Catalog
Overview of HashSet
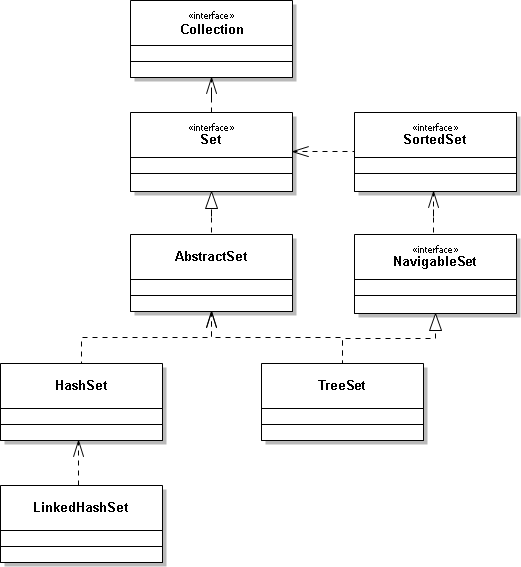
HashSet is an implementation class of Java Set. Set is an interface. In addition to HashSet, there is TreeSet, which inherits Collection. HashSet is a very common set. It is also a knowledge point that programmers often ask during interviews. Here is the structure diagram.
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{}II. HashSet Construction
HashSet has several overload constructions. Let's take a look at them.
private transient HashMap<E,Object> map;
//default constructor
public HashSet() {
map = new HashMap<>();
}
//Add the incoming collection to the HashSet constructor
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//Constructor for defining initial capacity and load factor
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//Constructors that specify only the initial capacity (load factor defaults to 0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}Through the above source code, we found that HashSet is a purse company, TM, it is external work, work received directly thrown to HashMap processing. Because the bottom layer is implemented through HashMap, here's a brief mention:
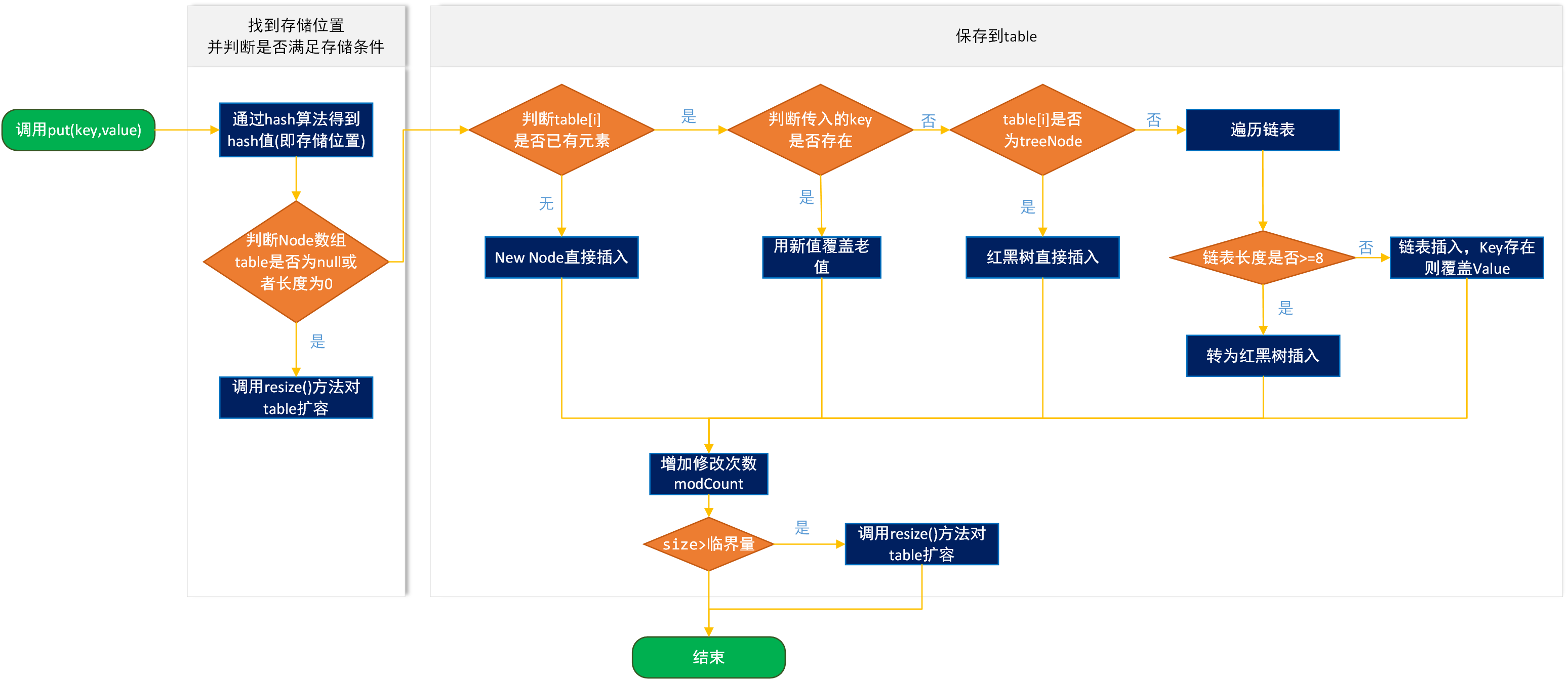
HashMap's data storage is realized by array+linked list/red-black tree. The storage process is to calculate the storage location in the array by hash function. If the location has value, judge whether the key is the same, the same is covered, and the different is put in the linked list corresponding to the element. If the length of the linked list is longer than 8, it will be converted into Red and black trees, if not enough capacity, need to expand (Note: This is only a rough process).
