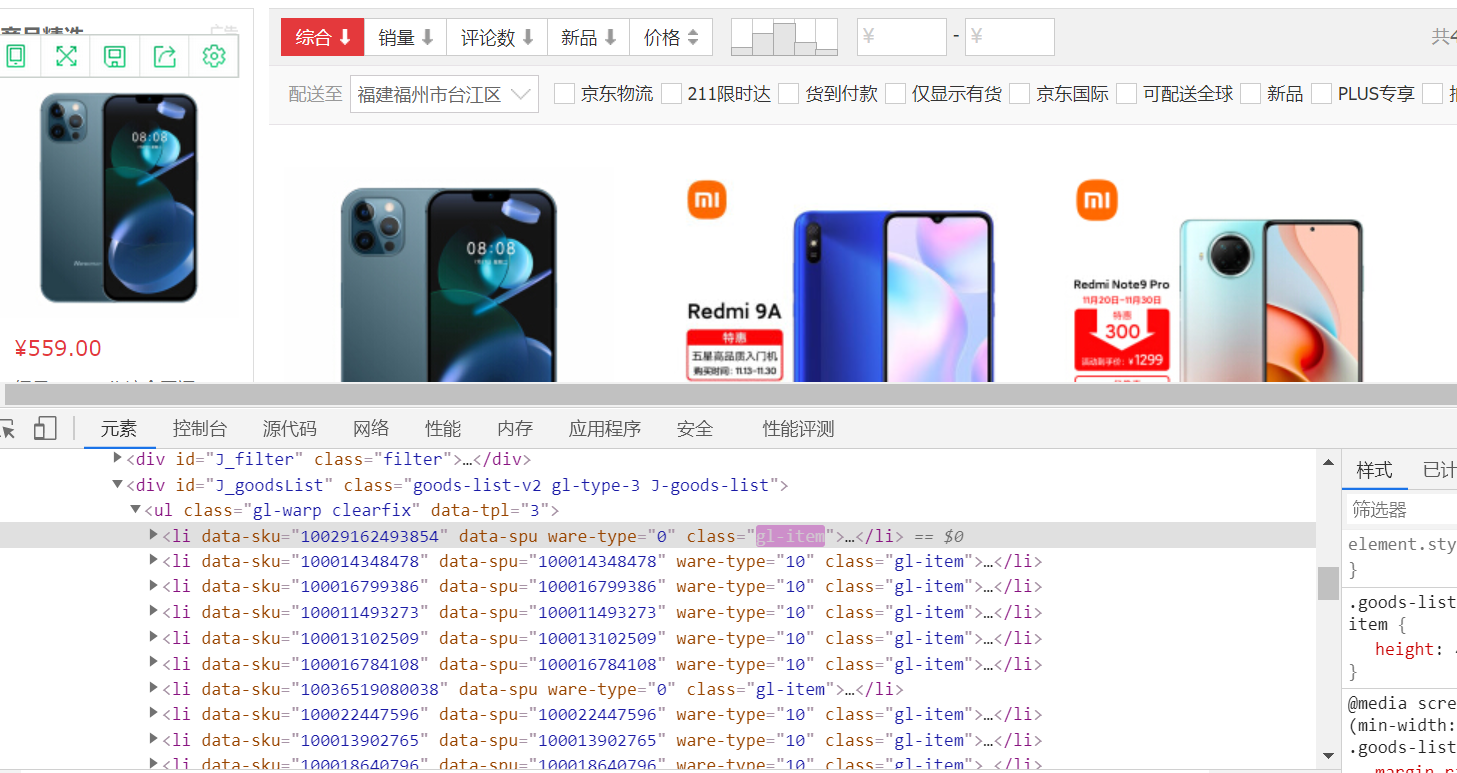
Use xpath to find all the data, and then use the loop to get the elements in each li tag pair. The data of each mobile phone is further crawled from the li object. Due to the large amount of picture data, multi thread is used to set the downloaded picture as the foreground thread.
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
if MySpider.No < 413:
MySpider.No += 1
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("Love Dongdong\n", "")
mark = mark.replace(",", "")
note = note.replace("Love Dongdong\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
no = str(MySpider.No)
while len(no) < 3:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
(7) Check the network elements and find the hyperlinks related to page turning

It can be found that as long as you find and then find the hyperlink of "next page", the hyperlink is when the page can be turned normally
- https://www.icourse163.org
- Output information: MYSQL database storage and output format
The header should be named in English, for example: course number ID, course name: cCourse... The header should be defined and designed by students themselves:
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python web crawler and information extraction | Beijing University of Technology | 3 / 18 class hours learned | Completed on May 18, 2021 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
- Screenshot of operation results:
Screenshot of console:
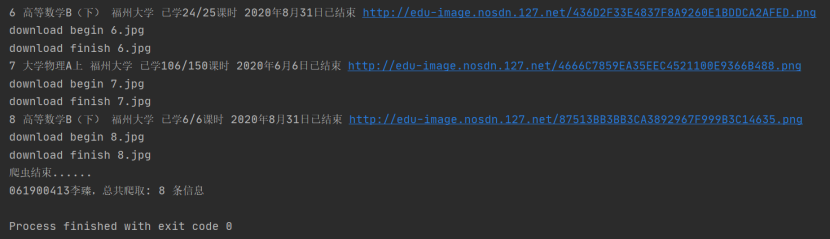
Database screenshot:
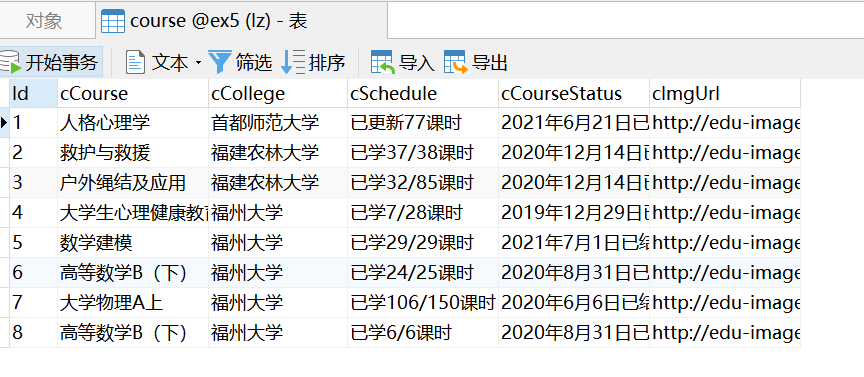
Folder screenshot:
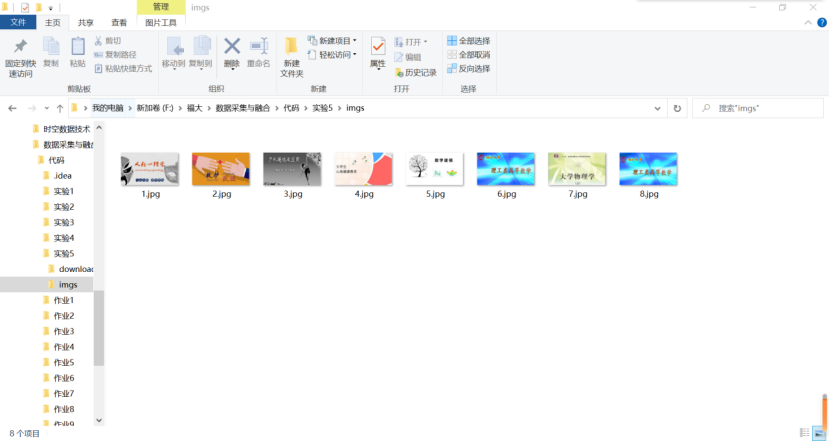
2. Experience
(1) Because the anti pickpocketing mechanism of Chinese universities is strong, they only crawl the data in their own personal center.
