kubernetes scheduler has analyzed SchedulerCache, ScheduleAlgorithm, scheduleextender, Framework and other core data structures, as well as the core implementation of optimization, scheduling and preemption processes. This paper is the last chapter of this series, and also a summary of the current stage's learning of scheduling
I've updated the whole series of documents to the address of YuQue. Thank you for sharing and wechat communication https://www.yuque.com/baxiaoshi/tyado3/
1. Binder
Binder is responsible for passing the scheduling results of the scheduler to the apiserver, that is, binding a pod to the selected node node
1.1 build binder
A default binder will be built in the scheduler/factory
func getBinderFunc(client clientset.Interface, extenders []algorithm.SchedulerExtender) func(pod *v1.Pod) Binder { defaultBinder := &binder{client} return func(pod *v1.Pod) Binder { for _, extender := range extenders { if extender.IsBinder() && extender.IsInterested(pod) { return extender } } return defaultBinder } }
1.2 implementation of binder interface
The bind interface and simple bind interface only need to call the pod of apiserver to complete the bind operation
// Implement Binder interface var _ Binder = &binder{} // Bind just does a POST binding RPC. func (b *binder) Bind(binding *v1.Binding) error { klog.V(3).Infof("Attempting to bind %v to %v", binding.Name, binding.Target.Name) return b.Client.CoreV1().Pods(binding.Namespace).Bind(binding) }
1.3 incredible bind timing
The binding operation is located in the scheduler.bind interface. After calling Framework.RunBindPlugins, the bind operation can only be performed when the returned status is not success, but SKIP. I really don't know what I think. If I add the corresponding bind plug-in later, I also need to return SKIP, so I can't understand God's thinking
bindStatus := sched.Framework.RunBindPlugins(ctx, state, assumed, targetNode) var err error if !bindStatus.IsSuccess() { if bindStatus.Code() == framework.Skip { // If all plug-ins skip, you can bind pod to apiserver err = sched.GetBinder(assumed).Bind(&v1.Binding{ ObjectMeta: metav1.ObjectMeta{Namespace: assumed.Namespace, Name: assumed.Name, UID: assumed.UID}, Target: v1.ObjectReference{ Kind: "Node", Name: targetNode, }, }) } else { err = fmt.Errorf("Bind failure, code: %d: %v", bindStatus.Code(), bindStatus.Message()) } }
2 overview of the core process of scheduling components
2.1 scheduler initialization
2.1.1 scheduler parameter initialization
The initialization of the parameters of the scheduler has been put into the defaultschedulenoptions. In the future, more methods will be adopted to avoid scattering in the various stages of building parameters
var defaultSchedulerOptions = schedulerOptions{ schedulerName: v1.DefaultSchedulerName, schedulerAlgorithmSource: schedulerapi.SchedulerAlgorithmSource{ Provider: defaultAlgorithmSourceProviderName(), }, hardPodAffinitySymmetricWeight: v1.DefaultHardPodAffinitySymmetricWeight, disablePreemption: false, percentageOfNodesToScore: schedulerapi.DefaultPercentageOfNodesToScore, bindTimeoutSeconds: BindTimeoutSeconds, podInitialBackoffSeconds: int64(internalqueue.DefaultPodInitialBackoffDuration.Seconds()), podMaxBackoffSeconds: int64(internalqueue.DefaultPodMaxBackoffDuration.Seconds()), }
2.1.2 initialization of plug-in factory registry
The initialization of plug-in factory registry is divided into two parts: in tree and out of tree, i.e. the two parts of current version and user-defined
// First register the plug-in registry of the current version registry := frameworkplugins.NewInTreeRegistry(&frameworkplugins.RegistryArgs{ VolumeBinder: volumeBinder, }) // Load user-defined plug-in registry if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil { return nil, err }
2.1.3 event informer callback handler binding
The binding event callback mainly uses AddAllEventHandlers to put all kinds of resource data into the local cache through the SchedulerCache. Meanwhile, for the unscheduled pod(!assignedPod is the pod without binding Node), it is added to the scheduling queue
func AddAllEventHandlers( sched *Scheduler, schedulerName string, informerFactory informers.SharedInformerFactory, podInformer coreinformers.PodInformer, ) {
2.1.4 trigger pod transfer in unscheduled queue
When resources change, for example, service, volume and so on will retest the failed pod before unschedulableQ, and choose to transfer it to activeQ or backoffQ.
