Operation ①:
- Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network
. Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 4 digits of the student number)
- Output information:
Output the downloaded Url information on the console, store the downloaded image in the weather sub file, and give a screenshot.
(1) Crawl the content of China Meteorological Website
Single thread experiment process:
1. First, check the page through the main url, get all a[href] links under the page, save them all and use them later
Get similar link s to ensure the number of pictures.

(code below)start_url = "http://www.weather.com.cn" header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"} r = requests.get(start_url, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding data = r.text soup = BeautifulSoup(data, "html.parser") # Parsing html a = '<a href="(.*?)" ' linklist = re.findall(re.compile(a), str(soup)) # Regular expression get link2. Define and encapsulate a function to obtain picture links under various URLs, and get the following code:
def imagelist(link): header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"} r = requests.get(link, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding data = r.text soup = BeautifulSoup(data, "html.parser") images = soup.select("img") p = r'img.*?src="(.*?)"' imagelist = [] str1 = re.findall(p, str(images), re.S) # # print(str1) for i in range(len(str1)): if str1[i] not in imagelist: imagelist.append(str1[i])if str1[i] else "" # print(imagelist) # print(len(imagelist)) return imagelist3. Define a function to download pictures (as follows)
def download(link): global count file = "E:/weather/" + "The first" + str(count+1) + "Zhang.jpg" # file means to create a related folder in the specified folder before crawling successfully print("The first" + str(count+1) + "Zhang crawling succeeded") count += 1 urllib.request.urlretrieve(url=link, filename=file)4. Operation results:
Multithreading experiment process:
1. Similar to the single thread experiment, multithreading is used to speed up the loading speed.
