1, Introduction
The latest version 0.9 of hudi came out in September after many calls. hudi can store massive data on the basis of hadoop. It can not only batch process, but also stream process on the data lake, that is, the combination of offline and real-time. It also provides two native semantics:
- 1) Update/Delete records: that is, records in the table can be updated and deleted through hudi. At the same time, it also provides transaction guarantee for write operations.
- 2) Change Streams: you can get the incremental streams of all updated/inserted/deleted records in a given table from a certain point in time.
It not only supports near real-time write and analysis, but also supports SQL read / write, transaction rollback and concurrency control, snapshot query / incremental query, pluggable index, etc. of Spark, Presto, Trino, Hive, etc. For more information, please refer to Apache hudi official website 😄
The compatibility between Hudi 0.8 and flinksql is poor. There is no implementation of connector='hudi '. You can see the implementation of 0.9 on github.
2, Environmental preparation and experiment
1. Environment
- flink1.12.2
- hudi0.9
- hive 3.1.2
- hadoop 3.1.1
2. Start step
In flink-conf.yaml, checkpoint needs to be enabled, and its configuration is as follows:
execution.checkpointing.interval: 3000sec state.backend: rocksdb state.checkpoints.dir: hdfs://hadoop0:9000/flink-checkpoints state.savepoints.dir: hdfs://hadoop0:9000/flink-savepoints
Step 1: start the hadoop cluster and enter $HADOOP_HOME, execute:
./sbin/start-dfs.sh
Before starting the hadoop cluster, it is recommended to synchronize the cluster time first, otherwise an error will be reported when operating hudi later. You can use the following command to synchronize.
ntpdate time1.aliyun.com
Step 2: start the hive node and enter $HIVE_HOME/conf, execute the command:
nohup hive --service metastore nohup hiveserver2 &
After you start hive, you can enter hive normally by executing the command beeline - U JDBC: hive2: / / Hadoop 0:10000. If not, you may need to check the configuration of hive-site.xml or check the startup log.
Step 3: start the flink node and enter $FLINK_HOME/bin, execute the command:
./start-cluster.sh
Before that, you can set the number of task managers and the number of slots. On the official website of hudi, the number of task managers is set to 4. One task manager has one slot. Of course, it can also be determined according to the configuration of the server and the amount of data;
In addition, $Flink_ The following packages need to be introduced under the hmoe / lib / Directory:
flink-connector-hive_2.11-1.12.2.jar flink-hadoop-compatibility_2.11-1.12.2.jar flink-sql-connector-hive-3.1.2_2.11-1.12.2.jar hive-exec-3.1.2.jar hudi-flink-bundle_2.11-0.9.0.jar
3. Experimental process
Step 1: start the Flink SQL client, and click $FLINK_HOME/bin directory execution:
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath` ./sql-client.sh embedded
It is implemented on the official website of Hudi 0.9. / sql-client.sh embedded -j... / lib / hudi-flex-bundle_ The command 2.11-0.9.0.jar shell will report an error when inserting data with flink sql, which causes jobmanager to hang up. At present, this bug has been fixed in Hudi 0.10.
Step 2: create a table and insert data
use catalog myhive; --appoint catalog,You can also leave it unspecified
CREATE TABLE tb_hudi_0901_tmp30 (
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30',
'write.tasks'='1',
'compaction.async.enabled' = 'false',
'compaction.tasks'='1',
'table.type' = 'MERGE_ON_READ' ) ;
INSERT INTO tb_hudi_0901_tmp30 VALUES ('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','part1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','part1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','part1'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','part1'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','part1'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','part1');
The effect is shown in the following figure:
Here, I use off-line compression, compaction.async.enabled set false, the default is to trigger the 5 checkpoint will generate compression plan, and then schedule the corresponding compression task, hdfs can see generate parquet files, this is very important, no parquet file generated, hive is unable to find data. As shown in the figure:

Step 3: create hive external table
- Method 1: INPUTFORMAT is an external table of houdieparquetinputformat type. Only the contents in the parquet data file will be queried, but the newly updated or deleted data cannot be found. count(*) can be performed on mor/cow tables in the hive table.
