Assignment 1
-
requirement
Requirements: specify a website and crawl all the pictures in the website, such as China Meteorological Network( http://www.weather.com.cn ). Single thread and multi thread crawling are used respectively. (the number of crawling pictures is limited to the last 3 digits of the student number) -
Output content
Output the downloaded Url information on the console, store the downloaded image in the images subfolder, and give a screenshot.Result display
-
Single thread output information
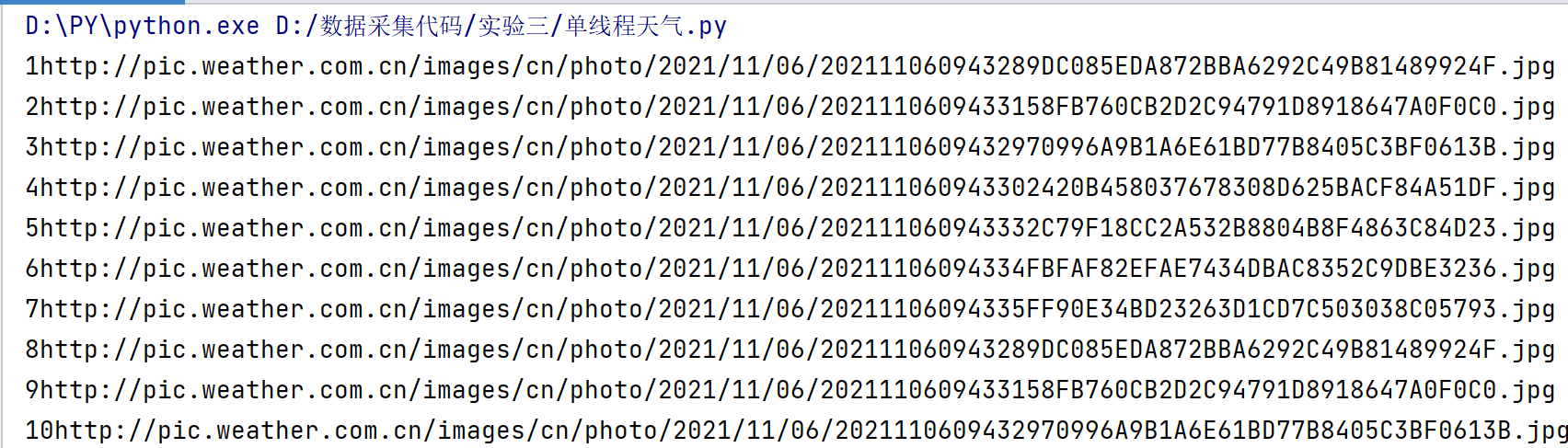
-
Single thread image saving results
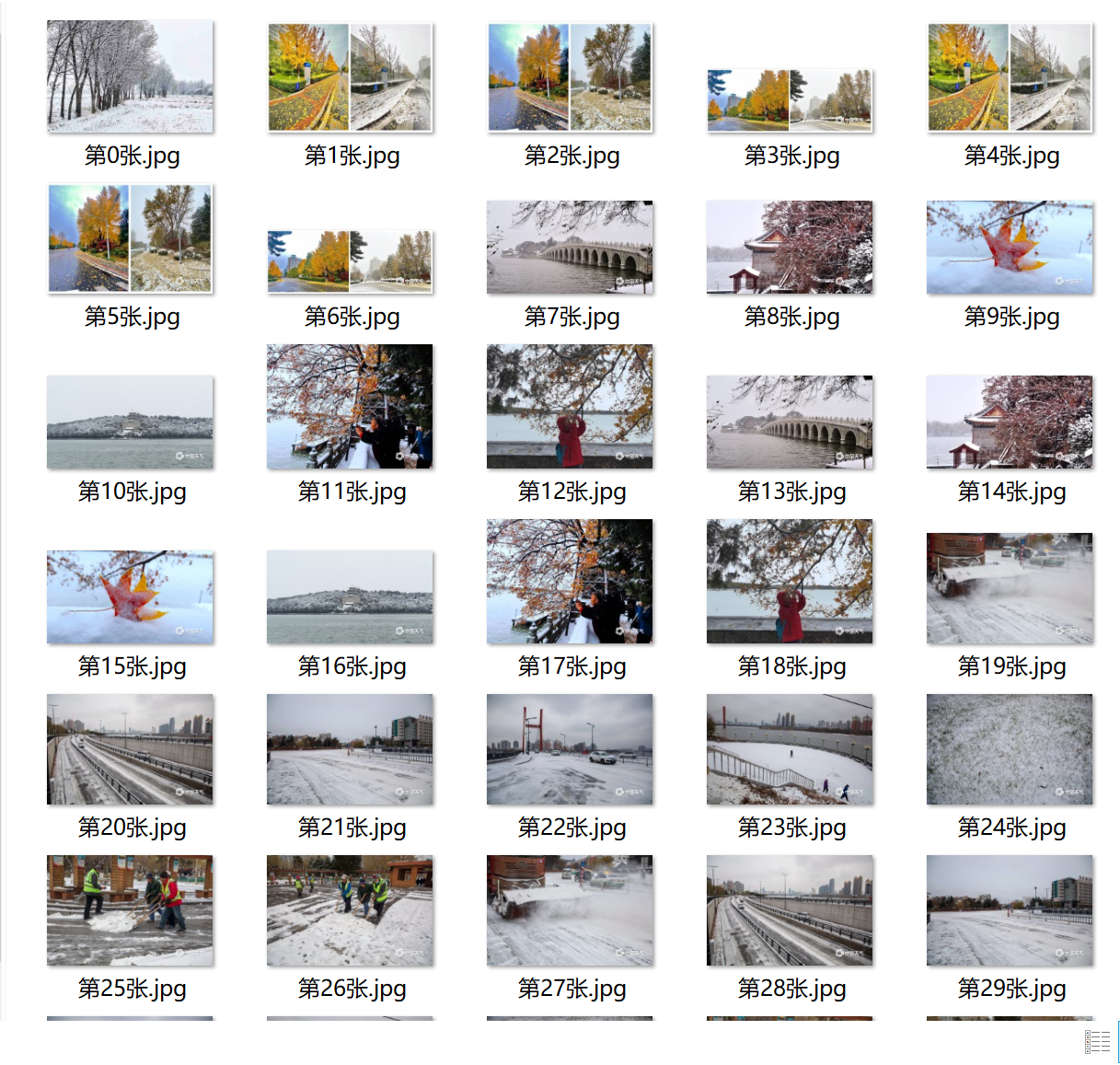
-
Multithreaded output information
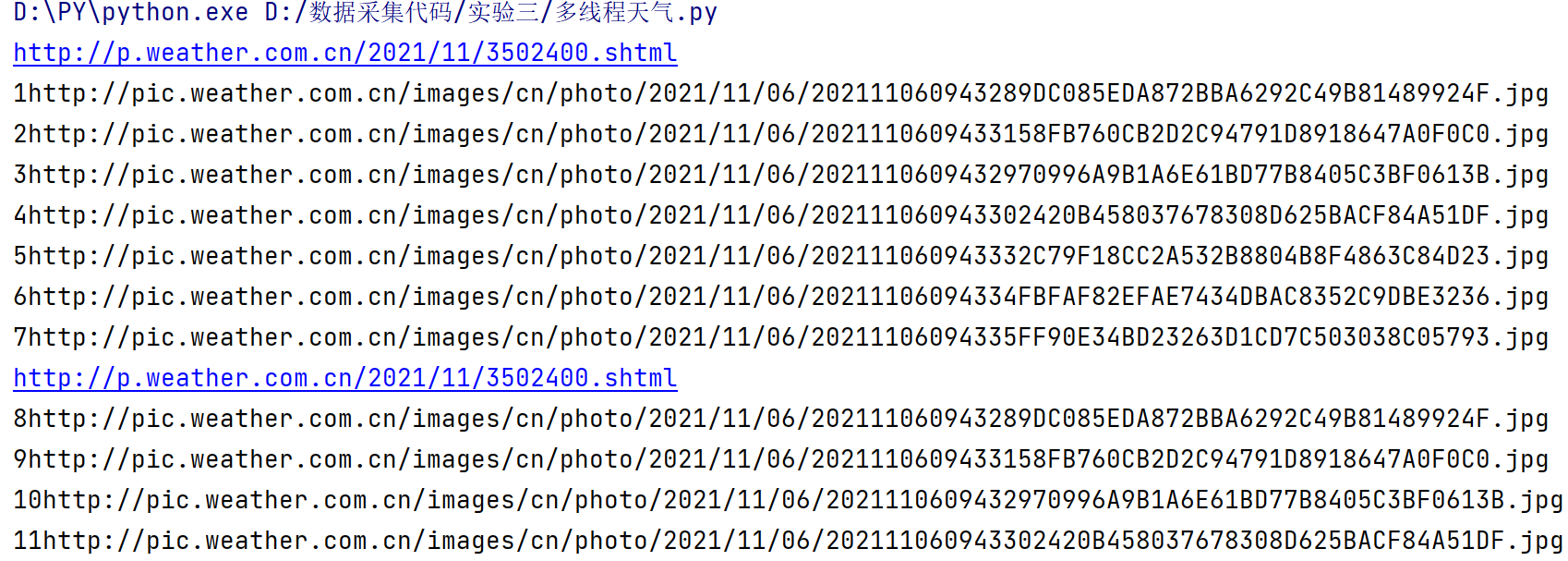
-
Multi thread picture saving results
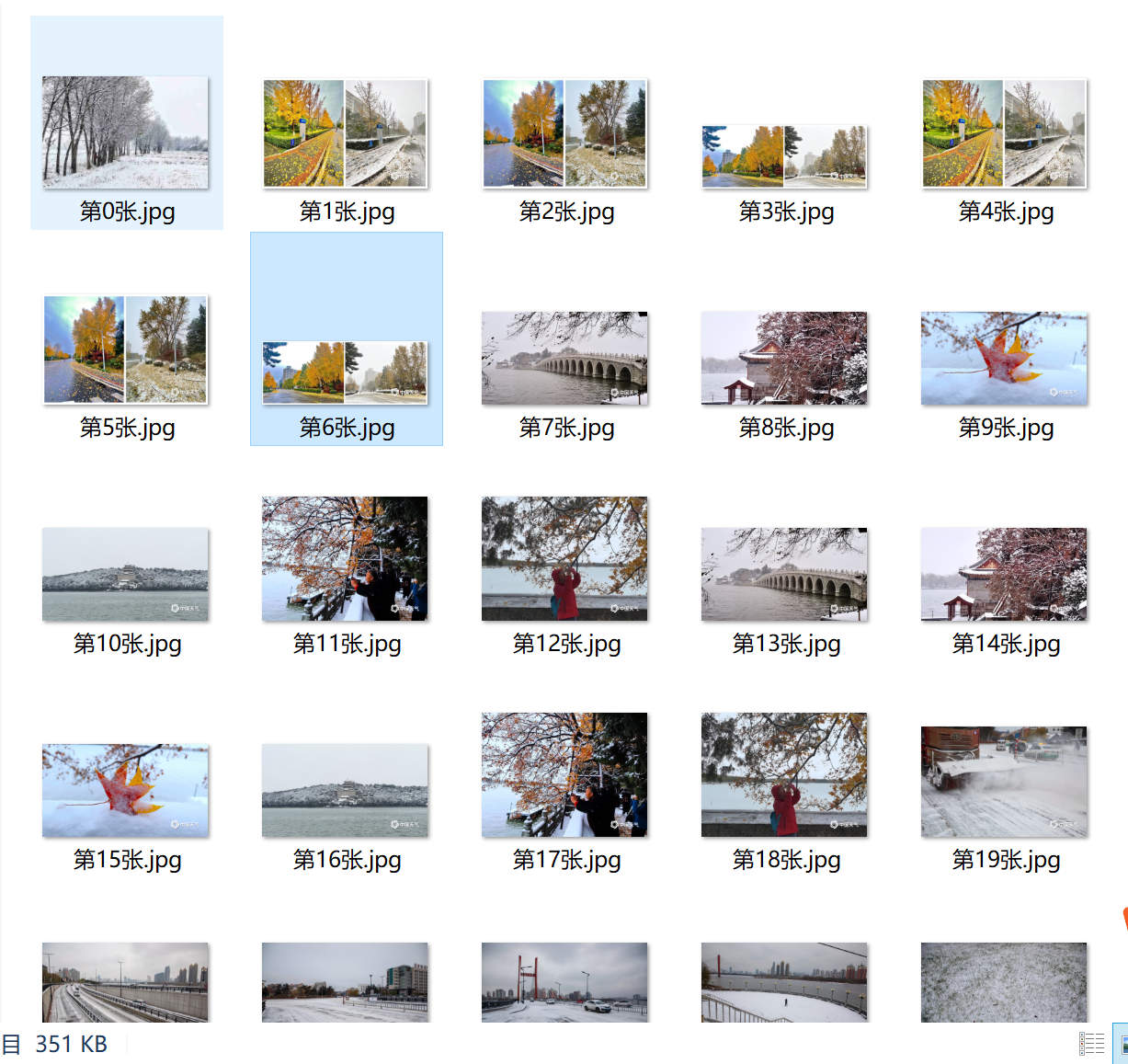
-
Get sub link code of web page
def spider1(url): req = urllib.request.Request(url=url) res = urllib.request.urlopen(req) data = res.read() data = data.decode("utf-8") ##Regular matching list = re.findall(r'target="_blank" href="(.*?)"',data) ##Returns a list of child links return list -
Single thread crawls the picture in the sub link and saves it