First parse the html and get multiple link s in the same waystart_url = "http://www.weather.com.cn" headers= { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"} r = requests.get(start_url, headers=headers) r.raise_for_status() r.encoding = r.apparent_encoding data = r.text soup = BeautifulSoup(data, "html.parser") linklist = [] a = '<a href="(.*?)" ' linklist1 = re.findall(re.compile(a), str(soup)) for i in range(len(linklist1)): if i < 20: linklist.append(linklist1[i]) if linklist1[i] != "javascript:void(0);" else "" # print(len(linklist)) # Here you get all the link s threads=[] for i in linklist: imageSpider(i) # Call link back to the imageSpider function2. Get all img links in a single page
soup=BeautifulSoup(data,"html.parser") images=soup.select("img") for image in images: try: src=image["src"] url=urllib.request.urljoin(start_url,src)The picture link obtained here is src under img, but it is mixed due to the website http://www.weather.com.cn This website, so here's the judgment:
if url not in urls: if not str(url).endswith('.cn'):3. Finally, encapsulate the download function for multi-threaded crawling: first process the url of each picture to obtain the last four bits of each picture link, that is, the format of the picture: finally write to the file
def download(url,count): try: if(url[len(url)-4]=="."): type=url[len(url)-4:] else: type="" req=urllib.request.Request(url,headers=headers) data=urllib.request.urlopen(req,timeout=100) data=data.read() fobj=open("E:\images\\"+str(count)+type,"wb") fobj.write(data) fobj.close() print("downloaded "+str(count)+type+"\n") except Exception as err: print(err)4. Multithreading setting:
T=threading.Thread(target=download,args=(url,count)) T.setDaemon(False) T.start() threads.append(T)for t in threads: t.join() print("The End")5. Operation results:
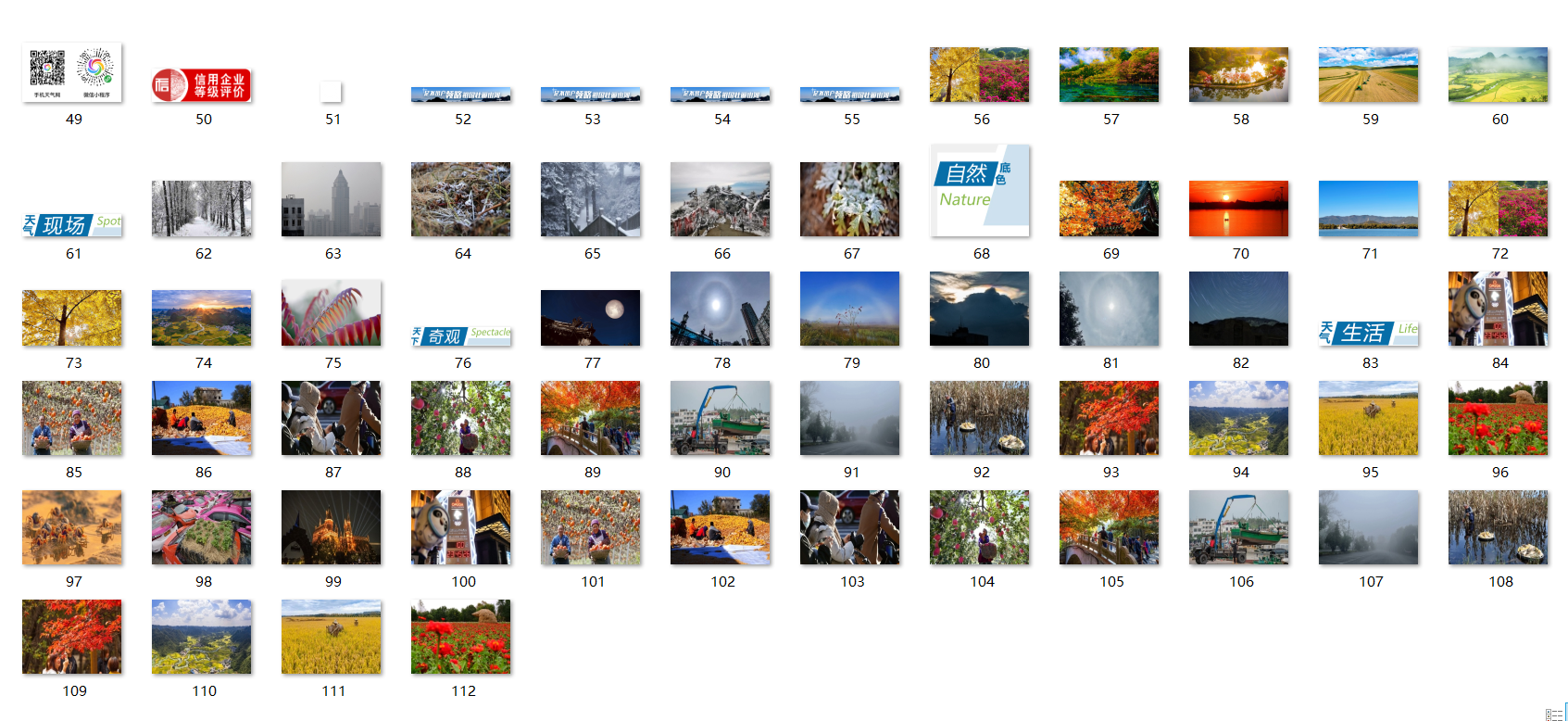
experience:
Through this experiment, I first reviewed the basic operation of downloading pictures from the website and how to use multithreading to speed up the download speed. The difference in this experiment is that you don't crawl pictures in the same single page. First, you need to find all its branches through the main url and download a limited number of pictures. The overall completion is good, and I have mastered it skillfully.
Operation ②:
- Requirements: use the sketch framework to reproduce the operation ①. Output information: Same as operation ①
- Requirements: crawl the Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path.