func (p *PriorityQueue) MoveAllToActiveOrBackoffQueue(event string) { p.lock.Lock() defer p.lock.Unlock() unschedulablePods := make([]*framework.PodInfo, 0, len(p.unschedulableQ.podInfoMap)) // Get all unscheduled pod s for _, pInfo := range p.unschedulableQ.podInfoMap { unschedulablePods = append(unschedulablePods, pInfo) } // Transfer unscheduled pod to backoff Q queue or active Q queue p.movePodsToActiveOrBackoffQueue(unschedulablePods, event) // Modify the migration scheduler request cycle. When it fails, it will compare whether the pod's moveRequestCycle & gt; = schedulecycle p.moveRequestCycle = p.schedulingCycle p.cond.Broadcast() }
2.1.5 start scheduler
Finally, the scheduler is started, and its core process is in scheduleOne
func (sched *Scheduler) Run(ctx context.Context) { // Synchronous caching will be done first if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) { return } // Start the background scheduled task of the scheduling queue sched.SchedulingQueue.Run() // Start scheduling process wait.UntilWithContext(ctx, sched.scheduleOne, 0) sched.SchedulingQueue.Close() }
2.2 build basic data of scheduling process
2.2.1 get the pod waiting for scheduling
In fact, the internal part is the encapsulation of schedulingQUeue.pop
// Get the pod waiting to be scheduled from the queue podInfo := sched.NextPod() // pod could be nil when schedulerQueue is closed if podInfo == nil || podInfo.Pod == nil { return }
func MakeNextPodFunc(queue SchedulingQueue) func() *framework.PodInfo { return func() *framework.PodInfo { podInfo, err := queue.Pop() if err == nil { klog.V(4).Infof("About to try and schedule pod %v/%v", podInfo.Pod.Namespace, podInfo.Pod.Name) return podInfo } klog.Errorf("Error while retrieving next pod from scheduling queue: %v", err) return nil } }
2.2.2 skip proposed Pod rescheduling
skipPodSchedule is to check whether the current pod can be skipped. One of them is that the pod has been deleted, and the other is that the pod has been proposed to be scheduled to a node. At this time, if it is only a version update, that is, except for the three fields ResourceVersion, Annotations, NodeName, the rest have not changed, there is no need for repeated scheduling
if sched.skipPodSchedule(pod) { return }
Detect the proposed pod repeated scheduling algorithm, if it is equal, no operation will be performed