def spider2(url): ##Number of saved pictures global sum req = urllib.request.Request(url=url) res = urllib.request.urlopen(req) data = res.read() data = data.decode("utf-8") list = re.findall(r'class="lunboimgages" src="(.*?)"', data) for j in list: print(str(sum)+j) j.replace("\\", "") ##Picture address filename = "D:/weather/" + "The first" + str(sum) + "Zhang" + ".jpg" sum+=1 ##Download and save pictures urllib.request.urlretrieve(j, filename) if (sum == 119): return -
Multi thread crawling sub web page image and saving
def spider2(url): global sum threads = [] req = urllib.request.Request(url=url) res = urllib.request.urlopen(req) data = res.read() data = data.decode("utf-8") list = re.findall(r'class="lunboimgages" src="(.*?)"', data) for j in list: print(str(sum)+j) j.replace("\\", "") filename = "D:/weather/" + "The first" + str(sum) + "Zhang" + ".jpg" sum+=1 ##Set thread T = threading.Thread(target=download, args=(j, filename)) T.setDaemon(False) ##start-up T.start() threads.append(T) if (sum == 119): return for thread in threads: thread.join() -
Code cloud link
----Assignment 1-----experience
-
Because the number of pictures of a web page is not enough, you need to get the pictures of sub web pages
Compared with the previous homework, there is only one more step to obtain the sub web page, which is not very difficult
Note that when setting multithreading, you should traverse the join thread
