Hive related configuration is required for Spark sql to read and write hive, so hive site is generally used The XML file is placed in the conf directory of spark. Code calls are simple. The key is the source code analysis process and how spark interacts with hive.
1. Code call
Read hive code
SparkSession sparkSession = SparkSession.builder()
.appName("read_hive").enableHiveSupport().getOrCreate();
Dataset<Row> data = sparkSession.sql(sqlText); //The select statement is the data set of the read tableWrite hive code
SparkSession sparkSession = SparkSession.builder()
.appName("write_hive").enableHiveSupport().getOrCreate();
/*Initialize the dataset to write to the hive table
You can read the file sparksession read(). text/csv/parquet()
Or read the JDBC table sparksession read(). format("jdbc"). option(...). load()
*/
Dataset<Row> data = xxx;
data.createOrReplaceTempView("srcTable"); //Create temporary table
sparkSession.sql("insert into tablex select c1,c2... from srcTable") //Write temporary table data to tablex tableNote that if you write a table in parquet format, you need to add a configuration item to the SparkSession to enable hivesql to access it config("spark.sql.parquet.writeLegacyFormat", true). In this way, hiveql can access, otherwise an error will be reported.
2. Analysis of source code
The source code related to spark sql and hive is in the following directory:
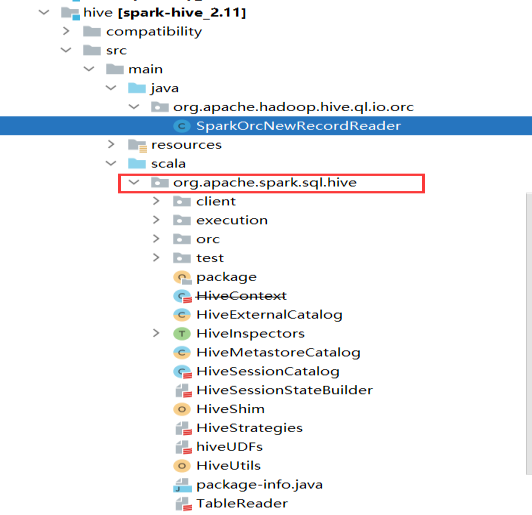
The execution process of spark sql will not be introduced here. The overall architecture is:
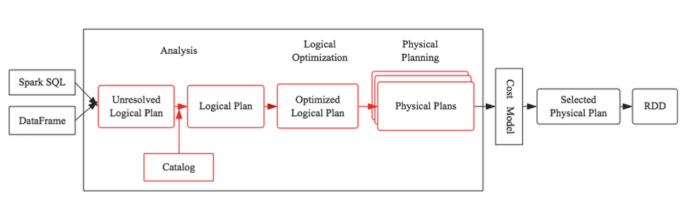
The key operation of reading and writing hive is the enableHiveSupport() method, which will first check whether the hive class has been loaded, and then set the configuration item spark sql. The catalogimplementation value is hive. In this way, when Sparksession initializes the SessionState object, it gets the hive related HiveSessionStateBuilder according to the configuration, and then calls build to create hive aware SessionState.
/**
* Enables Hive support, including connectivity to a persistent Hive metastore, support for
* Hive serdes, and Hive user-defined functions.
*
* @since 2.0.0
*/
def enableHiveSupport(): Builder = synchronized {
if (hiveClassesArePresent) {
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
/**
* State isolated across sessions, including SQL configurations, temporary tables, registered
* functions, and everything else that accepts a [[org.apache.spark.sql.internal.SQLConf]].
* If `parentSessionState` is not null, the `SessionState` will be a copy of the parent.
*
* This is internal to Spark and there is no guarantee on interface stability.
*
* @since 2.2.0
*/
@InterfaceStability.Unstable
@transient
lazy val sessionState: SessionState = {
parentSessionState
.map(_.clone(this))
.getOrElse {
val state = SparkSession.instantiateSessionState(
SparkSession.sessionStateClassName(sparkContext.conf),
self)
initialSessionOptions.foreach { case (k, v) => state.conf.setConfString(k, v) }
state
}
}
/**
* Helper method to create an instance of `SessionState` based on `className` from conf.