Candidate sites: https://movie.douban.com/top250
Output information:
My Gitee(2) Download website pictures using the scratch framework
Experimental process:
1. First create the scene project
2. Write myspiders, create myspiders class, and define crawler name and start_urls
class myspides(scrapy.Spider): # Set basic parameters name = 'myspiders' start_urls = ["http://www.weather.com.cn"]2. The same as operation 1, define a function to get picture links
def image(self,link): header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Edg/94.0.992.38"} r = requests.get(link, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding data = r.text soup = bs4.BeautifulSoup(data, "html.parser") images = soup.select("img") p = r'.+?src="(\S+)"' imagelist = [] str1 = re.findall(p, str(images), re.S) # # print(str1) for i in range(len(str1)): if str1[i] not in imagelist: imagelist.append(str1[i]) if str1[i] else "" # print(imagelist) # print(len(imagelist)) return imagelist3. Obtain a[href] in the parse function
a = soup.select("a[href]") links = [] for link in a: links.append(link["href"]) if link["href"] != 'javascript:void(0)' else ""4. Then download the pictures:
for i in images: item["images"]= i item["name"] = "E:/weather/" + str(count+1) + ".jpg" urllib.request.urlretrieve(item["images"], filename=item["name"]) count += 1 if count <=112: break yield item5. In item.py, define the item items used in myspiders, where item["images"] and item["name"] are defined
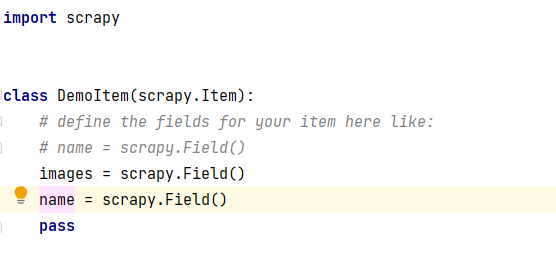
6. Set in the setting.py file:
(note that the web crawler protocol should be ignored here)ROBOTSTXT_OBEY = False
In other settings:

Operation results
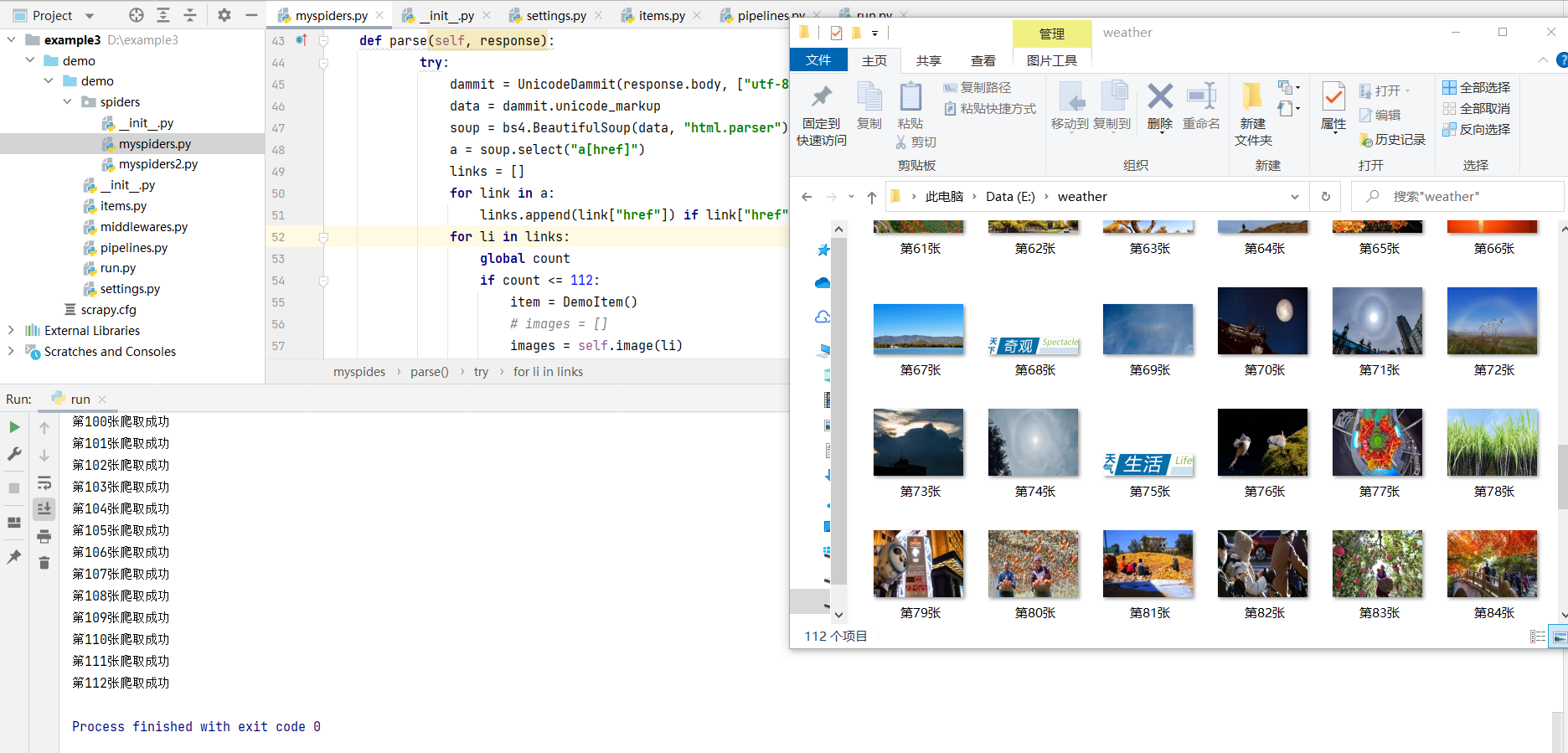
experience
The main idea of the experiment is the same as that in assignment ①. It is mainly required to use the scratch framework for the experiment. It is estimated that the teacher is to let us skillfully use the scratch framework. After this experiment, we are really proficient. See Experiment III for the detailed reasons.
