The fifth practice of data mining
Assignment 1
Jingdong information crawling experiment
Job content
- Requirements: be familiar with Selenium's search for HTML elements, crawling Ajax web page data, waiting for HTML elements, etc. Use Selenium framework to crawl the information and pictures of certain commodities in Jingdong Mall.
- Candidate sites: http://www.jd.com/
- Key words: Students' free choice
Practice process
Change the teacher's Sqlite database to sql server
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
# Initializing database
try:
self.con = pyodbc.connect(
'DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\Nimble;PWD=29986378;Trusted_Connection=yes')
self.cursor = self.con.cursor()
try:
# If there are tables, delete them
self.cursor.execute("drop table phones")
except:
pass
try:
# Create a new table
sql = "create table phones (mNo char(32) primary key, mMark char(256),mPrice char(32),mNote char(1024),mFile char(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
def showDB(self):
try:
con = pyodbc.connect(
'DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\Nimble;PWD=29986378;Trusted_Connection=yes')
cursor =con.cursor()
print("%-8s%-16s%-8s%-16s%s"%("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3],row[4]))
con.close()
except Exception as err:
print(err)
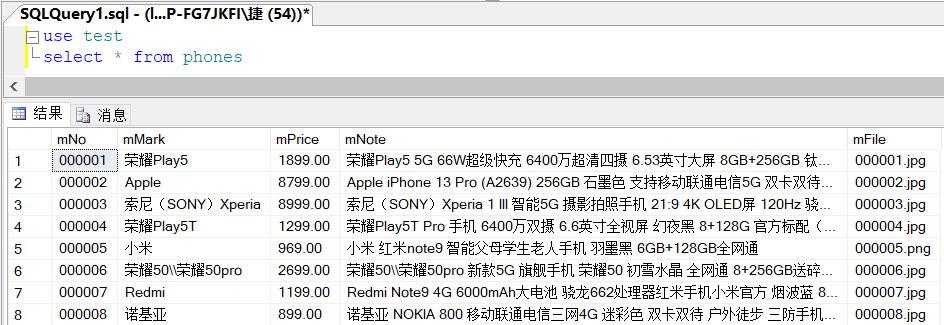
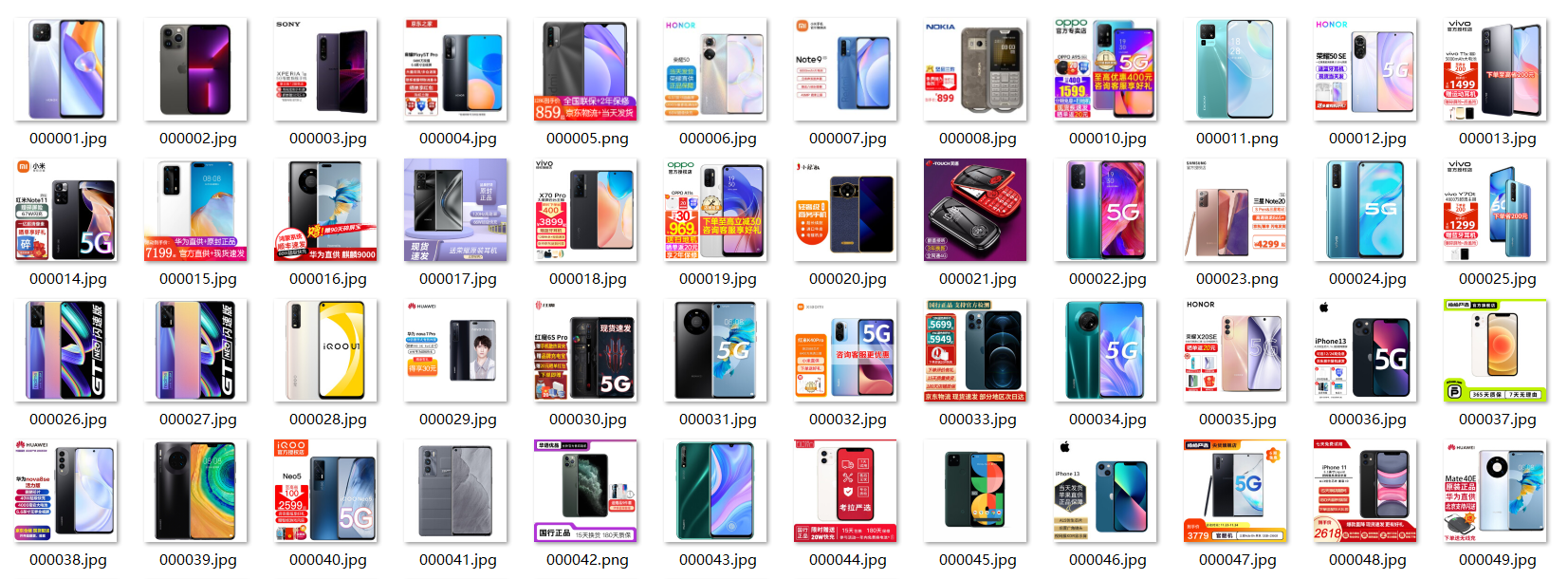
Job results
Assignment 2
MOOC crawling test
Job content
-