Assignment 2
-
requirement
Use the sketch framework to reproduce the job ①. -
Output content
Same as operation ①Result display
-
Output information
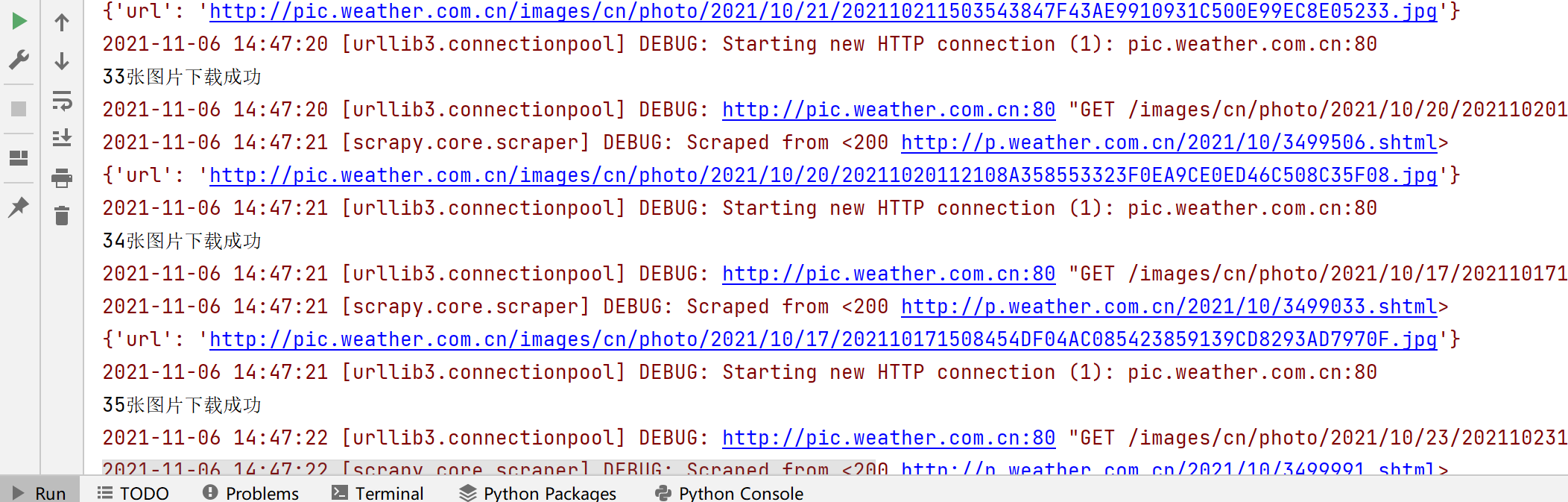
-
Save picture information
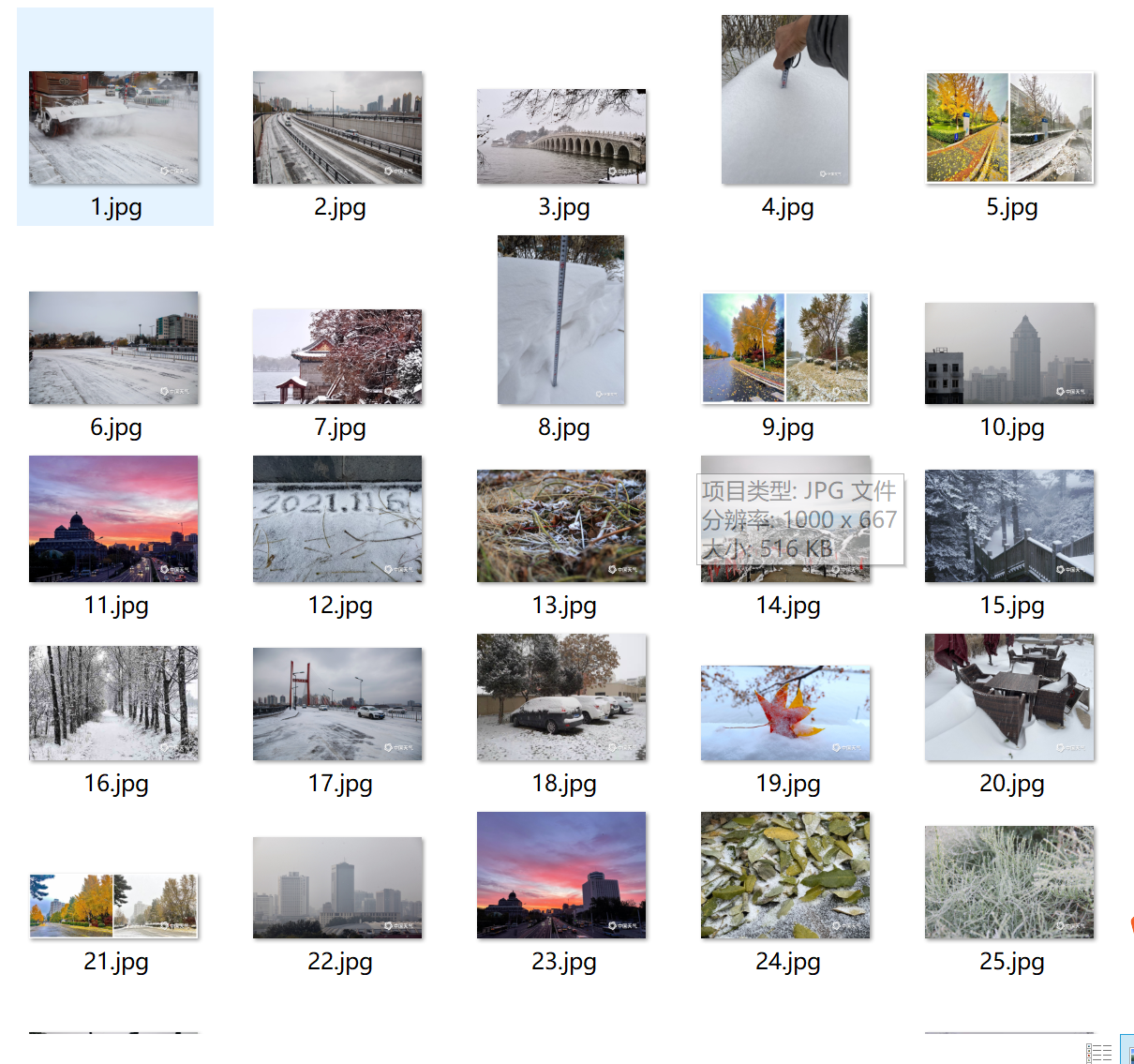
-
Get sub web page code
def start_requests(self): url='http://p.weather.com.cn/tqxc/index.shtml' yield Request(url=url,callback=self.parse1) ##Find sub web page url callback parse2 def parse1(self, response): global sum data = response.body.decode() selector = scrapy.Selector(text=data) urls = selector.xpath("//div[@class='oi']/div[@class ='tu']/a/@href") for i in range(len(urls)): url = urls[i].extract() if sum!=119: yield scrapy.Request(url=url, callback=self.parse2) -
Get the sub web page picture link and save it to item
def parse2(self, response): global sum data = response.body.decode() selector = scrapy.Selector(text=data) # Get picture path pics_url = selector.xpath("//li[@class='child']/a[@class='img_back']/img/@src") for i in pics_url: sum+=1 url = i.extract() item = FirstspiderItem() if sum<119: item['url'] = url yield item pass -
pipelines code
