Atomic operation
Usually, a = a + 1 in our code contains three instructions after being translated into assembly:
ldr x0, &a add x0,x0,#1 str x0,&a
Namely (1) Read a variable from memory to X0 register (2)X0 register plus 1 (3) Write X0 to memory a
Since there are three instructions, they may be concurrent, which means that the returned result may not be expected.
Then, in the operating system of linux kernel, the function of accessing atomic variables is provided to solve the above problems. The API s of some atomic operations are as follows:
atomic_read atomic_add_return(i,v) atomic_add(i,v) atomic_inc(v) atomic_add_unless(v,a,u) atomic_inc_not_zero(v) atomic_sub_return(i,v) atomic_sub_and_test(i,v) atomic_sub(i,v) atomic_dec(v) atomic_cmpxchg(v,old,new)
So how does the operating system (just software) ensure atomic operation? (it still depends on hardware). What is the principle of hardware?
The above API functions are actually called at the bottom as follows__ lse_ atomic_ add_ The encapsulation of the return ##name macro. The core of this code is the ldadd instruction, which is armv8 1. Added LSE (Large System Extension) feature.
(linux/arch/arm64/include/asm/atomic_lse.h)
static inline int __lse_atomic_add_return##name(int i, atomic_t *v) \
{ \
u32 tmp; \
\
asm volatile( \
__LSE_PREAMBLE \
" ldadd" #mb " %w[i], %w[tmp], %[v]\n" \
" add %w[i], %w[i], %w[tmp]" \
: [i] "+r" (i), [v] "+Q" (v->counter), [tmp] "=&r" (tmp) \
: "r" (v) \
: cl); \
\
return i; \
}What if the system does not have LSE extension, that is, armv8 0. The prototype of its implementation is as follows. The core of this code is ldxr and stxr instructions.
(linux/arch/arm64/include/asm/atomic_ll_sc.h)
static inline void __ll_sc_atomic_##op(int i, atomic_t *v)\
{ \
unsigned long tmp; \
int result; \
\
asm volatile("// atomic_" #op "\n" \
__LL_SC_FALLBACK( \
" prfm pstl1strm, %2\n" \
"1: ldxr %w0, %2\n" \
" " #asm_op " %w0, %w0, %w3\n" \
" stxr %w1, %w0, %2\n" \
" cbnz %w1, 1b\n") \
: "=&r" (result), "=&r" (tmp), "+Q" (v->counter) \
: __stringify(constraint) "r" (i)); \
}So in armv8 Before 0, for example, how was armv7 implemented? As shown below, the core of this code is the ldrex and strex instructions.
(linux/arch/arm/include/asm/atomic.h)
static inline void atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp;
int result; \
\
prefetchw(&v->counter); \
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
}Summary:
In the early days, the mechanism of exclu and exclu has changed, but the mechanism of exclu and exclu has changed to that of exclu and exclu. However, in a large system, there are many processors and the competition is fierce. Using exclusive storage and loading instructions may take many attempts to succeed, and the performance becomes very poor. In arm v8 In order to solve this problem, ldadd and other related atomic operation instructions are added.
spinlock spin lock
Design of early spinlock
The early design of spinlock is that the lock owner sets the value of the lock to 1 when adding the lock and 0 when releasing the lock. The disadvantage of this is that the process of preempting the lock first can not preempt the lock, and the subsequent process may be able to obtain the lock. The reason for this is that the processes that preempt first and those that preempt later do not have a sequential relationship when preempting the lock. In the end, the cpu node closest to the memory where the lock is located has more opportunities to preempt the lock, and the node far from the memory where the lock is located may not preempt all the time.
New spinlock design
In order to solve the unfair problem of spinlock, after linux 2.6.25 kernel, spinlock adopts a spinlock mechanism of "FIFO ticket based" algorithm, which can well realize the idea of first come, first seize. The specific methods are as follows:
- The core fields of spinlock are owner and next. Initially, owner=next=0
- When the first process preempts spinlock, it will save the value of next locally in the process function, that is, next=0, and add 1 to the next field of spinlock;
- When the local next of the process obtaining spinlock is equal to the owner of spinlock, the process obtains spinlock;
- Since the local next of the first process is 0 and the owner of spinlock is 0, the first CPU obtains spinlock;
- Then, when the second process preempts spinlock, the next value of spinlock is 1, save it locally, and then add 1 to the next field of spinlock. The owner field of spinlock is still 0, and the local next of the second process is not equal to the owner of spinlock, so spin and wait for spinlock all the time;
- The third process preempts spinlock, obtains the local next value of 2, and then adds 1 to the next field of spinlock. At this time, the owner field of spinlock is still 0, so the third process spins and waits.
- After the first process processes the critical area, it releases spinlock. The operation is to add 1 to the owner field of spinlock;
- Since the second and third processes are still waiting for spinlock, they will constantly obtain the owner field of spinlock and compare it with their local next value. When the second process finds that its next value is equal to the owner field of spinlock (at this time, next == owner == 2), the second process obtains spinlock. The local next value of the third process is 3, which is not equal to the owner field of spinlock, so continue to wait;
- Only when the second process releases spinlock, the owner field of spinlock will be increased by 1, and the third process will have the opportunity to obtain spinlock.