If you don't know the principle of HashMap, you can get to know it first.
HashMap Principle (1) Concept and underlying architecture
HashMap Principle (2) Expansion Mechanism and Access Principle
III. add method
HashSet's add method is implemented by HashMap's put method, but HashMap is a key-value key pair, and HashSet is a set. So how to store it? Let's look at the source code.
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}Looking at the source code, we know that the elements added by HashSet are stored in the key location of HashMap, and value takes the default constant PRESENT, which is an empty object. As for the put method of map, you can see. HashMap Principle (2) Expansion Mechanism and Access Principle.
IV. remove method
HashSet remove method is implemented by HashMap remove method
//The remove method of HashSet
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
//remove method of map
public V remove(Object key) {
Node<K,V> e;
//Find the element's position in the array by hash(key), then call removeNode method to delete it.
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
/**
*
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//Step 1. First, we need to find the exact location of the Node corresponding to the key. First, we need to find the first node corresponding to the array by (n - 1) & hash.
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//1.1 If this node happens to have the same key value, it's lucky to find it.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 Unfortunately, the Node hash found in the array is the same, but the key values are different. Obviously, it's not right. We need to continue traversing.
* Look down.
*/
else if ((e = p.next) != null) {
//1.2.1 If it is a TreeNode type, HashMap is currently stored through an array + red-black tree, traversing the red-black tree to find the corresponding node.
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//1.2.2 If it is a linked list, traverse the linked list to find the corresponding node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//We found the corresponding Node through step 1 above, and now we need to delete it.
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* If it is a TreeNode type, the deletion method is achieved by deleting the red-black tree nodes, which can be specifically implemented by referring to the TreeMap principle.
* And common methods)
*/
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
/**
* In the case of linked lists, when the node found is the first element in the hash position of the array, the element is deleted and the array is directly deleted.
* The reference to the first location points to the next link in the list.
*/
else if (node == p)
tab[index] = node.next;
/**
* If you find a node that is already on the linked list, it is also simple to point the next of the last node of the node to be deleted to the node to be deleted.
* next,Isolate the node to be deleted
*/
else
p.next = node.next;
++modCount;
--size;
//There may be storage structure adjustment after deletion, refer to the remote method in LinkedHashMap How to Ensure Sequence
afterNodeRemoval(node);
return node;
}
}
return null;
}Detailed implementation of removeTreeNode method can be referred to Principle Implementation and Common Methods of TreeMap
The concrete implementation of afterNode Removal method can be referred to. How LinkedHashMap Guarantees Sequence
5. Traverse
HashSet, as a set, has many traversal methods, such as ordinary for loop, enhanced for loop, iterator. Let's look at it through iterator traversal.
public static void main(String[] args) {
HashSet<String> setString = new HashSet<> ();
setString.add("Monday");
setString.add("Tuesday");
setString.add("Wednesday");
setString.add("Thursday");
setString.add("Friday");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}What about the printed results?
Tuesday Wednesday Thursday Friday Monday
Unexpectedly, HashSet is implemented by HashMap. HashMap determines the location of storage by hash(key), which is not storage sequential, so elements traversed by HashSet are not in the order of insertion.
VI. Total
According to my previous plan, each main piece should be written separately, such as collection ArrayList, LinkedList, HashMap, TreeMap and so on. But when I wrote this article about HashSet, I found that after the previous explanation of HashMap, HashSet is really simple. HashSet is a purse company, adding a shell outside HashMap. Does LinkedHashSet add a shell outside LinkedHashMap, and does TreeSet add a shell outside TreeMap? Let's verify it.
Take a look at LinkedHashSet first.
The original structure diagram mentioned that LinkedHashSet is a subclass of HashSet. Let's look at the source code.
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}
The above is all the code of LinkedHashSet. Does it feel like IQ has been denied? It's basically nothing. The constructor calls all the parent classes. Here's how to construct the parent class HashSet.
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}As you can see, like our guesses, there is no need to go further. If you are interested, you can take a look at it. How LinkedHashMap Guarantees Sequence
Look at TreeSet
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
}Indeed, as we suspect, TreeSet also relies entirely on TreeMap for implementation, so if you're interested, you can look at it. Principle Implementation and Common Methods of TreeMap
VII. Summary
I want three chapters to be finished. Although Set implementation is a bit lame, after all, his ancestors are Collection rather than Map. After wearing a layer of clothes on Map implementation class, they become Set. Then they hide in Collection for some purpose. Ha-ha, joke. This paper mainly introduces the principle and main points of HashSet. Meanwhile, LinkedHashSet and TreeSet are briefly introduced. If there are any mistakes, please criticize and correct them. We hope to make progress together. Thank you.