ioc of spring
Before talking about ioc, I think we should first understand the dependency inversion principle, that is, the high-level module cannot directly rely on the low-level module, but should rely on the abstraction of the low-level module. This is to untie the code coupling. Then when we develop with this design pattern, we still have to solve the problem of creating objects. If we need the caller to create these objects, It is difficult to maintain. At this time, we need a container to help create and manage objects. ioc plays this role, and di is an implementation of ioc. ioc's consciousness is that control inversion refers to the creation of objects by itself in the program code, but this control is handed over to the ioc container, which helps us create these objects, Then these objects are injected into the high-level module according to the dependency.
Pay attention to the six principles of design pattern
spring aop
Aspect: it is the combination of pointcut and notification
Notice: it is divided into pre enhancement, post enhancement and surround enhancement
Connection point: refers to the point that can be inserted into the section, which refers to the method
Tangent point: it is the connection point that can be added by inserting
Weaving: the process of adding enhancements to the target object
Target object: the enhanced class
Proxy object: refers to the proxy object generated after weaving enhancement
The main application is log and transaction
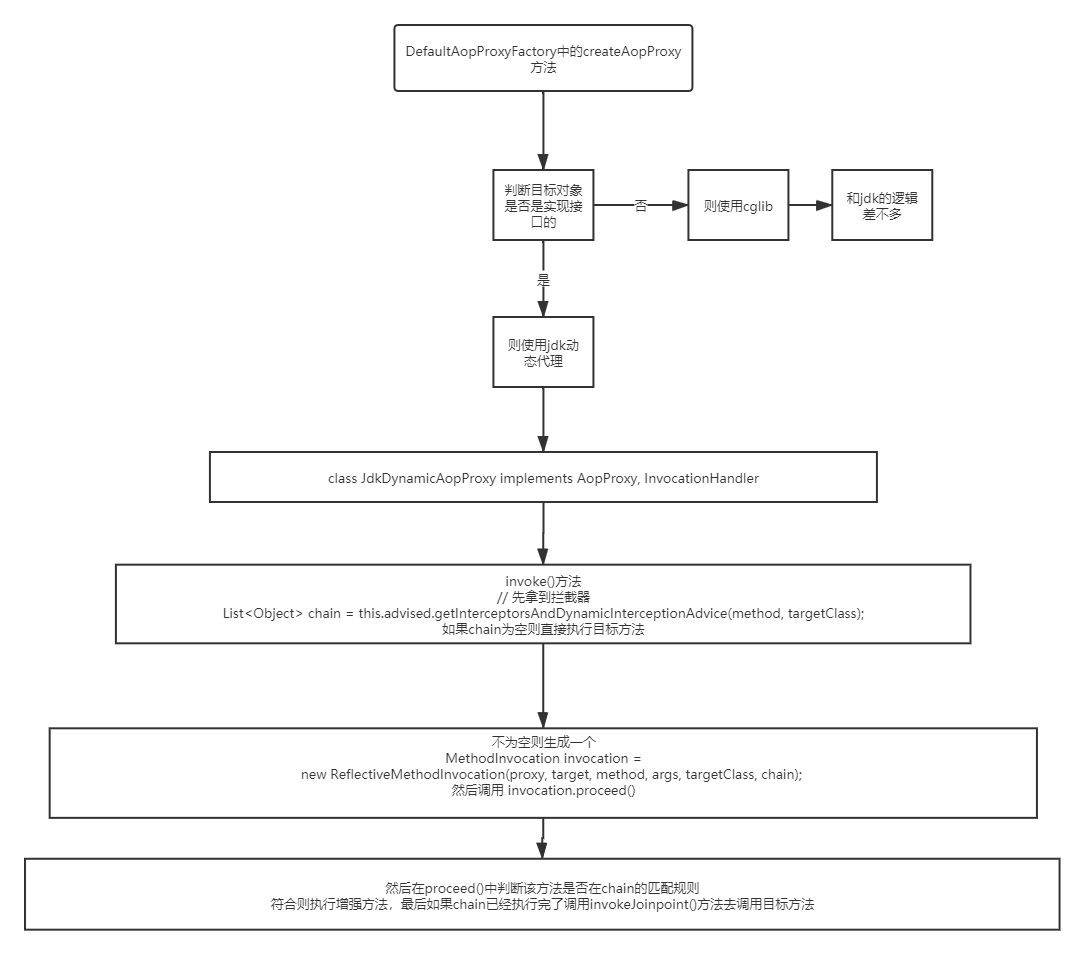
The dynamic proxy of jdk is used to generate the proxy object. When the target object has no interface, cglib is used to generate the dynamic proxy object
Logic of dynamic agent
That is to generate a dynamic proxy object based on the target class. What is called in the dynamic proxy class is actually the invoke method in invocationHandle. That is why we still need to rely on a target object, because in the invoke method, we need to call the specific implementation of the target method.