Operation ③:
My GiteeSerial number Movie title director performer brief introduction Film rating Film cover 1 The Shawshank Redemption Frank delabond Tim Robbin Want to set people free 9.7 ./imgs/xsk.jpg 2.... (3) Information about climbing watercress
Experimental process:
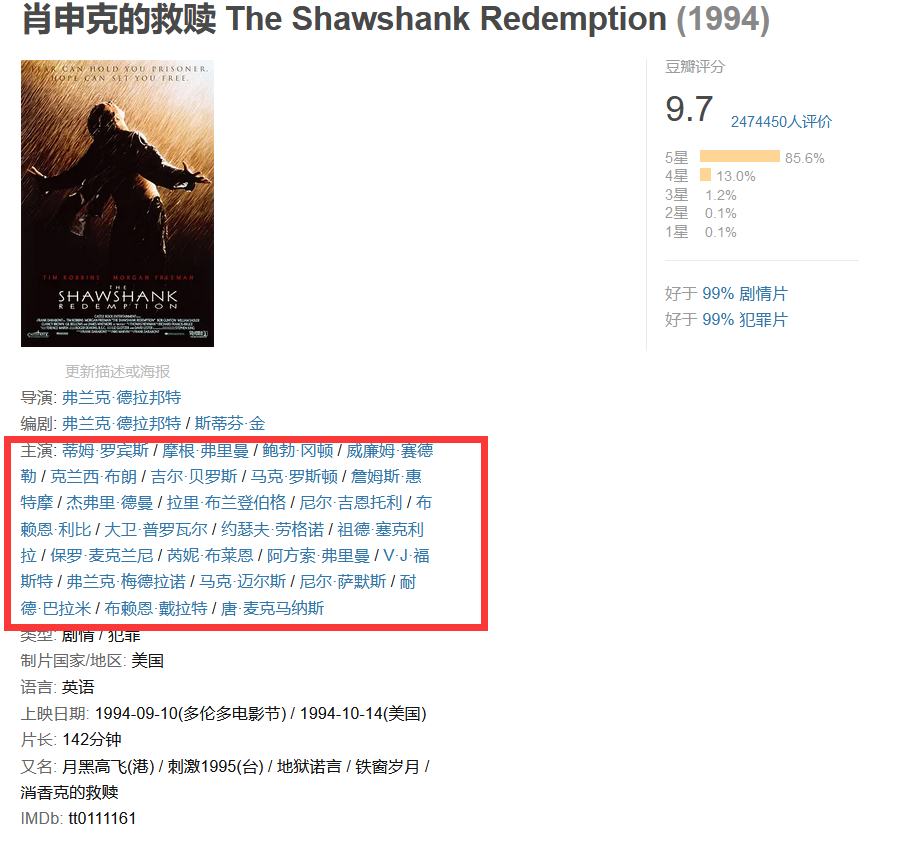
1. First observe the Douban website, and it can be found that the information to be crawled is distributed in the page:
However, a problem has been found here. The list of actors to be crawled is incomplete under this page and the director's name is chaotic. In order to improve the crawler, we decided to crawl this part of the link in the external interface, enter the link and crawl the actor information.