import requests class FirstspiderPipeline: def open_spider(self,spider): self.count=1 def process_item(self, item, spider): url=item['url'] resp=requests.get(url) img=resp.content with open('D:\image\%d' %(self.count)+'.jpg','wb') as f: f.write(img) print('%d Pictures downloaded successfully'%(self.count)) self.count+=1 return item -
item code
class FirstspiderItem(scrapy.Item): url=scrapy.Field() pass -
settings code
BOT_NAME = 'firstspider' SPIDER_MODULES = ['firstspider.spiders'] NEWSPIDER_MODULE = 'firstspider.spiders' FEED_EXPORT_ENCODING = 'gb18030' ITEM_PIPELINES = { 'firstspider.pipelines.FirstspiderPipeline': 300, } IMAGES_STORE='D:\image' IMAGES_URLS_FIELD='url' DEFAULT_REQUEST_HEADERS={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36', 'Cookie': 'GRIDSUMID=c34417679352e71a457dfdfb9b42d24a', 'Accept': 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8', 'Accept-Language':'zh-CN,zh;q=0.9' } ROBOTSTXT_OBEY = False -
Code cloud link
------Assignment 2-----
experience
- The crawl speed of scratch is fast
Crawling to save a picture is similar to multithreading
It is not difficult for the main function to call the callback function by crawling the pipeline link. The key is to set the settings correctly
The frame idea of "crawl" in "sweep" is clearer and clearer
Assignment 3
-
requirement
Crawl Douban movie data, use scene and xpath, store the content in the database, and store the pictures in the imgs path. -