(2) Open the login interface of China University Mu class to check the elements
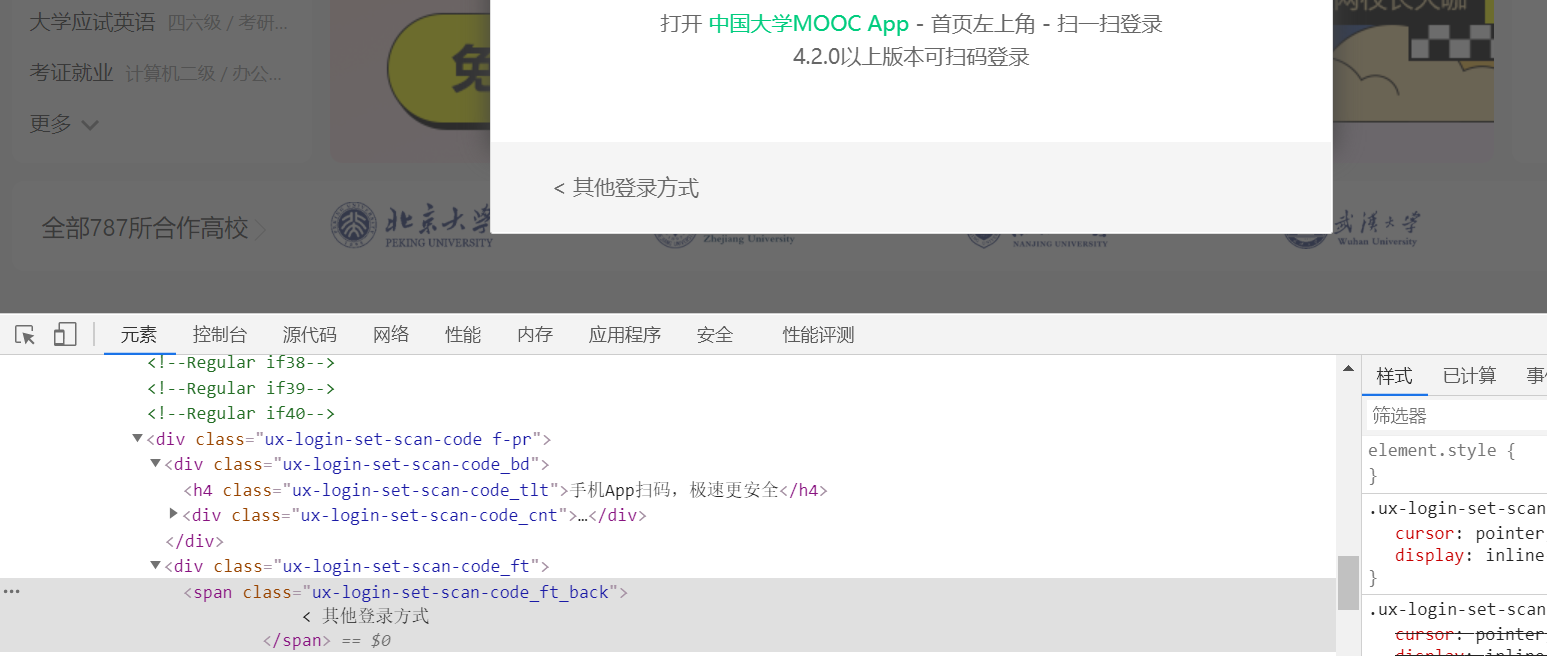
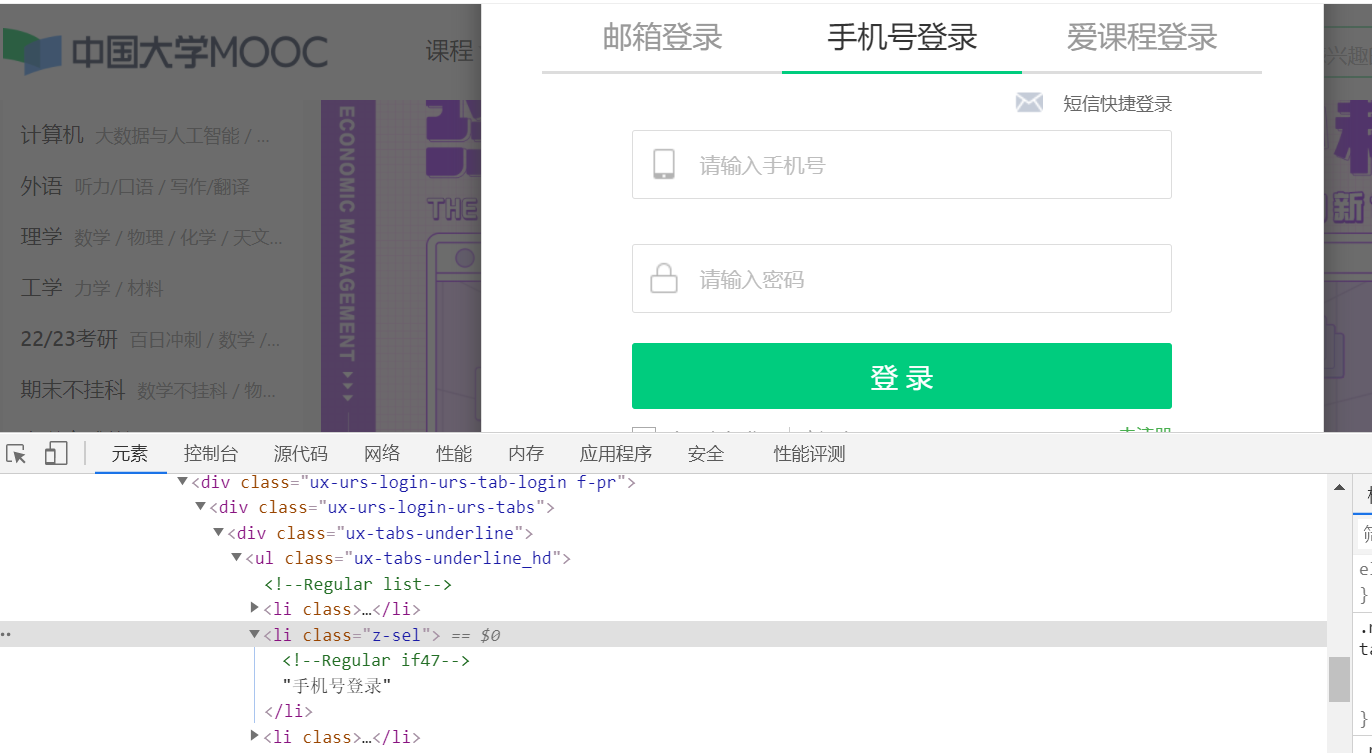
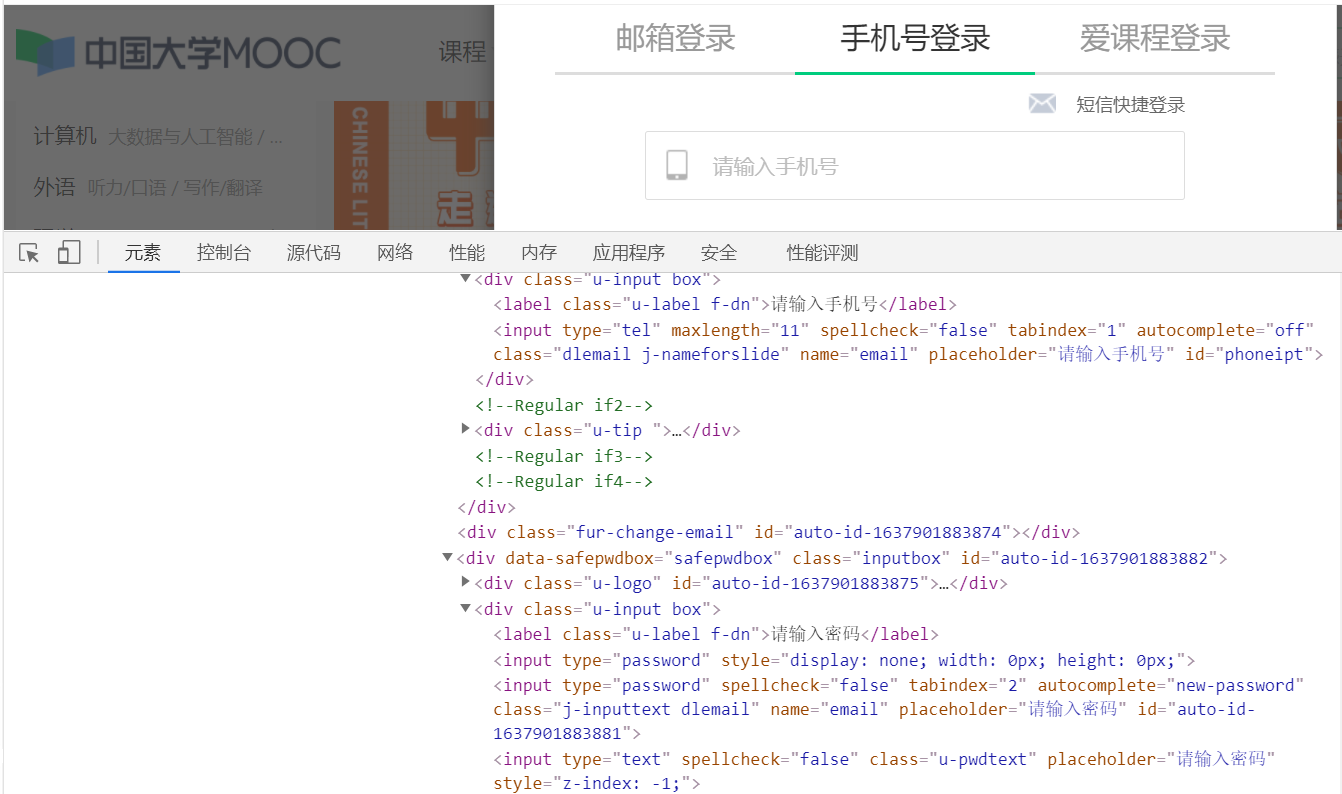
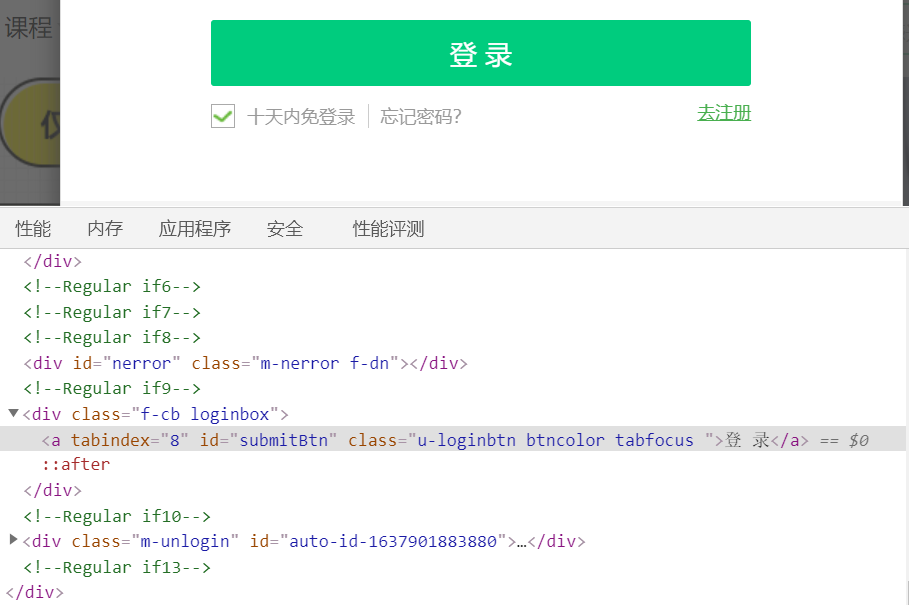
You can find that to log in by mobile phone, you need to click other login methods, then click mobile phone login, enter mobile phone number and password, and click login. Note that after each click (), you need to set the sleep time for the browser to buffer.