* The result is either `SessionState` or a Hive based `SessionState`.
*/
private def instantiateSessionState(
className: String,
sparkSession: SparkSession): SessionState = {
try {
// invoke `new [Hive]SessionStateBuilder(SparkSession, Option[SessionState])`
val clazz = Utils.classForName(className)
val ctor = clazz.getConstructors.head
ctor.newInstance(sparkSession, None).asInstanceOf[BaseSessionStateBuilder].build()
} catch {
case NonFatal(e) =>
throw new IllegalArgumentException(s"Error while instantiating '$className':", e)
}
}
private def sessionStateClassName(conf: SparkConf): String = {
conf.get(CATALOG_IMPLEMENTATION) match {
case "hive" => HIVE_SESSION_STATE_BUILDER_CLASS_NAME
case "in-memory" => classOf[SessionStateBuilder].getCanonicalName
}
}The SessionState is created through basesessionstatebuilder Build()
/**
* Build the [[SessionState]].
*/
def build(): SessionState = {
new SessionState(
session.sharedState,
conf,
experimentalMethods,
functionRegistry,
udfRegistration,
() => catalog,
sqlParser,
() => analyzer,
() => optimizer,
planner,
streamingQueryManager,
listenerManager,
() => resourceLoader,
createQueryExecution,
createClone)
}
}hive aware SessionState is created through HiveSessionStateBuilder. HiveSessionStateBuilder inherits BaseSessionStateBuilder, that is, the corresponding catalog/analyzer/planner will be replaced by variables or methods overridden by HiveSessionStateBuilder.
The HiveSessionCatalog/Analyzer/SparkPlanner is analyzed below
HiveSessionCatalog
SessionCatalog is just a proxy class, which only provides the interface for calling. What really interacts with the underlying system is ExternalCatalog. In the hive scenario, HiveSessionCatalog inherits from SessionCatalog, and HiveExternalCatalog inherits from ExternalCatalog.
You can see the following class descriptions:
/**
* An internal catalog that is used by a Spark Session. This internal catalog serves as a
* proxy to the underlying metastore (e.g. Hive Metastore) and it also manages temporary
* views and functions of the Spark Session that it belongs to.
*
* This class must be thread-safe.
*/
class SessionCatalog(
val externalCatalog: ExternalCatalog,
globalTempViewManager: GlobalTempViewManager,
functionRegistry: FunctionRegistry,
conf: SQLConf,
hadoopConf: Configuration,
parser: ParserInterface,
functionResourceLoader: FunctionResourceLoader) extends Logging {
/**
* Interface for the system catalog (of functions, partitions, tables, and databases).
*
* This is only used for non-temporary items, and implementations must be thread-safe as they
* can be accessed in multiple threads. This is an external catalog because it is expected to
* interact with external systems.
*
* Implementations should throw [[NoSuchDatabaseException]] when databases don't exist.
*/
abstract class ExternalCatalog
extends ListenerBus[ExternalCatalogEventListener, ExternalCatalogEvent] {
import CatalogTypes.TablePartitionSpecIn HiveExternalCatalog, the reading and operation of database, data table, data partition, registration function and other information are completed through HiveClient. Hive Client is the client used to interact with hive. In Spark SQL, it defines various basic operation interfaces, which are specifically implemented as HiveClientimpl objects. However, in actual scenarios, due to historical reasons, multiple hive versions are often involved. In order to effectively support different versions, the implementation of Spark SQL HiveClient is completed by HiveShim by adapting hive version number (HiveVersion).
There is an operation to create HiveClient in HiveExternalCatalog, but in the end, IsolatedClientLoader is called to create it. Generally, spark sql only accesses classes in Hive through HiveClient. In order to better isolate, IsolatedClientLoader divides different classes into three types, and the loading and access rules of different types are different:
-Shared classes: including classes in basic Java, Scala Logging and Spark. These classes are loaded through the ClassLoader of the current context. The results returned by calling HiveClient are visible to the outside.