Requirements: be familiar with Selenium's search for HTML elements, realizing user simulated Login, crawling Ajax web page data, waiting for HTML elements, etc. Use Selenium framework + MySQL to crawl the course resource information of China mooc network (course number, course name, teaching progress, course status and course picture address), and store the picture in the imgs folder under the root directory of the local project. The name of the picture is stored with the course name.
-
Candidate website: China mooc website: https://www.icourse163.org
Practice process
-
Realize login function
# Login page link url = "https://www.icourse163.org/member/login.htm?returnUrl=aHR0cHM6Ly93d3cuaWNvdXJzZTE2My5vcmcvaW5kZXguaHRt#/webLoginIndex" ua = UserAgent(path="D:\\program\\python\\CrawlLearning\\fake_useragent_0.1.11.json").random chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') chrome_options.add_argument("user-agent=" + ua) driver = webdriver.Chrome(chrome_options=chrome_options) driver.get(url) time.sleep(10) # Allow time for code scanning and login -
Page information positioning
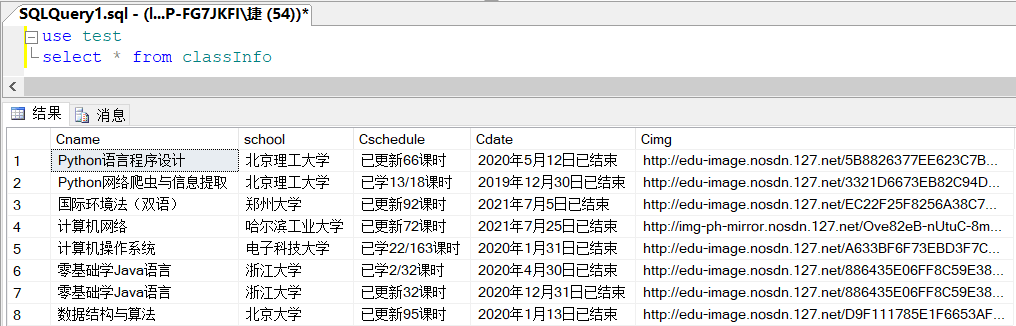
Take obtaining the course name as an example:
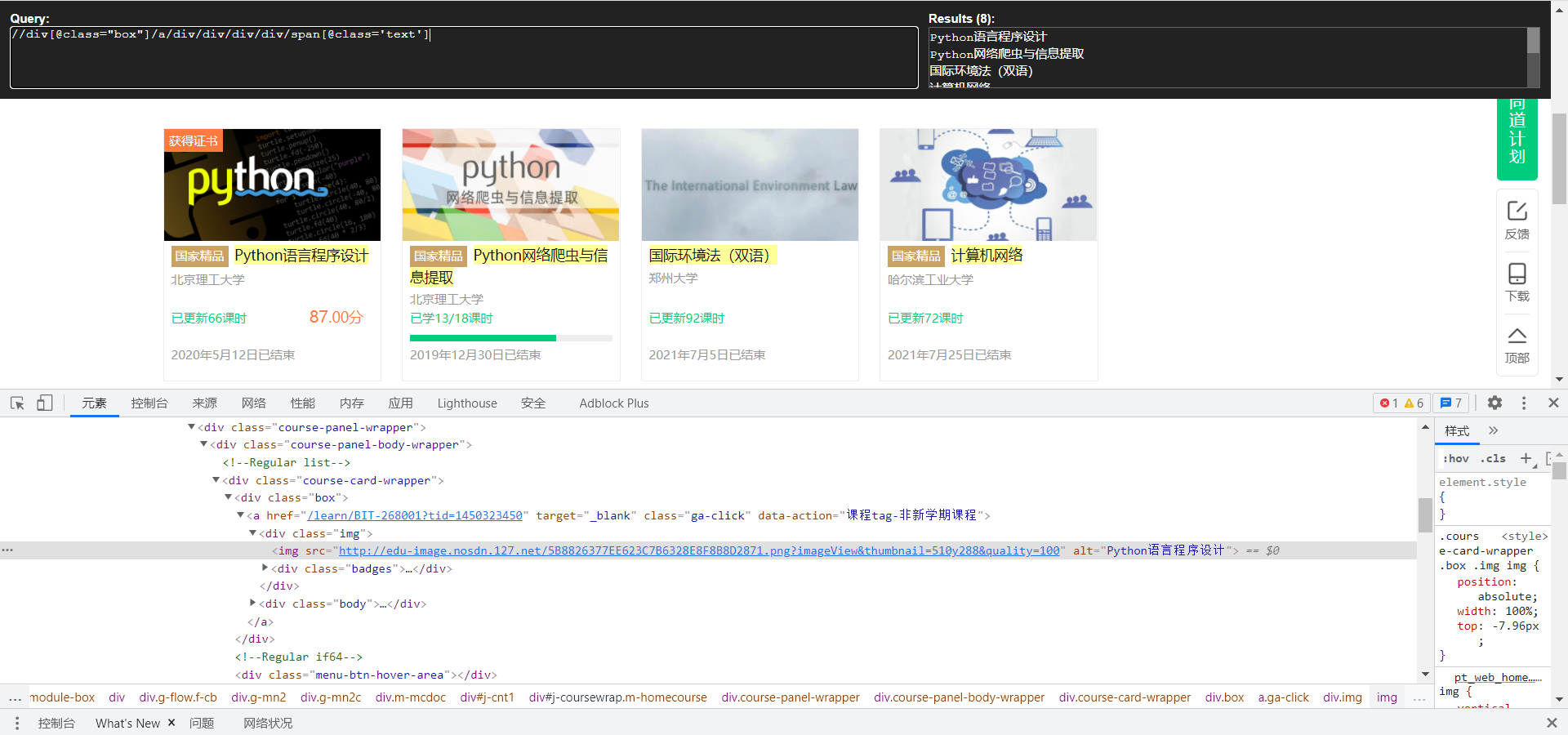
def getInfo(driver,infos): """ Get course information :param driver: Created webdriver :param infos: List for storing information :return: Course information list infos[[name,school,process,date,imgurl],] """ trs = driver.find_elements_by_xpath('//div[@class="box"]') for tr in trs: name = tr.find_element_by_xpath("./a/div/div/div/div/span[@class='text']").text # Course name school = tr.find_element_by_xpath("./a/div/div/div/a").text # school process = tr.find_element_by_xpath('./a/div/div/div[@class="course-progress"]/div/div/a/span[@class="course-progress-text-span"]').text # rate of learning date = tr.find_element_by_xpath('./a/div/div/div[@class="course-status"]').text # End date imgurl = tr.find_element_by_xpath('./a/div[@class="img"]/img').get_attribute("src") # Cover address print(name,school,process,date) infos.append([name,school,process,date,imgurl]) return infos -
Data storage in database
def savetoDB(infos): # Store to database conn = pyodbc.connect( 'DRIVER={SQL Server};SERVER=(local);DATABASE=test;UID=DESKTOP-FG7JKFI\Nimble;PWD=29986378;Trusted_Connection=yes') cur = conn.cursor() # Judge whether the table exists in the database. If it exists, delete it try: cur.execute("DROP TABLE classInfo") except:pass cur.execute('CREATE TABLE classInfo (Cname char(200),school char(200), Cschedule char(100),Cdate char(100),Cimg char(500))') # Data writing for s in infos: sql = 'insert into classinfo([Cname],[school],[Cschedule],[Cdate],[Cimg]) values(?,?,?,?,?)' cur.execute(sql, (s[0], s[1],s[2],s[3],s[4])) print(s[1],"saving complete") conn.commit() conn.close()
Job results
experience
This experiment realizes the login function, and some information can be displayed only after login. Pay attention to the sleep time when logging in. It also takes a certain time for the login page to jump, otherwise it may not be able to climb out of the page.