f := func(pod *v1.Pod) *v1.Pod { p := pod.DeepCopy() p.ResourceVersion = "" p.Spec.NodeName = "" // Annotations must be excluded for the reasons described in // https://github.com/kubernetes/kubernetes/issues/52914. p.Annotations = nil return p } assumedPodCopy, podCopy := f(assumedPod), f(pod) // If the pod information has not changed, it does not need to be updated if !reflect.DeepEqual(assumedPodCopy, podCopy) { return false } return true
2.2.3 build scheduling context
Cycle state and context are generated, in which cycle state is used for data transmission and sharing of online documents in the scheduler cycle, while context is responsible for unified exit coordination management
// Build cycle state and context state := framework.NewCycleState() state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent) schedulingCycleCtx, cancel := context.WithCancel(ctx) defer cancel()
2.3 normal dispatching process
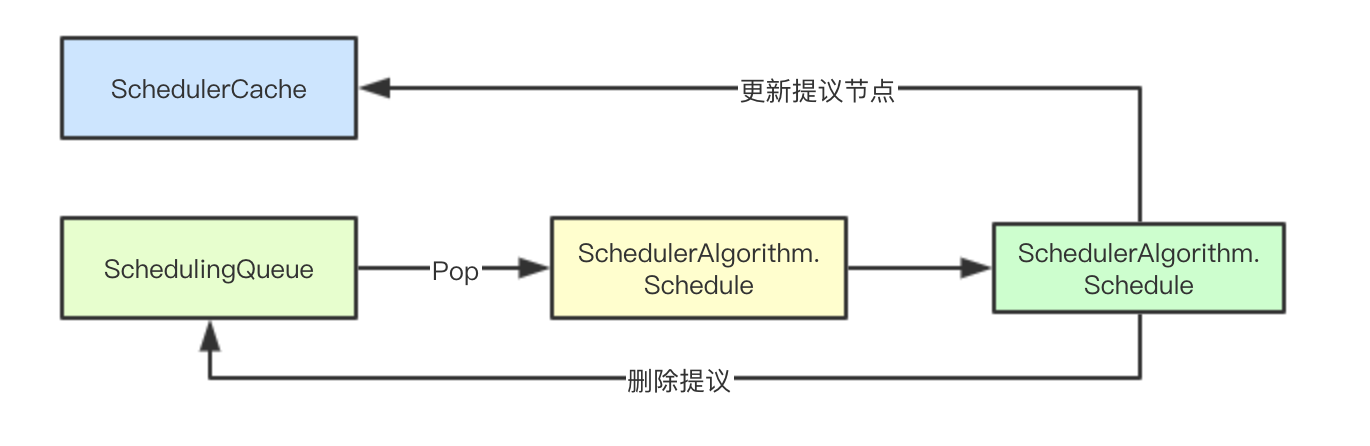 The internal implementation of the underlying dependent data structure ScheduleAlgorithm in the scheduling process has been discussed in detail in the previous analysis. Some calls such as volume bind and framework stage hooks will be omitted here
The internal implementation of the underlying dependent data structure ScheduleAlgorithm in the scheduling process has been discussed in detail in the previous analysis. Some calls such as volume bind and framework stage hooks will be omitted here
2.3.1 execution of scheduling algorithm
Normal scheduling only requires scheduling ScheduleAlgorithm. For details, see the previous article
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, state, pod)
2.3.2 storage proposal Pod proposal node
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
If a Pod is proposed to be stored in a node, it will be added to the SchedulerCache first and removed from the SchedulingQueue to avoid repeated scheduling
func (sched *Scheduler) assume(assumed *v1.Pod, host string) error { assumed.Spec.NodeName = host // Store in the SchedulerCache. In the next scheduling cycle, the pod will occupy the resources of the corresponding node if err := sched.SchedulerCache.AssumePod(assumed); err != nil { klog.Errorf("scheduler cache AssumePod failed: %v", err) return err } // if "assumed" is a nominated pod, we should remove it from internal cache // Remove pod from scheduling queue if sched.SchedulingQueue != nil { sched.SchedulingQueue.DeleteNominatedPodIfExists(assumed) } return nil }