self.driver.find_element_by_xpath('//Div [@ class = "unlogin"] / / a [@ class = "f-f0 navloginbtn"]). Click() # login or register
time.sleep(2)
self.driver.find_element_by_class_name('ux-login-set-scan-code_ft_back').click() # Other login methods
time.sleep(2)
self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']//li[@class='']").click()
time.sleep(2)
self.driver.switch_to.frame(self.driver.find_element_by_xpath("//div[@class='ux-login-set-container']//iframe"))
self.driver.find_element_by_xpath('//input[@id="phoneipt"]').send_keys("*****") # enter the phone number
time.sleep(2)
self.driver.find_element_by_xpath('//input[@placeholder = "please enter password"]). send_keys("*****") # enter the password
time.sleep(2)
self.driver.find_element_by_xpath('//Div [@ class = "f-cb loginbox"] / / a [@ id = "submitBtn"]). Click() # Click to log in
time.sleep(6)
(3) After logging in, find the network elements that click to enter the personal center, and then find the network elements that access SPOC courses
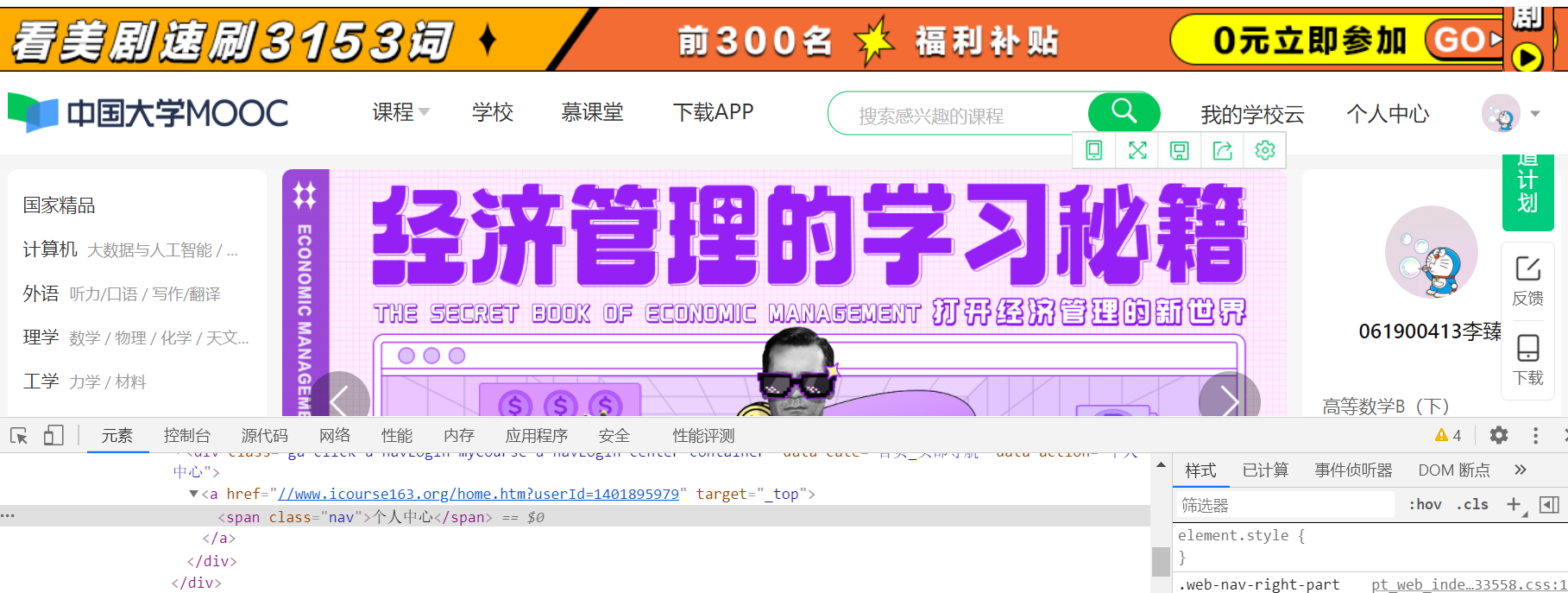
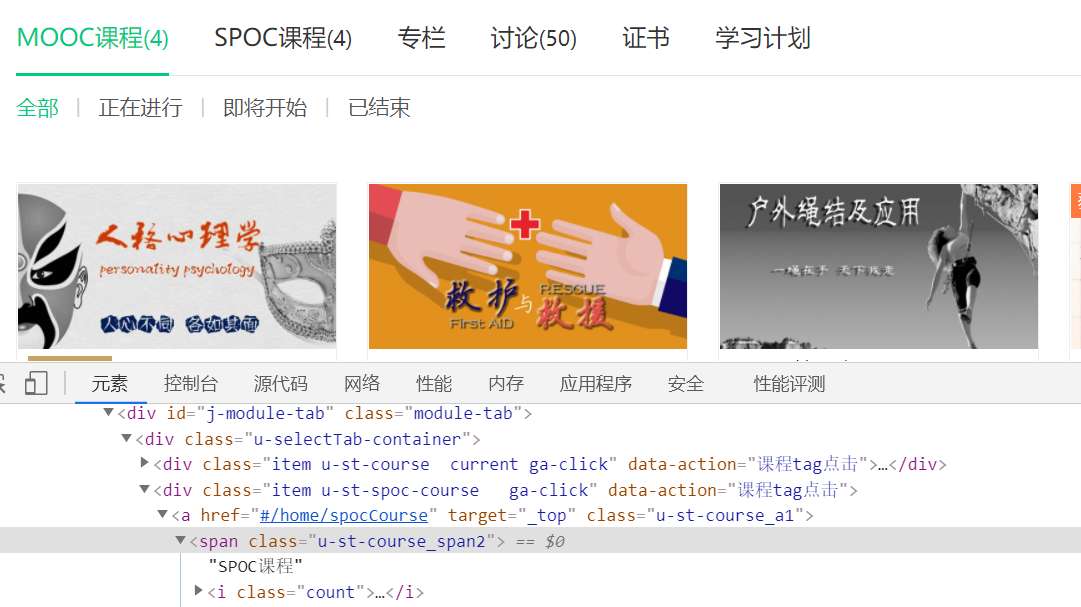
Thus, the click position can be found by using xpath search in selenium
self.driver.find_element_by_xpath("//div[@class='ga-click u-navLogin-myCourse u-navLogin-center-container']//span[@class='nav']").click() # click the personal Center
time.sleep(2)
self.driver.find_element_by_xpath('//Div [@ class = "item u-st-spoc-course GA click"] / / span [@ class = "u-st-course_span2"]). Click() # jump to SPOC course
time.sleep(2)
(4) Check the network element to find the tag pair corresponding to each information

It can be found that each information is in the attribute class = "course card wrapper" of div tag. Check the tag pair where each information is located according to the topic requirements, and then use xpath under selenium framework to crawl the information.