Assignment 3
Flume experiment
Job content
-
Requirements: understand Flume architecture and key features, and master the use of Flume to complete log collection tasks. Complete Flume log collection experiment, including the following steps:
Task 1: open MapReduce service
Task 2: generate test data from Python script
Task 3: configure Kafka
Task 4: install Flume client
Task 5: configure Flume to collect data
Practice process
Task 1: open MapReduce service

Task 2: generate test data from Python script
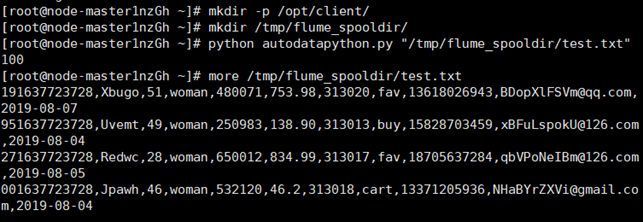
Task 3: configure Kafka
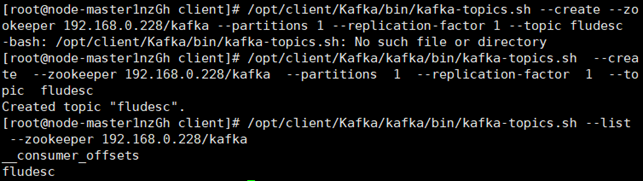
Task 4: install Flume client
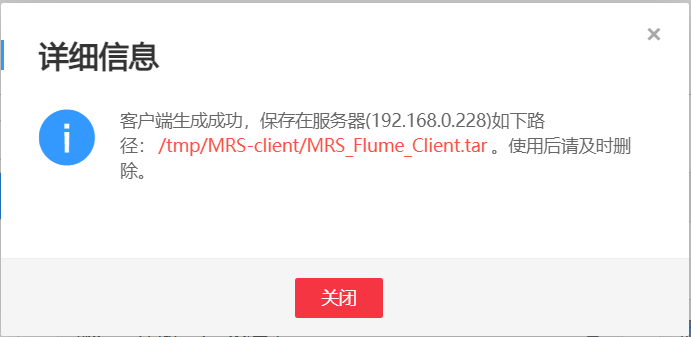
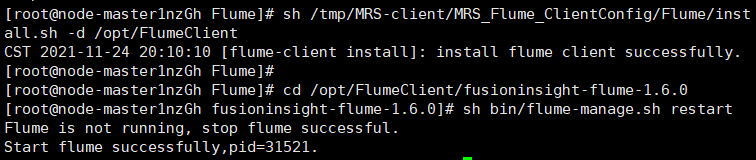
Task 5: configure Flume to collect data
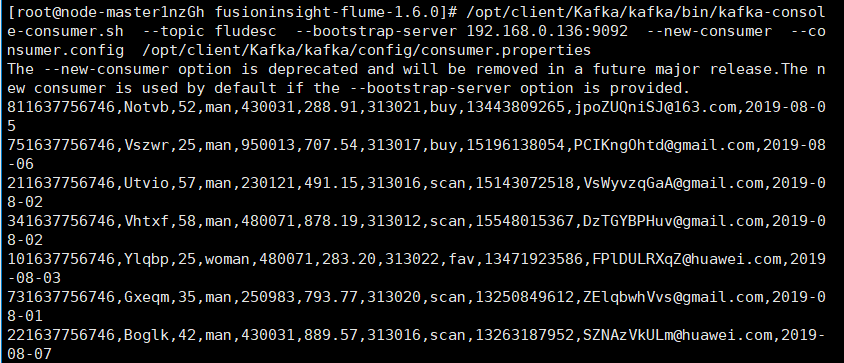
Capture successful