2. After analyzing the web page, we use the sketch framework to crawl the website. First, create the scene project.
3. Write the main function myspiders, create myspides (scratch. Spider): define the crawler name and start_urls
name = 'myspiders' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/top250?start=0']
4. Encapsulate the parse(self, response) function, parse html, and query the data using xpath
title = li.xpath("./div[@class='pic']/a/img/@alt").extract_first() img = li.xpath("./div[@class='pic']/a/img/@src").extract_first() score = li.xpath("./div[@class='info']/div[@class='bd']/div[@class='star']/span[position()=2]/text()").extract_first() rank = li.xpath("./div[@class='pic']/em/text()").extract_first() comment = li.xpath("./div[@class='info']/div[@class='bd']/p[position()=2]/span/text()").extract_first()5. Image downloading:
file = "E:/movie/" + str(item["title"]) + ".jpg" # file means to create a related folder in the specified folder before crawling successfully urllib.request.urlretrieve(item["img"], filename=file) item["file"] = file.strip()
6. Continue to use xpath to crawl the link of the movie column, and enter the link to crawl the name of the director and actor
link = li.xpath("./div[@class='pic']/a/@href").extract_first() soup = bs4.BeautifulSoup(r.text, "html.parser") title = soup.select("div[id='info']") reg = r'<a href=".*?" rel=".*?">(.*?)</a>' actor = re.findall(reg,str(title)) # print(actor[0]) act = soup.select("span[class='actor'] span[class='attrs']")[0].text # print(act) item["actor"] = actor[0] if actor else "" item["star"] = act if act else "" yield item7. Finally, turn pages of myspiders.py:
page = selector.xpath( "//div[@class='paginator']/span[@class='thispage']/following-sibling::a[1]/@href").extract_first() print(page) link_nextpage = "https://movie.douban.com/top250" + str(page) if page: url = response.urljoin(link_nextpage) yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)8. Then process the item.py file and define the required items class
class DemoItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() img = scrapy.Field() link = scrapy.Field() score = scrapy.Field() comment = scrapy.Field() rank = scrapy.Field() actor = scrapy.Field() star = scrapy.Field() file = scrapy.Field() pass9. To handle the settings, I only set 'demo.pipelines.DemoPipeline': 300 at the beginning. I found that no matter how I crawled, there was no content. I struggled to find the reason. Finally, I found that the website crawler protocol was not ignored, so I made the following modifications:
ROBOTSTXT_OBEY = False USER_AGENT = 'demo (+http://www.yourdomain.com)'
10. Write pipelines, mainly for output processing and storage in the database, and create database tables here
if flag: self.con = sqlite3.connect("movie.db") self.cursor = self.con.cursor() try: self.cursor.execute( "create table movie (int Mrank ,Mtitle varchar(256),Mactor varchar(256),Mstar text,Mcomment varchar(256),Mscore varchar(256),Mfile varchar(256),constraint pk_movie primary key (Mrank,Mtitle))") flag = False except: self.cursor.execute("delete from movie")insert data
self.cursor.execute("insert into movie (Mrank,Mtitle,Mactor,Mstar,Mcomment,Mscore,Mfile) values (?,?,?,?,?,?,?)", (item["rank"], item["title"],item["actor"],item["star"], item["comment"], item["score"], item["file"]))When inserting data into the database for the first time, I was surprised to find that several pieces of data were missing. Finally, I found that Mstar varchar(256) was originally set
Part of the data crawled is too long to be inserted. Finally, it is set to Mstar text, which solves the problem.Operation results

You can see the list of actors and all climb down.
experience
In the process of completing this operation, we are faced with the problem that the website is abnormal and inaccessible for many times. It may be that there are too many crawls,

In the future, the html of the page must be cached first. After many tests, the crawler contacts the more complex logic for the first time and climbs into a page again. I feel that after learning selenium, it should not be so troublesome to deal with such problems. Secondly, I'm becoming more and more proficient in scratch. I feel that crawler is still a technology that needs to be practiced frequently. This time, I also use mysql and sqlite databases to store data. I feel similar. Finally, I thank teacher Wu Ling for her guidance in the practice class, otherwise I won't get out of some debug parts...
My Gitee (single)
My Gitee (more)