Candidate web address
https://movie.douban.com/top250 -
Output content
Serial number name director performer brief introduction score Picture cover 1 The Shawshank Redemption Frank delabond Tim Robbins Want to set people free 9.7 ./imgs/xsk.jpg 2 ~ ~ ~ ~ ~ ~ Result display
-
database
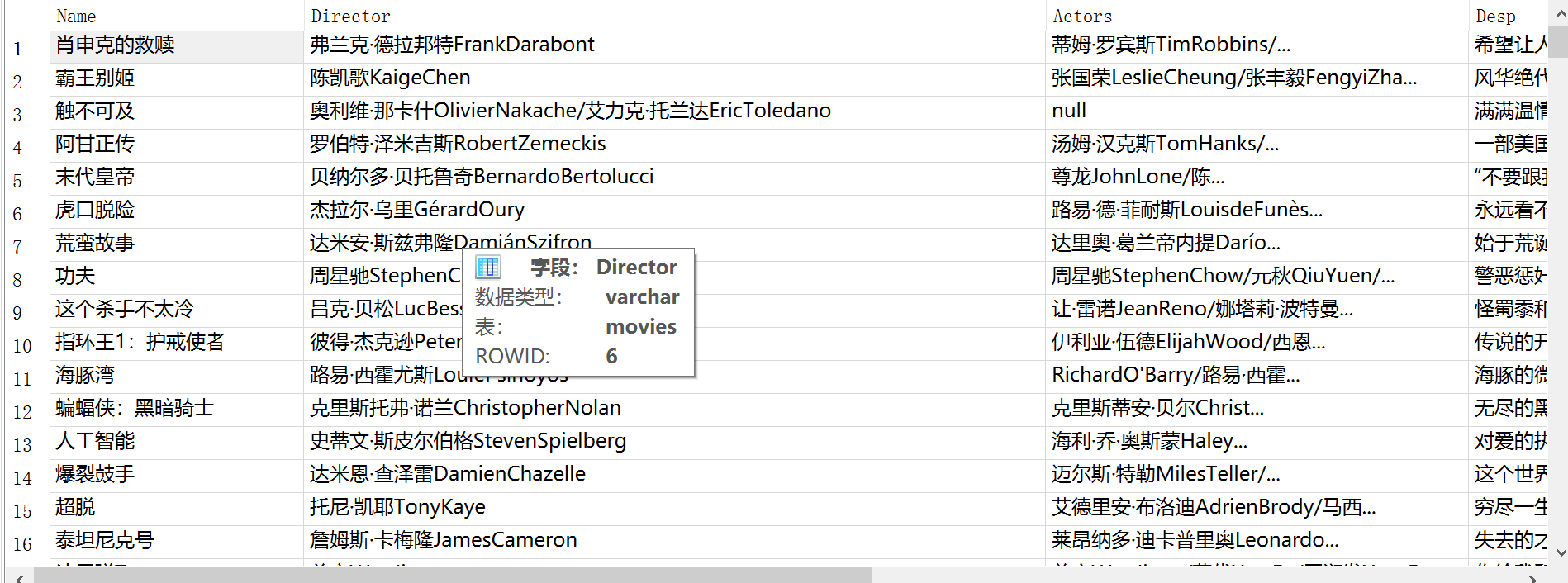
-
Saved pictures

-
moive.py corresponding function
def start_requests(self): ##Page turning processing for i in range(10): time.sleep(random.uniform(0.7,2.0)) url='https://movie.douban.com/top250?start='+str(i*25)+'&filter=' yield Request(url=url,callback=self.parse1) ##xpath selects the corresponding item content and passes it into item def parse1(self, response): global count data = response.body.decode() selector = scrapy.Selector(text=data) # Get each movie item movies = selector.xpath( "//ol[@class='grid_view']/li") ##Select the corresponding label content under each movie label for i in movies: image=i.xpath("./div[@class='item']/div[@class='pic']/a/img/@src").extract_first() name=i.xpath("./div[@class='item']/div[@class='info']/div[@class='hd']//span[@class='title']/text()").extract_first() directorandactor=i.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='']/text()").extract_first() desp=i.