2.4 binding scheduling process
 The bind phase is parallel to the scheduling phase. When the bind is executed, a goroutine will be started to execute the bind operation independently, and the hook calls related to framework and extender will be omitted
The bind phase is parallel to the scheduling phase. When the bind is executed, a goroutine will be started to execute the bind operation independently, and the hook calls related to framework and extender will be omitted
2.4.1 binding Volumes
In the binding process, if the previous volumes are not all bound, the volumes binding operation will be performed first
if !allBound { err := sched.bindVolumes(assumedPod)
2.4.2 bind node through binder
The binding operation is mainly located in the scheduler.bind, which will perform the final node binding
err := sched.bind(bindingCycleCtx, assumedPod, scheduleResult.SuggestedHost, state)
Perform the bind operation mentioned before. This is the place where the apserver is actually manipulated to make the bind request between pod and node
bindStatus := sched.Framework.RunBindPlugins(ctx, state, assumed, targetNode) var err error if !bindStatus.IsSuccess() { if bindStatus.Code() == framework.Skip { // Only when all plug-ins are skip can pod be bound to apiserver err = sched.GetBinder(assumed).Bind(&v1.Binding{ ObjectMeta: metav1.ObjectMeta{Namespace: assumed.Namespace, Name: assumed.Name, UID: assumed.UID}, Target: v1.ObjectReference{ Kind: "Node", Name: targetNode, }, }) } else { err = fmt.Errorf("Bind failure, code: %d: %v", bindStatus.Code(), bindStatus.Message()) } }
2.4.3 modify schedulerCache to set expiration time
The expiration time of the proposed node in the SchedulerCache will be called. If it exceeds the specified expiration time, the node will be removed and the node resource will be released
if finErr := sched.SchedulerCache.FinishBinding(assumed); finErr != nil { klog.Errorf("scheduler cache FinishBinding failed: %v", finErr) }
2.5 preemption process
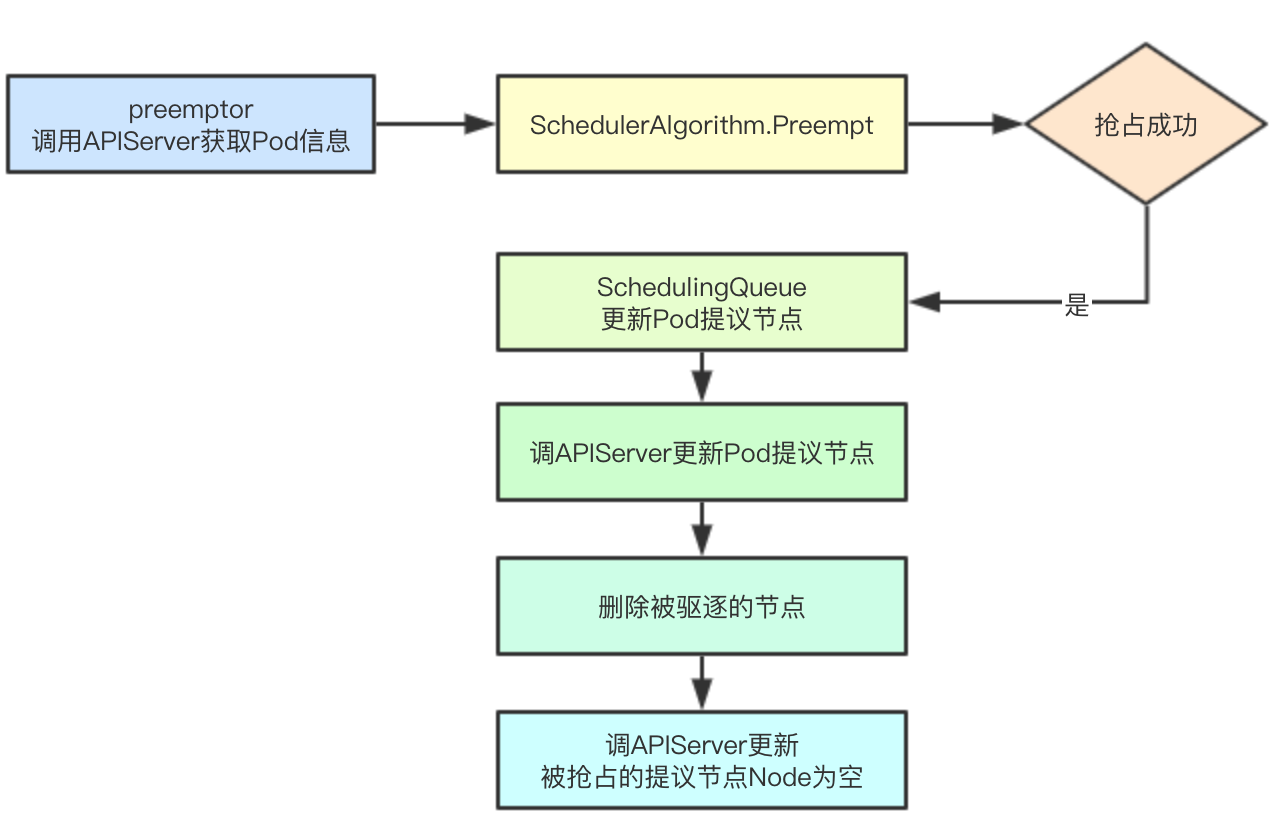
2.5.1 failed Pod queue transfer
If the normal scheduling fails before, a sched.Error will be called in recordSchedulingFailure to transfer the failed pod to backoffQ or unschedulableQ queue.