CREATE EXTERNAL TABLE hudi_tb_test_copy4 ( `_hoodie_commit_time` string, `_hoodie_commit_seqno` string, `_hoodie_record_key` string, `_hoodie_partition_path` string, `_hoodie_file_name` string, `uuid` STRING, `name` STRING, `age` bigint, `ts` bigint) PARTITIONED BY (`partition` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30';
- Method 2: INPUTFORMAT is an external table of type houdieparquetrealtimeinputformat. The written data will be read out in real time, and the Parquet based basic column file and row based Avro log file will be combined and presented. However, it has recently been found that when this type is used, a memory overflow error will be reported when a count(*) operation is performed on the mor table in the hive cluster. A cow type table does not have this problem.
CREATE EXTERNAL TABLE hudi_tb_test_copy4 ( `_hoodie_commit_time` string, `_hoodie_commit_seqno` string, `_hoodie_record_key` string, `_hoodie_partition_path` string, `_hoodie_file_name` string, `uuid` STRING, `name` STRING, `age` bigint, `ts` bigint) PARTITIONED BY (`partition` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30'; alter table hudi_tb_test_copy4 add if not exists partition(`partition`='part1') location 'hdfs://hadoop0:9000/hudi/tb_hudi_0901_tmp30/part1';
In Hudi version 0.9, you don't need to manually create hive external tables, which can be generated automatically. Unfortunately, this link has not been opened yet
Step 4: beeline query data
- Before querying, execute the following commands. The first command is to add the package to the hive environment, which belongs to the current session; If it takes effect permanently, it needs to be in $hive_ Create auxlib / in home, put the package in this directory, and then restart the hive cluster.
The effect is shown in the following figure:add jar hdfs://hadoop0:9000/jar/hudi-hadoop-mr-bundle-0.9.0.jar; set hive.input.format = org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat;
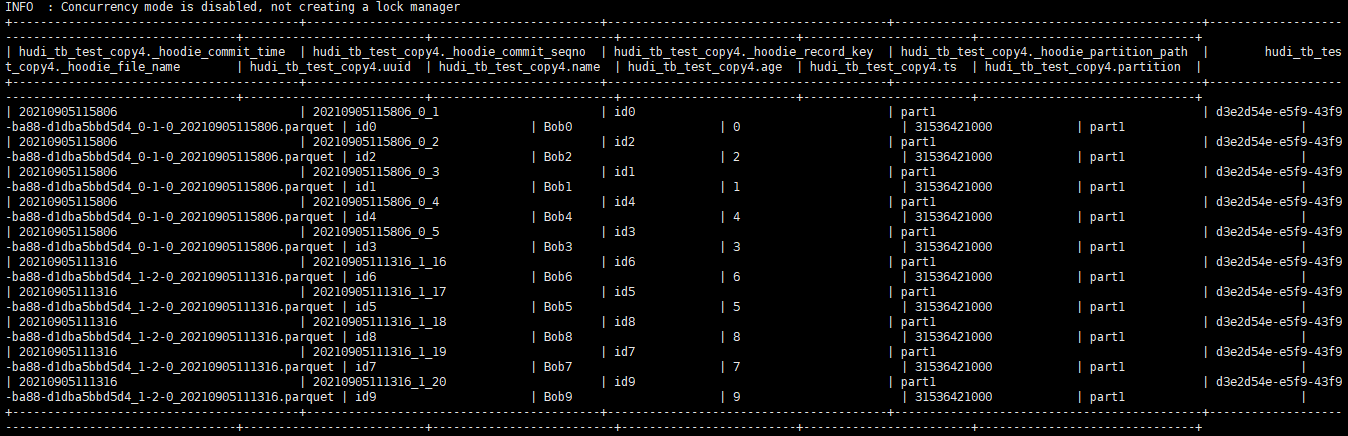
So far, the link of Flink - > Hudi - > hive has been opened, but there are still many problems in the research. For example:- The cow table will have the problem of write amplification. When a large amount of update data is written in the table, the total size of the landing parquet file will be double, and it will be double every time it is written. But this is normal, copy_on_write and copy are unchanged data. hudi copies these data, and then append s the new or updated data to a new file. It is not difficult to understand that the cow table will produce a lot of files.