Simple principle of aop
The lifecycle of spring bean s
instantiation
Attribute injection
initialization
Destroy
After instantiation, you can see whether the bean implements the interfaces of beannameaware, beanfactory aware and applicationcontextaware. If you implement the corresponding methods first, if you implement the interface of BeanPostProcessor, there are two methods, one is before initialization and the other is after initialization, which is used to strengthen the bean, However, this is a container level process, which will make all beans go through this process during initialization
Propagation mechanism and isolation level of spring transactions
Communication mechanism: there are seven kinds
1. Required: if there is no current transaction, create a new transaction. If there is a current transaction, join the current transaction
2. Supports: if there is a transaction, the transaction will be added. If there is no transaction, it will be carried out in the form of non transaction
3.mandatory: (mandatory): if there is a transaction, join the transaction. If there is no transaction, throw an error
4.required_ New (New must be opened). If there is A current transaction, suspend the current transaction, and then start another transaction execution method. For example, if the current transaction is A,A will be suspended, and then start B transaction. If B transaction rolls back, AB will roll back. If A rolls back, B will not roll back but commit normally
5.not_ Supported if there is currently a transaction, suspend the transaction and never execute it as a transaction
6. Never: never execute as a transaction. Thrown if the current transaction exists
7.nested: the outer layer rolls back, and the inner layer rolls back
Transaction isolation level
1. Read not submitted
2. Read submitted
3. Repeatable
4. Serialization
springboot startup process
The @ SpringBootApplication in @ SpringBootApplication in springboot will @ Import a bean "autoconfigurationimportselector" and scan meta-inf / spring through getCandidateConfigurations In the files of factories, there are groups of key values to save the classes that need autoConfig. Springboot will decide whether to load the class into the container according to the annotation of @ ConditionXXX on these classes. @ EnableConfigurationProperties is to load the configuration properties. These properties can also be defined in the properties and yml files. This is the core of the Convention greater than the configuration
The principle of hot deployment is that there are two classloaders, one is responsible for loading third-party jar s that will not change, and the other is responsible for loading classes that will change.
Spring cloud related interview questions
What is microservice: microservice is a distributed architecture, which divides a single project system into multiple services. Lightweight communication mechanism is adopted for communication between services, and each service can be built and deployed separately (soa?)
The difference between nacos and eureka and zookeep
Both use ap, but nacos also supports cp, and zoomkeep is cp
eureka registry cluster is decentralized. nacos will choose a leader, and zookeep will also choose a leader
Data synchronization in Cluster:
nacos sends the data to the followers in the form of heartbeat. If more than half of the followers update the data successfully, they will notify other nodes to update the data as well
eureka is to send registration information to each node
Zoomkeep is that the leader writes data and then synchronizes the data through 2pc (two-stage submission). During this period, zoomkeep is unavailable
nginx and ribbon
Nginx is that the user sends a request to nginx, and then the nginx server realizes load balancing forwarding
ribbon is forwarding on the client side. It obtains the service list from the registry, and then load balancing
ribbon's interview questions
ribbon has six load balancing algorithms
polling
random
Weighted according to the speed of response time
Minimum concurrency
Weighted by performance and availability
Filter out fused services
seata (AT mode)
Divided into three roles
TC (Transaction Coordinator) transaction coordinator is responsible for coordinating and driving the submission or rollback of global transactions
TM (Transaction Manager) Transaction Manager is responsible for initiating a global transaction and initiating the resolution of global transaction submission or rollback
RM (Resource Manage) is the branch transaction manager, which controls the local submission of branch transactions, registers branches to TC, and accepts the instructions of TC global transaction submission or rollback.
The main process is that TM applies to TC for a new global transaction and generates a global transaction id (xid)
Then each RM registers branch transactions with TC. RM will first execute local SQL and generate an undo record, and then try to obtain the global lock (the global write exclusive lock of Fescar is unlocked). If other global transactions occupy this lock, retry. If it cannot be obtained, roll back the local transaction, delete the undo record, and tell TC that the execution of branch transactions fails. If the global lock is obtained successfully, the local transaction is committed and the ownership of the lock is maintained.