sched.recordSchedulingFailure(podInfo.DeepCopy(), err, v1.PodReasonUnschedulable, err.Error())
2.5.2 preemption process
If it is a preselected failure and the current scheduler allows the preemptive function, a preemptive scheduling process is called sched.preempt.
if fitError, ok := err.(*core.FitError); ok { // If pre selection fails if sched.DisablePreemption { klog.V(3).Infof("Pod priority feature is not enabled or preemption is disabled by scheduler configuration." + " No preemption is performed.") } else { preemptionStartTime := time.Now() // preemptive scheduling sched.preempt(schedulingCycleCtx, state, fwk, pod, fitError) metrics.PreemptionAttempts.Inc() metrics.SchedulingAlgorithmPreemptionEvaluationDuration.Observe(metrics.SinceInSeconds(preemptionStartTime)) metrics.DeprecatedSchedulingDuration.WithLabelValues(metrics.PreemptionEvaluation).Observe(metrics.SinceInSeconds(preemptionStartTime)) }
2.5.3 get the preemptor
First, obtain the latest pod information of the pod that needs to be preempted at present through apiserver
preemptor, err := sched.podPreemptor.getUpdatedPod(preemptor) if err != nil { klog.Errorf("Error getting the updated preemptor pod object: %v", err) return "", err }
2.5.4 filter by preemption algorithm
The node node to be preempted, the pod to be evicted, and the proposed pod to be evicted are screened by Preempt
node, victims, nominatedPodsToClear, err := sched.Algorithm.Preempt(ctx, state, preemptor, scheduleErr) if err != nil { klog.Errorf("Error preempting victims to make room for %v/%v: %v", preemptor.Namespace, preemptor.Name, err) return "", err }
2.5.5 update Pod information in scheduling queue
If the node preempts a pod successfully, the proposed node information of the preempted node in the queue will be updated, so that the information can be used in the next scheduling cycle
sched.SchedulingQueue.UpdateNominatedPodForNode(preemptor, nodeName)
2.5.6 update Pod's proposed node information
The proposed node information of the node in the apiserver will be called directly here. Why do you want to do this? Because the current pod has preempted some node information on the node, but before the preempted pod is completely deleted from the node, the pod scheduling will still fail, but at this time, the preemption process cannot be called again, because you have already executed the preemption, at this time, you only need to wait for the nodes on the corresponding node to be deleted, then continue to try scheduling again
err = sched.podPreemptor.setNominatedNodeName(preemptor, nodeName)
2.5.7 delete expelled node