list1 = self.driver.find_elements_by_xpath(
"//div[@id='j-cnt1']//div[@class='course-panel-wrapper']//div[@class='course-card-wrapper']")
print("Crawling MOOC During the course")
for li in list1:
try:
MySpider.count += 1
cCourse = li.find_element_by_xpath('.//div[@class="text"]//span[@class="text"]').text
cCollege = li.find_element_by_xpath('.//div[@class="school"]/a[@target="_blank"]').text
cSchedule = li.find_element_by_xpath(
'.//div[@class="text"]//span[@class="course-progress-text-span"]').text
cCourseStatus = li.find_element_by_xpath(('.//div[@class="course-status"]')).text
cImgUrl = li.find_element_by_xpath('.//div[@class="img"]/img').get_attribute("src")
cImgUrl = cImgUrl.split("?")[0]
time.sleep(2)
Id = MySpider.count
self.insertDB(Id, cCourse, cCollege, cSchedule,cCourseStatus,cImgUrl)
print(Id, cCourse, cCollege, cSchedule, cCourseStatus, cImgUrl)
File = str(MySpider.count) + ".jpg" # Set picture name
self.download(cImgUrl,File) #Download pictures
except Exception as err:
print(err)
(5) Establish database links and create tables
try: #Connect to database
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd="123456", db="ex5", charset="utf8")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table course") # If there are tables, delete them
except:
pass
try: #Create table and set Id as primary key
sql = "create table course (Id varchar(32) primary key, cCourse varchar(256),cCollege varchar(32),cSchedule varchar(1024),cCourseStatus varchar(256),cImgUrl varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
(6) Create a folder to store downloaded pictures
try: #Create a folder for downloading pictures
if not os.path.exists(MySpider.imgpath): #If not, create
os.mkdir(MySpider.imgpath)
images = os.listdir(MySpider.imgpath) #Empty if present
for img in images:
s = os.path.join(MySpider.imgpath, img)
os.remove(s)
except Exception as err:
print(err)
(7) The process of accessing Chinese University Mu class web page with Chrome
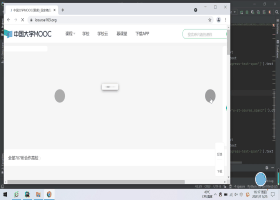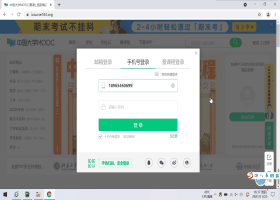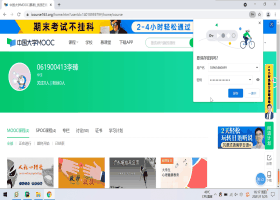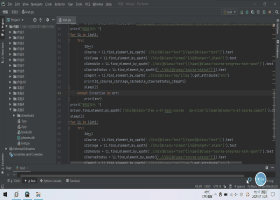
(8) Problems encountered and Solutions
- Problem: the console reports an error when accessing the personal center during login
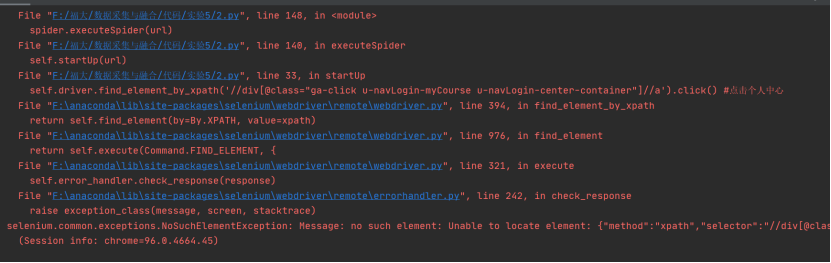
- Solution: after the hibernation time is extended, the problem is solved. It may be that the buffer time of the browser is longer than the originally set hibernation time.
Operation ③
1. Experimental contents
- Requirements: Master big data related services and be familiar with the use of Xshell
- Complete the tasks in the document Huawei cloud big data real-time analysis and processing experiment manual Flume log collection experiment (part) v2.docx, that is, the following five tasks. See the document for specific operations.
- Environment construction
- Task 1: open MapReduce service
- Real time analysis and development practice:
- Task 1: generate test data from Python script
- Task 2: configure Kafka
- Task 3: install Flume client
- Task 4: configure Flume to collect data
2. Experience
(1) Activate MapReduce service
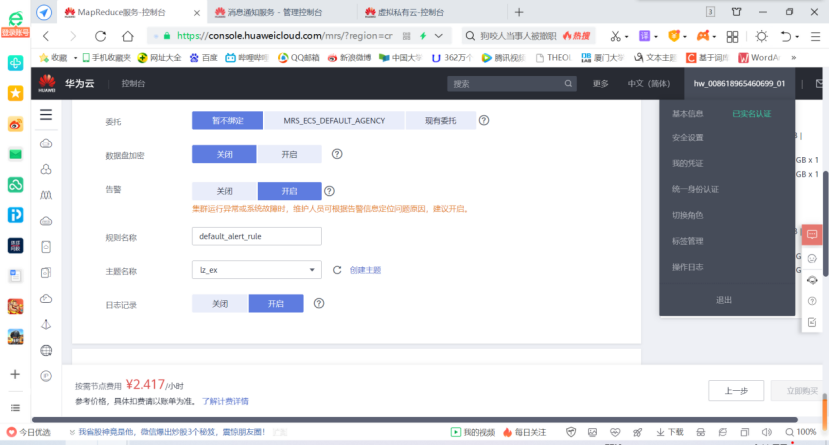
- To purchase a cluster, select custom purchase and perform hardware configuration and advanced configuration.