-Hive classes: classes obtained by loading hive's related Jar package. By default, the ClassLoader that loads these classes is not the same as the ClassLoader that loads shared classes, so these classes cannot be accessed externally
-Barrier classes: generally include HiveClientlmpl and Shim classes, which act as a bridge between shared classes and Hive classes. Spark SQL can access classes in Hive through this class. Each new HiveClientlmpl instance corresponds to a specific Hive version.
Analyzer
The logical execution plan has hive specific analysis rules.
In the hive scenario, there are more ResolveHiveSerdeTable, DetermineTableStats, RelationConversions, and HiveAnalysis rules than the basic ones.
SparkPlanner
Physical execution plans have hive specific strategies.
In the hive scenario, there are more hivetablescans and scripts policies than the basic ones.
The corresponding node of HiveTableScans, HiveTableScanExec, performs scan operations, partition properties and
All filter predicates can be pushed down here.
Spark sql is parsed by Catalyst and finally transformed into a physical execution plan. The tree nodes related to hive are HiveTableScanExec (read data) and InsertIntoHiveTable (write data). The following mainly introduces the implementation principles of these two classes.
HiveTableScanExec
There are two important construction method parameters of HiveTableScanExec,
Relation(HiveTableRelation), partitionPruningPred(Seq[Expression])
The relation ship contains information related to the hive table, while the partition pruning PRED contains predicates related to the hive partition.
Reading is carried out by Hadoop reader (Hadoop tablereader), and it is not executed if the partition table is not
hadoopReader. If makerddfortable is a partitioned table, execute Hadoop reader makeRDDForPartitionedTable.
Create Hadoop RDD in makeRDDForTable according to the data directory location of hive table, and then call
HadoopTableReader.fillObject converts the original Writables data into Rows.
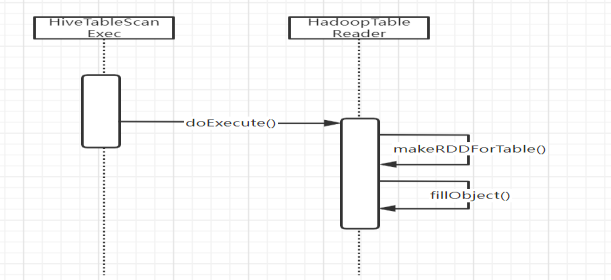
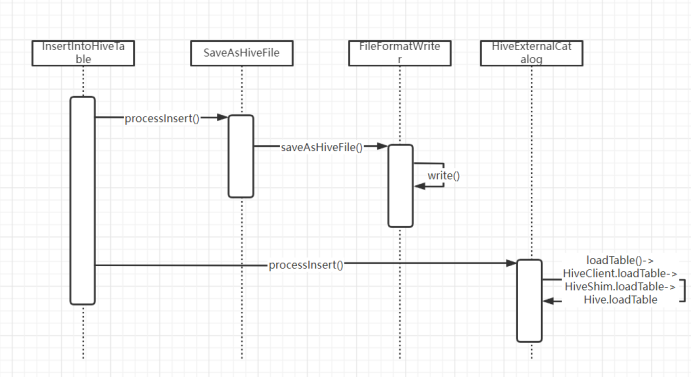
InsertIntoHiveTable
The execution process of InsertIntoHiveTable is to obtain HiveExternalCatalog, hadoop related configuration and hive
Table information, temporary write directory location, etc., and then call the processInsert method to insert, and finally delete the temporary write bit.
Set. In the processInsert method, saveAsHiveFile will be called successively to write the RDD to the temporary directory file, and then call
Use the loadTable method of HiveExternalCatalog (hiveclient.loadTable - > hiveshim.loadTable - > Hive.loadTable, that is, Hive's loadTable method will be called through reflection) to temporarily write the file to the directory location
Load into hive table.
In the above reading and writing process, the mapping between Sparksql Row and Hive data types will be involved. The conversion function is mainly
It is implemented by HiveInspectors.