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/p[@class='quote']/span/text()").extract_first() grade = i.xpath("./div[@class='item']/div[@class='info']/div[@class='bd']/div/span[@class='rating_num']/text()").extract_first() print(image) ##Regular conversion of directors and leading actors to facilitate subsequent access to corresponding content directorandactor=directorandactor.replace(' ','') directorandactor = directorandactor.replace('\n', '') directorandactor=directorandactor+'\n' director=re.findall(r'director:(.*?)\s',directorandactor) actor=re.findall(r'to star:(.*?)\n',directorandactor) count += 1 item = MovieSpiderItem() #Save to corresponding item item['count']=str(count) item['mname'] = str(name) item['director'] = str(director[0]) if(len(actor)!=0):##The actor may be empty because there is no actor in the animation or the actor cannot be displayed because the director's name is too long item['actor'] = str(actor[0]) else: item['actor']='null' item['story'] = str(desp) item['grade'] = str(grade) item['image'] = str(image) yield item pass -
Settings settings
import os BOT_NAME = 'movie_spider' SPIDER_MODULES = ['movie_spider.spiders'] NEWSPIDER_MODULE = 'movie_spider.spiders' FEED_EXPORT_ENCODING = 'gb18030' ITEM_PIPELINES = { 'movie_spider.pipelines.MovieSpiderPipeline': 300, } IMAGES_STORE='D:\PY\movie_spider\image' IMAGES_URLS_FIELD='image' HTTPERROR_ALLOWED_CODES = [301] DEFAULT_REQUEST_HEADERS={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36' } ROBOTSTXT_OBEY = False -
pipelines class
class MovieDB: # Establish a database link. If there is no corresponding database, create it def openDB(self): self.con = sqlite3.connect("movies.db") self.cursor = self.con.cursor() try: ##Database creation command self.cursor.execute("create table movies " "(Name varchar(20)," "Director varchar(30),Actors varchar(60)," "Desp varchar(100),Grade varchar(8),ImgPath varchar(64))") except: self.cursor.execute("delete from movies") ##close database def closeDB(self): self.con.commit() self.con.close() ##Insert operation def insert(self, Name, Director, Actors, Desp, Grade, ImgPath): try: self.cursor.execute("insert into movies (Name,Director,Actors,Desp,Grade,ImgPath) values (?,?,?,?,?,?)", ( Name, Director, Actors, Desp, Grade, ImgPath)) except Exception as err: print(err) ##Pipeline class class MovieSpiderPipeline: def open_spider(self, spider): self.count = 1 self.db = MovieDB() self.db.openDB() ##Save picture and write to database def process_item(self, item, spider): # Download pictures path = r"D:\PY\movie_spider\image" url = item['image'] resp = requests.get(url) # Gets the binary text of the specified picture img = resp.content fm_path= 'image\image%d' % self.count + '.jpg' with open(path + '\\image%d' % self.count + '.jpg', 'wb') as f: f.write(img) print("The first%d Pictures downloaded successfully" % self.count) self.count += 1 # Save to database self.db.insert( item['mname'], item['director'], item['actor'], item['story'], item['grade'], fm_path) return item def close_spider(self, spider): self.db.closeDB() print("End crawling") -
Code cloud link
-----Assignment 3-----
experience
- Originally, it was planned to jump to a separate movie introduction page to crawl the content according to the picture link, but Douban on these pages will set anti crawl, and the page content obtained by python is different from that seen by the browser. Moreover, it was blocked ip after climbing several times, so it was abandoned
This leads to the lack of some actors, so we can only give up this small part of the content for the time being
The code of the database part is written quickly before reference.
Other codes are similar to operation 2. In the future, we should find a way to do anti crawling crawler