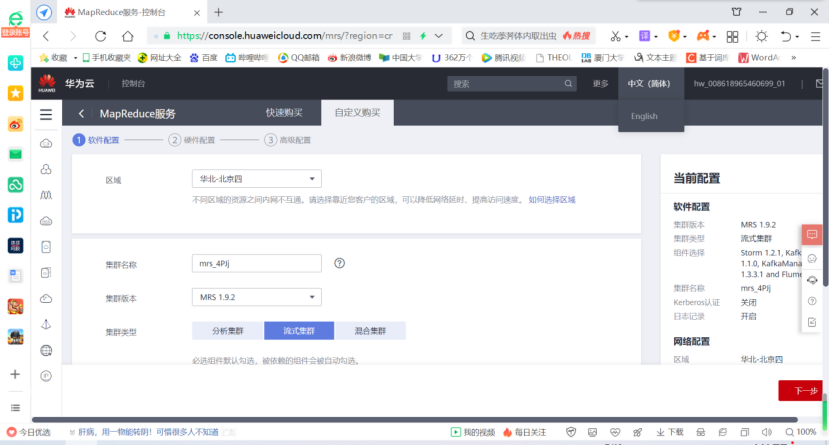
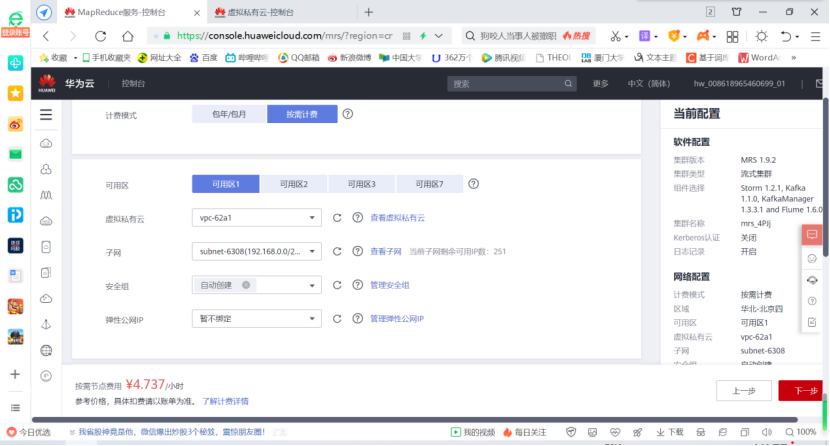
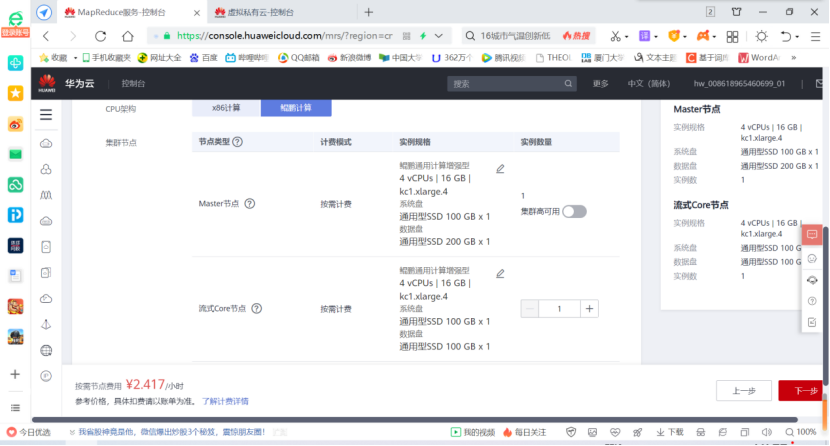
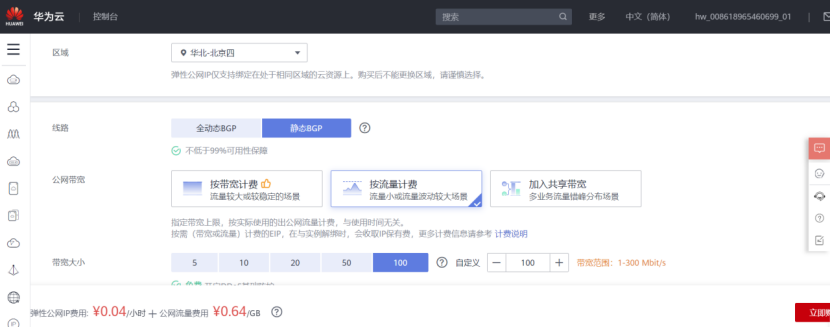
- Set up the elastic public network and purchase 2 public network IP addresses
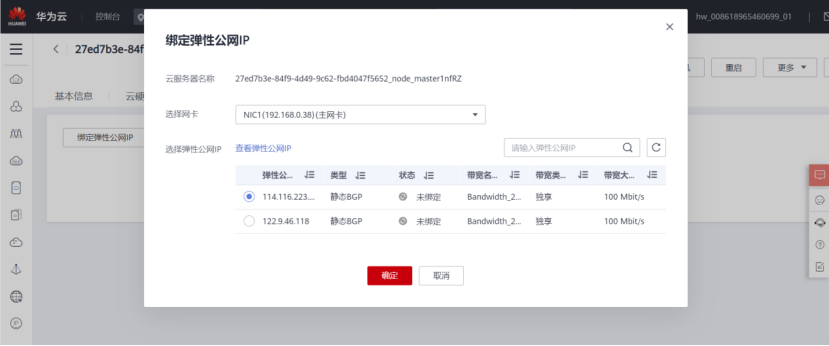
- Return to the mrs cluster page, click node management, bind public IP and enter the security group for one click release

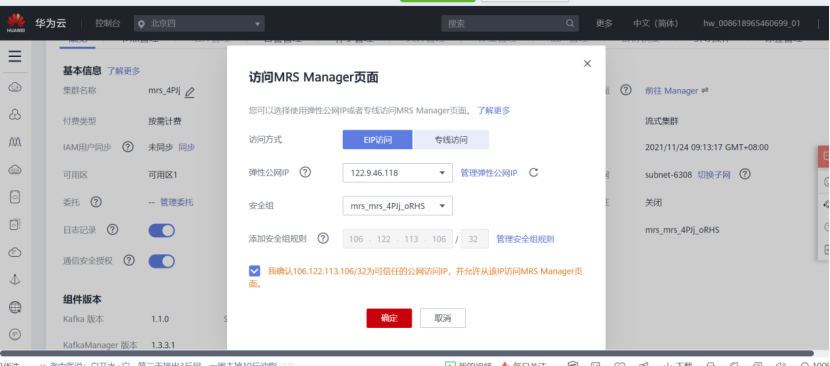
- Enter the Manager to set the public IP for accessing the MRS Manager interface
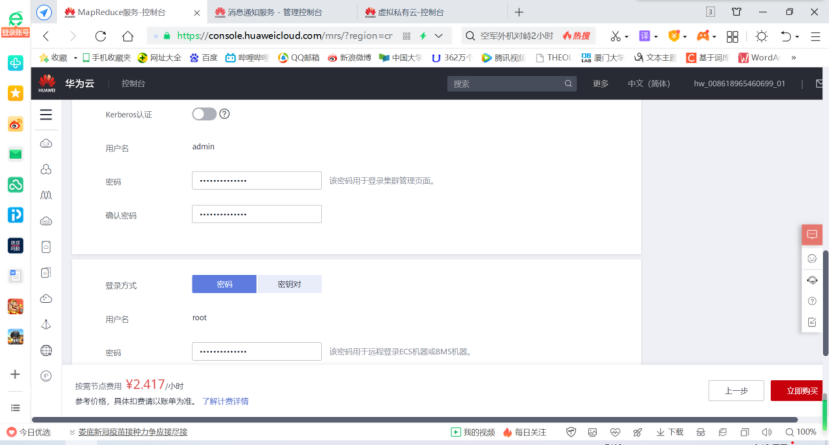