If the TC drives the global transaction commit, the branch transaction releases the global lock first, then enables the asynchronous deletion of undo records, and returns success directly to the TC,
If the TC driven global transaction is rolled back, RM will start a local transaction, query its own undo records and compare the after of undo_ If the image is the same as the current record, follow before_image is rolled back. If it is different, it is rolled back according to the set policy. If it is not set, it is rolled back according to before_image rollback.
after_ How is the image compared with the current record?
Xa mode (using XA protocol)
Like the AT mode, the method of no invasion to the business is not compensatory, but has good data consistency
technological process:
TM requests a global transaction from TC
RM registers branches with TC respectively, and then executes business SQL and XA prepare. At this time, it enters the blocking state and waits for the driving instruction of TC
Because the branch transaction is not committed, the TC drives any command to execute rollback or commit according to the command.
(MT mode) TCC
It is divided into three parts
try
confirm
cancel (rollback)
Final consistency scheme
Hystrix:
When is the service avalanche: it refers to the call between services and long-time waiting, which leads to the accumulation of upstream service requests. Finally, the upstream service resources are exhausted and spread upward, leading to the avalanche.
Service degradation, service fusing
CAP
C: Consistency when a node receives a request to modify data, it will synchronize the data to other nodes. The system can only be used if all nodes obtain the latest data. If some nodes cannot achieve consistency due to network and other reasons, in order to achieve the consistency of external data, the nodes that are not synchronized to the data can only return empty data.
A: Availability means that as long as the node receives the request, it needs to return data normally, regardless of whether the data is consistent or not
P: Partition fault tolerance may be caused by abnormal network communication between nodes, or when some nodes are down, partition will occur. The system will not make the whole system unavailable because of partition. This is partition tolerance.
In the distributed system, in order to improve the tolerance of partitions, it is necessary to copy nodes to more nodes, and then the difficulty of synchronizing data increases. It is difficult to ensure the availability by waiting for all node data to be synchronized. The more nodes, the higher the partition tolerance, the more difficult it is to ensure the consistency, and the longer the waiting time, the lower the availability.
BASE theory: strong consistency is too difficult. We can achieve final consistency
hashmap currentHashmap
hashMap: in the implementation of 1.7, array + linked list, and in the implementation of 1.8, array + linked list + red black tree
The insertion mode of linked list is changed from head insertion to tail insertion.
1.8 put method and process
Insert the red black tree into the TreeNode: first find the root (root node) and assign the root to p, then traverse from the root node to determine whether the hash of the key is the left or right of the node. If it is the left, assign the left child node to p, and if it is the right, assign the right child node to p
Then continue to traverse. When the left child node or the right child node is empty, it means that the corresponding location has been found. Create a new node and establish the relationship between nodes, linked list and red black tree.

Capacity expansion process
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length; // Old array capacity
int oldThr = threshold; // Old array threshold
int newCap, newThr = 0;
// If the capacity of the old array is greater than 0
if (oldCap > 0) {
// If it is greater than the maximum capacity, the old array is returned directly
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// Double the capacity and double the threshold
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// Explain that the called spatiotemporal parameter construction method needs to initialize the capacity and threshold
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// Rearrange red black tree nodes
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// Rearrange linked list nodes
Node<K,V> loHead = null, loTail = null; // Head and tail of array [old]
Node<K,V> hiHead = null, hiTail = null; // Head and tail of array [old + oldcap]
Node<K,V> next;
do {
next = e.next;
// This indicates that the node will still be in the original position of the array
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// Accordingly, put the head node of the linked list into the array
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Main process
First, if the oldcap is greater than 0, double it according to the oldcap and the old threshold. If it is not greater than 0, it means that the HashMap needs to be initialized. Pass in the required default value for initialization. In the linked list part, according to the hash and operation oldcap, get whether the node is in the original position or in the original + oldcap position, and then use the tail interpolation method to sort the linked list, Finally, set the head of the linked list to the new array.
The hash method uses the low 16 bit XOR and high 16 bit XOR of the key (XOR means 0 for the same and 1 for the different). It is also called the perturbation function. In order to avoid hash collision
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
The indexFor method uses the hash value and the array length minus 1 to perform the sum operation (if both are 1, it is 1, otherwise it is 0)
static int indexFor(int h, int length) {
return h & (length-1);
}
1.7 head insertion will lead to circular linked list
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
//1. Get the next element of the old table
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
In a multithreaded environment.