Delete the expelled node and call apiserver to operate directly. If it is found that the current pod is still waiting for the plug-in's Allow operation, Reject it directly
for _, victim := range victims { // Call apiserver to delete pod if err := sched.podPreemptor.deletePod(victim); err != nil { klog.Errorf("Error preempting pod %v/%v: %v", victim.Namespace, victim.Name, err) return "", err } // If the victim is a WaitingPod, send a reject message to the PermitPlugin if waitingPod := fwk.GetWaitingPod(victim.UID); waitingPod != nil { waitingPod.Reject("preempted") } sched.Recorder.Eventf(victim, preemptor, v1.EventTypeNormal, "Preempted", "Preempting", "Preempted by %v/%v on node %v", preemptor.Namespace, preemptor.Name, nodeName) }
2.5.8 update the preempted proposal node
For those pod s that have been proposed to be scheduled to the current node, the node will be set to null and the scheduling will be re selected
for _, p := range nominatedPodsToClear { // Clean up these proposed pod s rErr := sched.podPreemptor.removeNominatedNodeName(p) if rErr != nil { klog.Errorf("Cannot remove 'NominatedPod' field of pod: %v", rErr) // We do not return as this error is not critical. } }
3. Panorama of data structure of scheduler core process
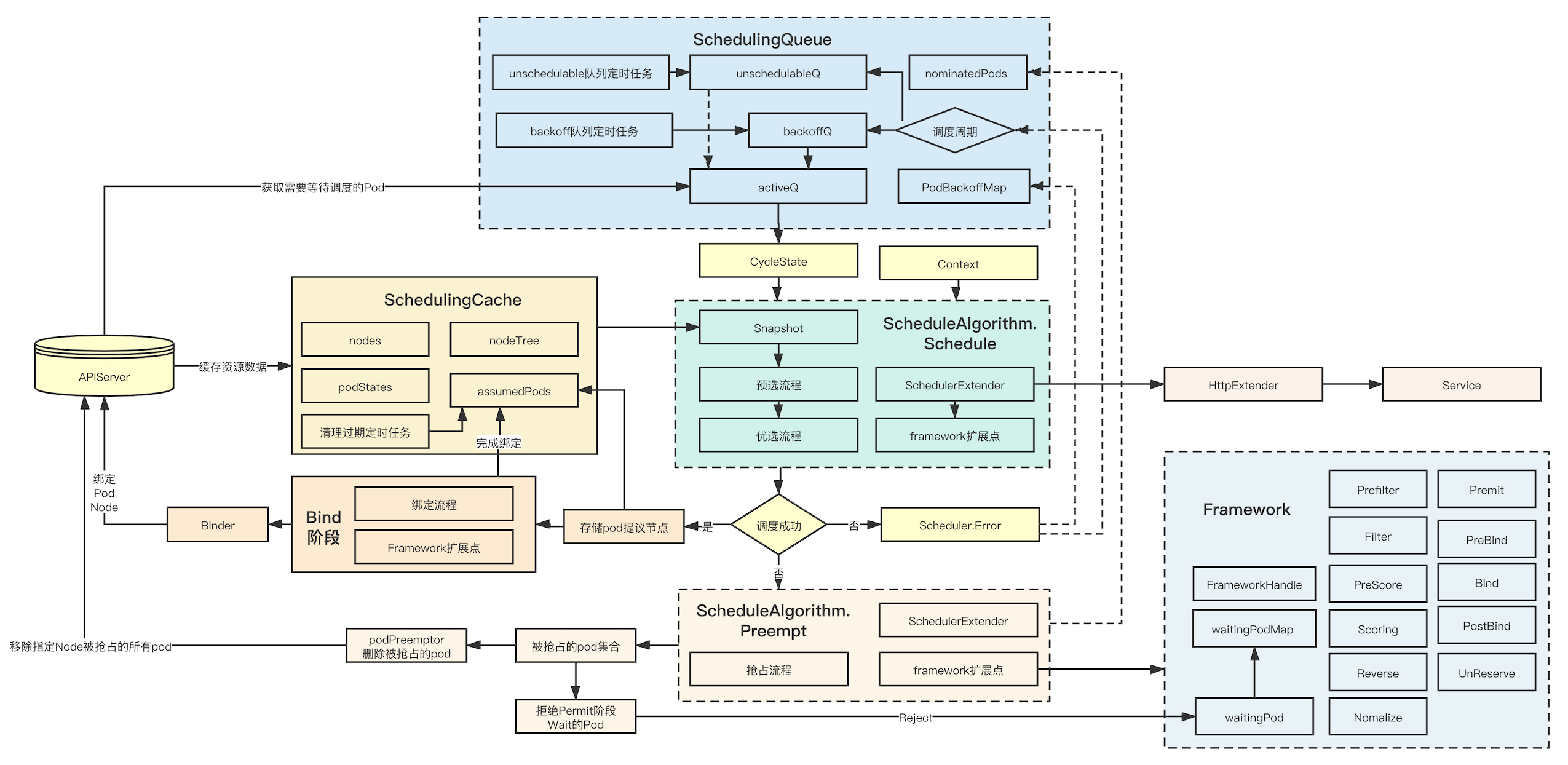 In order to avoid too many lines crossing, I only give the big core process here. At the same time, I simplify the scheduleextender and Framework. In fact, there are calls in multiple stages, but I only draw the data structure and calls at the bottom. This diagram basically contains most of the key data structures and data flows. I hope to give it to the friends who want to learn the scheduler Some help
In order to avoid too many lines crossing, I only give the big core process here. At the same time, I simplify the scheduleextender and Framework. In fact, there are calls in multiple stages, but I only draw the data structure and calls at the bottom. This diagram basically contains most of the key data structures and data flows. I hope to give it to the friends who want to learn the scheduler Some help
4. Summary of scheduler learning stage
It should have been nearly a month since the beginning of reading the scheduler code. Now it's a little understanding of the core process and key data structure of the scheduler. Of course, many specific scheduling algorithms have not been looked at in detail, because the original intention is to understand the architecture design and key data structure of the scheduling