- The cow table will generate many small parquet files. The number of parquet files seems to be the same as the parameter write.bucket_ Assignment.tasks. After setting, it is found that the number of files has decreased significantly.
- mor type tables schedule compression tasks and generate parquet files after completing checkpoints five times by default. If you don't see parquet files on hdfs, you have to see whether you have completed checkpoints a specified number of times. However, during the test, it is found that even if the checkpoint is completed in the batch environment, the compression task is not triggered, which is very strange; But it is possible in a streaming environment. By the way, the log generated by mor will be cleaned up regularly.
- hoodie.datasource.write.precombine.field: when updating data, if there are two records with the same primary key, the value in this column will determine which record to update. Select a column such as a timestamp to ensure that you select a record with the latest timestamp. This parameter is very useful. By default, the specified field is the ts field, so there should be a ts field in the flink table. If not, you need to specify it.
- read.streaming.check-interval: how often to check whether new operations are generated on the timeline.
3, Pit encountered
- [1] ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation. Solution: add the following contents under hadoop-env.sh file.export JAVA_HOME=/usr/java/jdk1.8.0_181 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export HDFS_ZKFC_USER=root export HDFS_JOURNALNODE_USER=root
- [2] IllegalArgumentException: Following instants have timestamps >= compactionInstant (20210710211157) Instants :[[20210713205004__deltacommit__COMPLETED], [20210713205200__deltacommit__COMPLETED], [20210714091634__deltacommit__COMPLETED]]
Error reason: during completion, ensure that the time of all completed, inflight and requested completion must be less than the current compression time. Solution: check the time of the cluster. The synchronization time is ntpdate time1.aliyun.com - [3] java.lang.NoSuchMethodError: io.javalin.core.CachedRequestWrapper.getContentLengthLong()J
at io.javalin.core.CachedRequestWrapper.(CachedRequestWrapper.kt:22) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at io.javalin.core.JavalinServlet.service(JavalinServlet.kt:34) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at io.javalin.core.util.JettyServerUtil i n i t i a l i z e initialize initializehttpHandler$1.doHandle(JettyServerUtil.kt:72) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
at org.apache.hudi.org.apache.jetty.server.handler.ScopedHandler.nextScope(ScopedHandler.java:203) ~[hudi-flink-bundle_2.11-0.9.0.jar:0.9.0]
Cause of error: errors such as NoSuchMethodError are generally caused by class conflicts. The same class depends on multiple versions, and the runtime class loader does not find the method of this class. Locate the class conflict of ServletRequestWrapper and remove the related classes. - [4] FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat (state=42000,code=40000). Execute the following commands in the hive cluster:
Here are only some impressive questions...add jar hdfs://hadoop0:9000/jar/hudi-hadoop-mr-bundle-0.9.0.jar;
4, References
- [1] https://hudi.apache.org/docs/flink-quick-start-guide/
- [2] https://www.yuque.com/docs/share/01c98494-a980-414c-9c45-152023bf3c17?#
- [3] https://zhuanlan.zhihu.com/p/131210053
- [4] https://cloud.tencent.com/developer/article/1812134
- [5] https://blog.csdn.net/xxscj/article/details/115320772
- [6] https://blog.csdn.net/hjl18309163914/article/details/116057379?spm=1001.2014.3001.5501