The array position 0 is A linked list 5 - > 9. At this time, threads A and B put data, resulting in capacity expansion for both A and B
Suppose that when thread A just starts to traverse to node e=5, it executes to entry < K, V > next = e.next; It is blocked, but thread B has completed the capacity expansion. Change the header insertion method of linked list 5 - > 9 to linked list 9 - > 5. At this time, thread A recovers and continues to execute code e.next = newTable[i]; At this time, change the next pointer of node 5 to newTable[i], because thread B has set the linked list to 9 - > 5, so newTable[i] = 9. At this time, the next pointers of the two nodes will point to each other, resulting in the emergence of circular linked list. At this time, it will enter the dead loop.

concurrenthashmap
put:
1. If initialization is required, call the initialization method. During initialization, the current initialization state will be determined according to sizeCtl. 0 means that no one may be initializing. Try to modify sizeCtl to - 1 by their own thread. If successful, initialize. If successful, set sizeCtl to the size value of the next expansion.
2. Get I through hash & (n -1) first. If tab[i] == null, try to modify it into a put node through cas
3. If it is not empty, lock and traverse the linked list or red black tree to modify the value or add nodes
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// Neither key nor value can be empty
if (key == null || value == null) throw new NullPointerException();
obtain hash
int hash = spread(key.hashCode());
int binCount = 0;
// Only break and return can come out of the loop
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// During initialization, the initTable will first judge whether the value of a sizeCtl is 0. If it is 0,
// Then cas attempts to change 0 to - 1 (indicating that it is initializing), initialize the thread that has been successfully modified, and then change sizeCtl to the size of the next expansion.
// If it is found that it is already less than 0, suspend the thread (that is, give up cpu time, and then grab it together)
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// If the table node is empty, try to change the value to the in put node through cas. If successful, break to launch the loop
// Otherwise, continue to enter the dead cycle
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// If f.hash == MOVED(-1) is found, it indicates that capacity expansion is in progress
// Add help for capacity expansion at this time (this is not very clear 0.0)
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// If you add a node that does not conform to the hasap scenario, you can perform the same operations as adding a node that does not conform to the hasap scenario
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// Finally, give the current capacity + 1 to judge whether it needs to be expanded
addCount(1L, binCount);
return null;
}
transfer capacity expansion method
// This method is not well understood
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// Double capacity expansion
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
// It is equivalent to a temporary container during capacity expansion
// The tab = nexttab will be replaced after the final processing is completed
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// Under this condition, replace the tab with nextTab, indicating that the whole expansion is completed
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// Or through tail interpolation, arrange the data into a linked list
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// Change the tab[i] node to FWD (it actually contains a whole nextTable)
// If you find that the node is fwd in the put method, you can know that it is in capacity expansion
// In the get method, if the node is found to be fwd, fwd will be called here Find method finds node data
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
get
Since table is volatile modified, it is visible. That is, the write of volatile modified variables is before the read operation, so the modification of other threads is visible
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// If the capacity is currently being expanded, the find method calls forwardingnode find
// The result is returned by finding the data of nextTable in ForwardingNode
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
ForwardingNode
/**
* A node inserted at head of bins during transfer operations.
*/
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
Look at MySQL again. The myslq optimization strategy will be reviewed tomorrow
mysql table creation rules
1. Select the appropriate data type. varchar variable length type shall be used as far as possible for character type, because char is of fixed length. char(10) is stored in less than 10 characters, and spaces will be added if it is insufficient.