- User login
(2) Task 1: generate test data from Python script
- Use Xshell 7 to connect to the server and set up user authentication
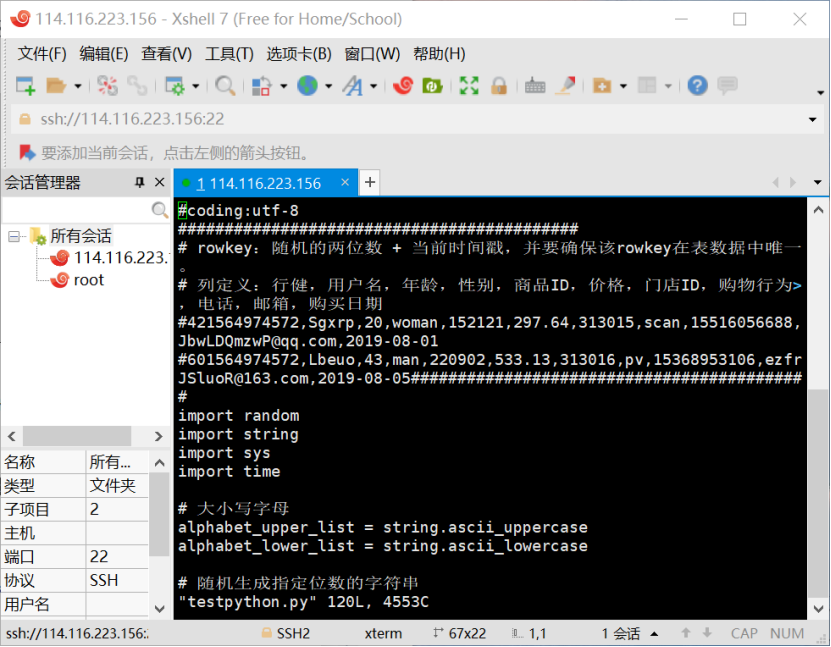
- Enter the / opt/client / directory and use the vi command to write Python scripts

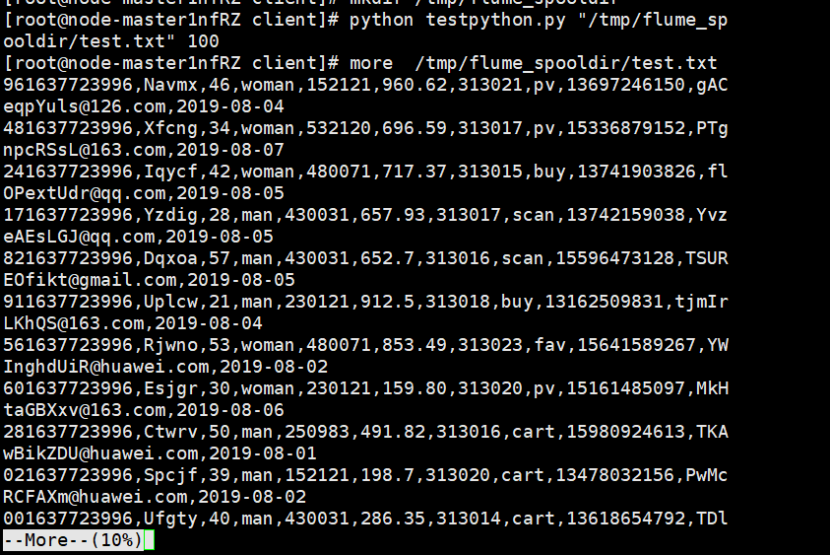
- Create directory: use the mkdir command to create the directory flume_spooldir under / tmp, put the data generated by Python script simulation into this directory, and Flume will monitor the directory under this file to read the data.