In the process of source code reading, I think the biggest problem may be the understanding of some data structures and algorithm design. Of course, I am also the original design intention of my own conjecture author at present. Fortunately, many scenarios of operation and maintenance development are quite easy to understand, such as service disruption, Pod transfer of scheduling queue, concurrent intention, etc. if someone reads later, they will Different understanding, welcome to exchange, correct some mistakes of my brother
At present, the scheduler should still be under development. At present, the optimization stage has been moved to the Framework, and the subsequent pre selection should also be in the plan. Secondly, the design for the process should also be changing. For example, many nodetrees are also being modified, and the construction of the scheduler is more procedural, but better understood than before. Therefore, those who are interested in reading do not have to choose the old one Version, the new version may be easier
I feel that in addition to the evolution of scheduling process and algorithm management Framework, more optimization is still in the preselection stage, that is, how to select the most appropriate node. The optimization of this process should be divided into two parts: preselection of new Pod and preselection of old Pod, that is, optimization for known and unknown preselection
For known optimizations, more states can be saved and accelerated preselection by saving more data and exchanging space for time For unknown optimization, if you don't consider batch processing tasks, it's actually a false proposition. Because in the actual scenario, you can't get 1000 new services online at the same time, but you can schedule 10000 pods at the same time. In the previous scheduling process, these pods can actually save more state data to accelerate preselection, but more Data state saving may change many designs of the current scheduling system. It should be considered after the whole process and plug-ins of the scheduler are solidified
Well, nonsense. Tomorrow I will start to learn new modules and hope to make more friends. I will organize all articles in this series into pdf. After all, the reading experience of wechat public account is really bad
>Wechat: baxiaoshi2020  >Pay attention to the bulletin number to read more source code analysis articles
>Pay attention to the bulletin number to read more source code analysis articles  >More articles www.sreguide.com
>This article is based on the platform of blog one article multiple sending OpenWrite Release
>More articles www.sreguide.com
>This article is based on the platform of blog one article multiple sending OpenWrite Release