2. Try to set all fields to be non empty, and set the default value for the field
3. Decimal is used for data with decimal point
Location of mysql index establishment
1. The connection points between tables need to be indexed
2. Frequently searched columns
3. Columns of frequent range query
mysql common sql optimization, explain
Principle of mysql index
hash index
It is to hash the values on the indexed column. If the hash collides, it will be connected with a linked list. The index saves the pointer of the row
hash indexes can only be paired with values and cannot be used for range query
b + tree index
Construction using b + tree as index
Is a multiway lookup tree
Non leaf nodes do not save data, but only save key values and a pointer
Leaf nodes store data, and each leaf node is connected into a linked list
Because the size of each mysql read from the disk is 16k, that is, each page of mysql is 16k. Generally, our primary key uses bigint (8 bytes) + a pointer is about 6 bytes, so a page will have about 16 * 1024 / (8 + 6) ≈ 1000, that is, the tree with height of 3 can store the value of 1000 * 1000 * 1000
Inverted index
mysql transactions and mvcc
jvm, gc content, jvm tuning, oop object-oriented understanding must be completed the day after tomorrow
The project summary background is basically completed
Look at multithreading
Design mode
Six principles
Single responsibility principle
Opening and closing principle
Dependency Inversion Principle
Richter substitution principle
Interface isolation principle
Dimitri principle
Dealing with idempotency
rabbitmq
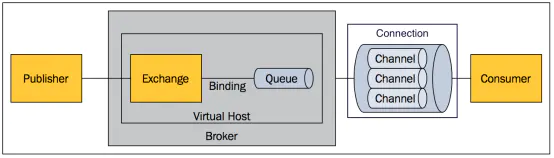
concept
broker: represents the message queuing server entity
Exchange: a switch that accepts messages sent by producers and routes them to the corresponding queue
Binding: binding, used for the association between queues and switches. A binding is to bind queues and switches according to routing keys
Therefore, the switch is a routing network table composed of bindings
Queue: queue, which is used to store messages and send them to consumers. It is the storage container of messages. A message can be put into multiple queues.
Virtual Host: it is a Virtual Host, including Exchange, Binding and Queue. It is an independent server sharing the same authentication and encryption environment, which is equivalent to a mini Rabbitmq.
Exchange type
direct: unicast mode. routingKey is the name of the message queue
fanout: the mode of sorting. It is sent to the message queue bound to the switch. There is no routingKey. As long as the message queue bound to the relationship can receive the message sent by the switch
Topic: topic mode, which allows the user-defined routingKey to be added when the switch is bound to the queue, such as rutting_ key_ queue1,
Then the switch uses rutingKey to find the corresponding queue, * means matching any character, # means matching one or more characters.
/**
* Topic mode queue
* <li>The routing format must be in Separation, such as user Email or user aaa. email</li>
* <li>Wildcard *, which represents a placeholder or a word, such as user. *, So user Email can match, but user aaa. Email doesn't match</li>
* <li>Wildcard #, representing one or more placeholders, or one or more words, such as routing to user. #, So user Email can match, user aaa. Email can also match</li>
*/
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(RabbitConstant.TOPIC_MODE_QUEUE);
}
@Bean
public Queue queueTwo() {
return new Queue("queue2");
}
@Bean
public Binding topicBinding2(Queue queueTwo, TopicExchange topicExchange) {
return BindingBuilder.bind(queueTwo).to(topicExchange).with("ruting_key_queue1");
}
This annotation can be used to help generate switches, queues, and binding relationships between them. At the same time, this annotation can be used as a listener for consumers
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "topic.n1", durable = "false", autoDelete = "true"),
exchange = @Exchange(value = "topic.e", type = ExchangeTypes.TOPIC),
key = "r"))
How to ensure that the message is sent out and successfully consumed
rabbitmq:
# Start the sender's arrival queue confirmation [sender's confirmation mechanism + local transaction table]
publisher-returns: true
# Start sending confirmation [sending end confirmation mechanism + local transaction table]
publisher-confirm-type: correlated
# As long as you arrive in the queue, you have priority to call back return confirm
template:
mandatory: true
# Use the manual confirmation mode to turn off automatic confirmation [message loss]
listener:
simple:
acknowledge-mode: manual
The sender starts the message callback after sending the message to the broker successfully
The sender starts the callback when the message does not arrive in the queue
Consumer uses manual ack
If you really need to ensure that the message will be sent successfully and consumed successfully, create a table to save the message content, switch name, routing key, message status (new, arrived at the broker, failed to send, successful consumption), create a new record before sending the message, get its id and put it into the message, Then, according to the successful callback that arrives at the broker, modify the record status that has arrived at the broker, and change the status to send failure in the callback that the message cannot reach the queue. (this can also be used to prevent repeated consumption, that is, if the consumption is successful, it will directly ack)
How to ensure that messages are not consumed repeatedly
Ensure idempotency of messages
Before sending a message, a token is generated and stored in redis
A token is stored in each message
On the consumer side, go to redis to find the token. If there is any, carry out subsequent processing, and then delete the token
Dead letter, dead letter queue, dead letter switch
It is to send a message to a queue with message expiration time set. When the message expires, it is called private message. This queue is called dead letter queue. The dead letter queue also needs to set a dead letter switch and a routing key, which is to hand over these dead letters to a queue for processing.
Review what you dare to write on your resume. People are numb