- Test execution: execute Python command to test, generate 100 pieces of data and view the data
(3) Configure Kafka
- Set the environment variable and execute the source command to make the variable effective

- Create topic in kafka, and pay attention to using the IP of the actual Zookeeper

- View topic information

(4) Install Flume client
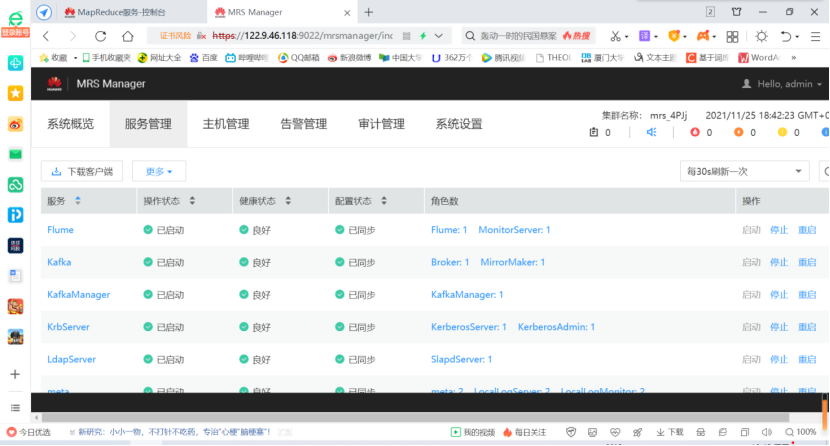
- Enter the MRS Manager cluster management interface, open service management, click flume, enter flume service, and then click download client
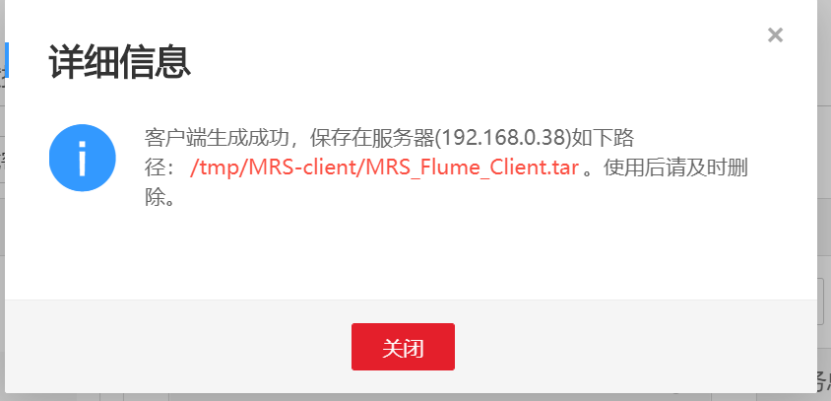
- Unzip the downloaded flume client file


- Verification package

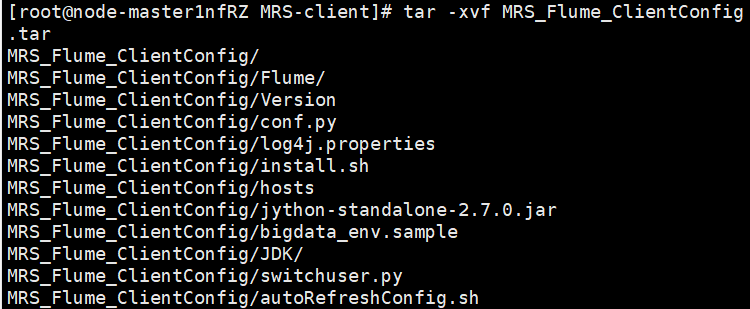
- Unzip the MRS_Flume_ClientConfig.tar file
- Install Flume environment variables and view the installation output information



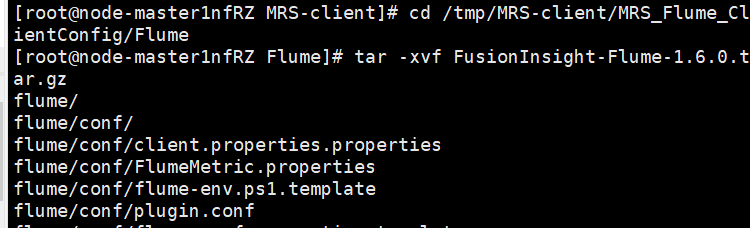
- Unzip Flume client
- Install Flume client: install Flume to the new directory "/ opt/FlumeClient", and the directory will be automatically generated during installation

- Restart Flume service
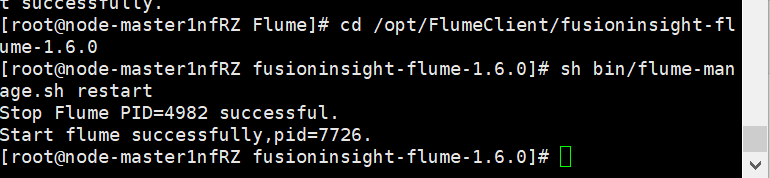
(5) Configure Flume to collect data
- Modify the configuration file and edit the file properties.properties in the conf directory
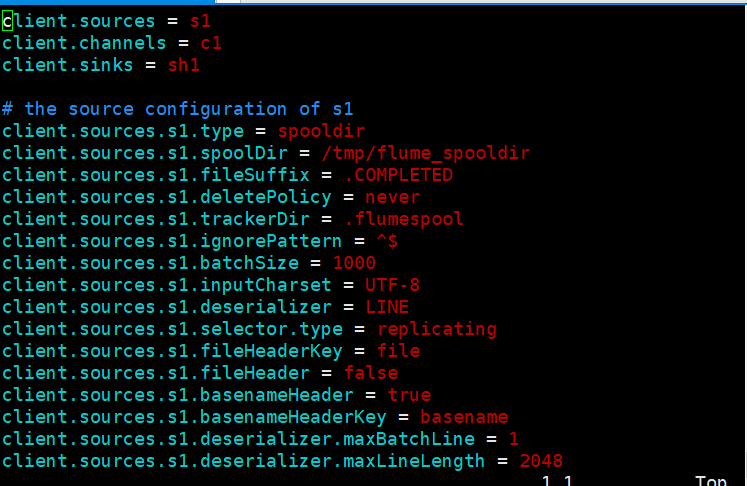
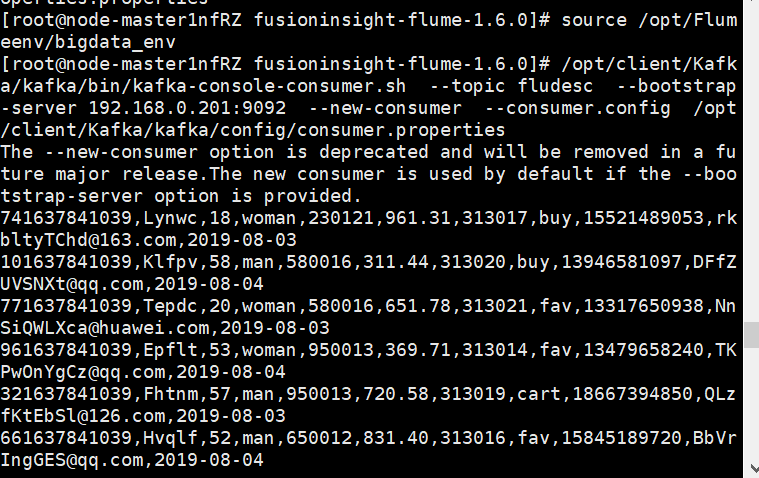
- source environment variable

- Create data in consumer consumption kafka
(6) Experimental experience: this assignment learned how to use Flume for real-time streaming front-end data collection. It was also the first time to contact huaweiyun platform and learn a lot of new things. Although the operation is not very skilled at the beginning, it has gained a lot. After later learning, it will be better and better.