[paper reproduction competition] ENCNet: Context Encoding for Semantic Segmentation
In this paper, the author introduces the Context Encoding Module to improve the effect of semantic segmentation by using global context information in the task of semantic segmentation. The requirement of this replay is that the miou on the Cityscapes verification set is 78.55%, and the miou in this replay is 79.42%. This algorithm has been used PaddleSeg Included.
1, Introduction
PSPNet obtains the characteristic maps of different sizes through SPP (Spatial Pyramid polling) module, and then combines the characteristic maps of different sizes to expand the receptive field; DeepLab uses ASPP (atlas spatial pyramid pool) to expand the receptive field. However, ENCNet raises a question: "Is capturing contextual information the same as increasing the receptive field size?" (is increasing receptive field equal to capturing contextual information?). The author proposes an idea: using the context information of the picture to reduce the search space of pixel types in the picture. For example, if there is a picture of a bedroom, it is much more likely that there are objects such as beds and chairs in the picture than other objects such as cars and lakes. This paper proposes Context Encoding Module and semantic encoding loss (SE loss) to learn context information.
2, Network structure
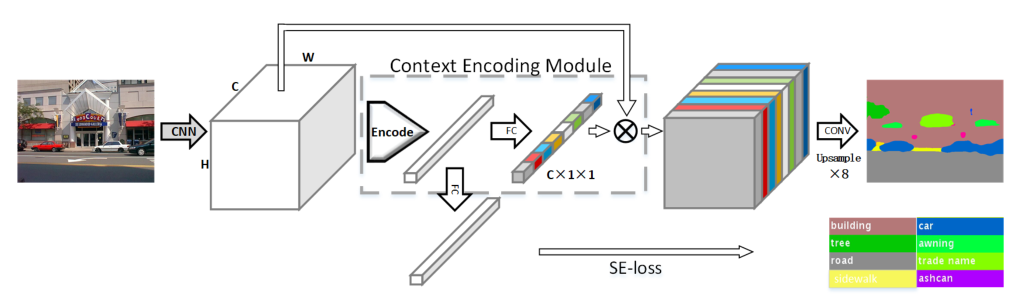
The above figure shows the network structure of ENCNet, mainly including Context Encoding Module, Featuremap Attention and Semantic Encoding Loss.
Context Encoding Module: This module encodes the input feature map to obtain the encoded semantic vector (originally called encoded semantics). The obtained semantic vector has two uses. The first is to send the Featuremap Attention as the weight of the attention mechanism, and the other is to calculate the Semantic Encoding Loss.
Featuremap Attention: This module makes the model pay more attention to channel features with large amount of information and suppress unimportant channel features. For example, in a picture with a sky background, there is a greater possibility of an aircraft than a car.
Semantic Encoding Loss: the pixel level cross entropy loss function fails to take into account the global information, which may lead to the failure of normal recognition of small targets, while SELoss can equally consider targets of different sizes. The target lost by SELoss is a (N, NUM_CLASSES) matrix, and its structure is also very simple. If there is an object in the picture, the label of the corresponding target is 1.
3, Experimental results

The above figure shows the prediction results of ENCNet in ADE20K data set. Compared with FCN, it can be seen that ENCNet has the significant advantages of using global semantic information:
1. In the first line of pictures, FCN classifies sand into earth, and ENCNet correctly classifies sand by using global information (the probability of sand on the beach);
2. In the second and fourth lines of images, FCN is difficult to distinguish between building,house and skyscraper;
3. In the third line, FCN classifies windowpane into door.
4, Core code
class Encoding(nn.Layer):
def __init__(self, channels, num_codes):
super().__init__()
self.channels, self.num_codes = channels, num_codes
std = 1 / ((channels * num_codes) ** 0.5)
self.codewords = self.create_parameter(
shape=(num_codes, channels),
default_initializer=nn.initializer.Uniform(-std, std),
) # code
self.scale = self.create_parameter(
shape=(num_codes,),
default_initializer=nn.initializer.Uniform(-1, 0),
) # Scaling factor
self.channels = channels
def scaled_l2(self, x, codewords, scale):
num_codes, channels = paddle.shape(codewords)
reshaped_scale = scale.reshape([1, 1, num_codes])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
scaled_l2_norm = paddle.multiply(reshaped_scale, (expanded_x - reshaped_codewords).pow(2).sum(axis=3))
return scaled_l2_norm
def aggregate(self, assignment_weights, x, codewords):
num_codes, channels = paddle.shape(codewords)
reshaped_codewords = codewords.reshape([1, 1, num_codes, channels])
expanded_x = paddle.tile(x.unsqueeze(2), [1, 1, num_codes, 1])
encoded_feat = paddle.multiply(assignment_weights.unsqueeze(3), (expanded_x - reshaped_codewords)).sum(axis=1)
encoded_feat = paddle.reshape(encoded_feat, [-1, self.num_codes, self.channels])
return encoded_feat
def forward(self, x):
x_dims = x.ndim
assert x_dims == 4, "The dimension of input tensor must equal 4, but got {}.".format(x_dims)
assert paddle.shape(x)[1] == self.channels, "Encoding channels error, excepted {} but got {}.".format(self.channels, paddle.shape(x)[1])
batch_size = paddle.shape(x)[0]
x = x.reshape([batch_size, self.channels, -1]).transpose([0, 2, 1])
assignment_weights = F.softmax(self.scaled_l2(x, self.codewords, self.scale), axis=2)
encoded_feat = self.aggregate(assignment_weights, x, self.codewords)
return encoded_feat
5, ENCNet quick experience
1. Unzip the cityscapes dataset;
2. Train ENCNet. The reproduction environment of this paper is Tesla V100 * 4. If you want to complete the reproduction results, please move on Script task;
3. Verify the training results. If you want to verify the reproduced results, you need to download them weight , and put it in output / best_ In the model folder (if the weight exceeds the 150MB limit, it can be compressed and uploaded in volumes).
# step 1: unzip data %cd ~/data/data64550 !tar -xf cityscapes.tar %cd ~/
# step 2: training %cd ~/ENCNet_paddle/ !python train.py --config configs/encnet/encnet_cityscapes_1024x512_80k.yml --num_workers 16 --do_eval --use_vdl --log_iter 20 --save_interval 5000
# step 3: val %cd ~/ENCNet_paddle/ !python val.py --config configs/encnet/encnet_cityscapes_1024x512_80k.yml --model_path output/best_model/model.pdparams
6, Reproducing results
The target of this reproduction is the Cityscapes validation set miou 78.55%, and the reproduced miou 79.42%.
Environmental Science:
Tesla V100 *4
PaddlePaddle==2.2.0
| Model | Backbone | Resolution | Training Iters | mIoU | mIoU (flip) | mIoU (ms+flip) | Links |
|---|---|---|---|---|---|---|---|
| ENCNet | ResNet101_vd | 1024x512 | 80000 | 79.42% | 80.02% | - | model | log| vdl |
7, Recurrence experience
1. If the reproduction accuracy does not meet the requirements and the gap is small, you can try to increase the training times;
2. For tipc convenience, it is best to verify whether the model can be exported from dynamic to static before training (some codes will make errors during dynamic to static export, so it is best to debug the export function before training to save the reproduction time);
3. Giving priority to using PaddleSeg framework to reproduce papers can save a lot of time and improve efficiency in PR.
8, Thanks
Thank you very much for the computing power and bonus support provided by AiStudio platform, and thank little sister RD for her patience in answering questions.