Let me give an example as follows:
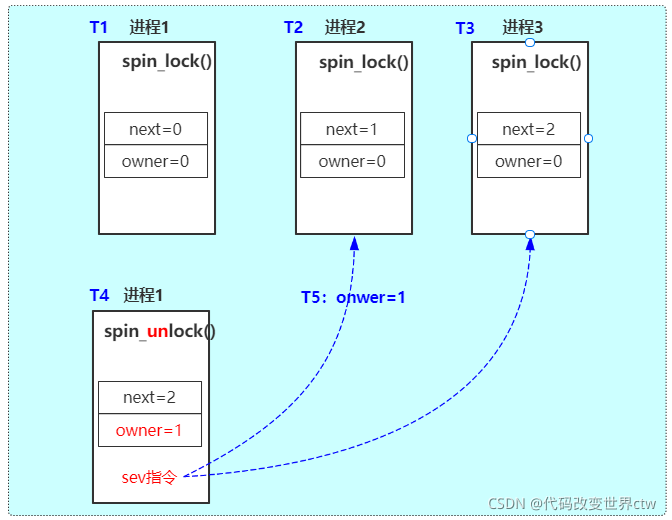
T1: process 1 calls spin_lock, when next = 0 and owner = 0, obtain the lock in arch_ spin_ In the underlying implementation of lock(), next++ T2: process 2 calls spin_lock, at this point, next=1, owner=0 did not get the lock, while(1) called wfe instruction standby there, waiting for owner==next to be established. T3: process 3 calls spin_lock, at this point, next=2, owner=0 did not get the lock, while(1) called wfe instruction standby there, waiting for owner==next to be established. T4 & T5: process 1 calls spin_unlock, at this time, owner + +, i.e. owner=1, then call the sev instruction to make process 2 and process 3 exit the standby state, go through the while(1) process, and recheck the owner==next condition. At this time, the condition of process 2 is established, and process 3 continues to wait. Process 2 obtains the lock and process 3 continues to wait.
Implementation of SpinLock in Linux Kernel
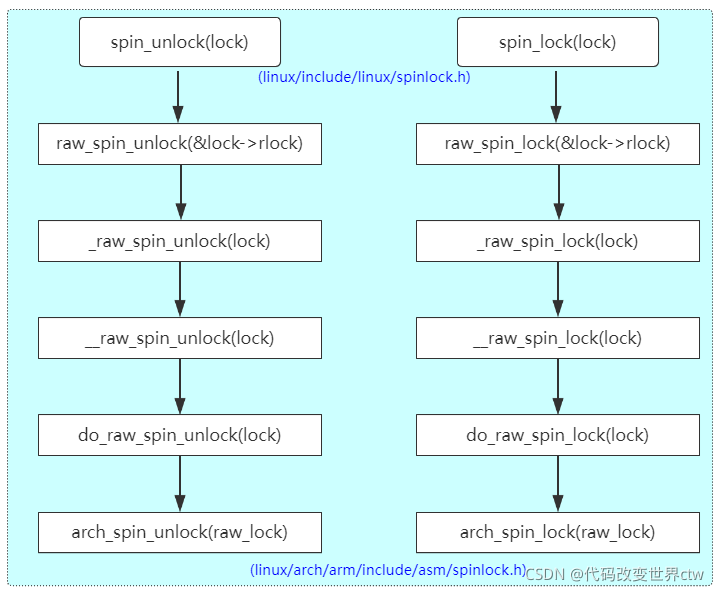
(linux/include/linux/spinlock.h)
static __always_inline void spin_unlock(spinlock_t *lock)
{
raw_spin_unlock(&lock->rlock);
}
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}(linux/include/linux/spinlock.h) #define raw_spin_lock_irq(lock) _raw_spin_lock_irq(lock) #define raw_spin_lock_bh(lock) _raw_spin_lock_bh(lock) #define raw_spin_unlock(lock) _raw_spin_unlock(lock) #define raw_spin_unlock_irq(lock) _raw_spin_unlock_irq(lock) #define raw_spin_lock(lock) _raw_spin_lock(lock)
(linux/kernel/locking/spinlock.c)
#ifdef CONFIG_UNINLINE_SPIN_UNLOCK
void __lockfunc _raw_spin_unlock(raw_spinlock_t *lock)
{
__raw_spin_unlock(lock);
}
EXPORT_SYMBOL(_raw_spin_unlock);
#endif
#ifndef CONFIG_INLINE_SPIN_LOCK
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
EXPORT_SYMBOL(_raw_spin_lock);
#endif(linux/include/linux/spinlock_api_smp.h)
static inline void __raw_spin_unlock(raw_spinlock_t *lock)
{
spin_release(&lock->dep_map, _RET_IP_);
do_raw_spin_unlock(lock);
preempt_enable();
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}(linux/include/linux/spinlock.h)
static inline void do_raw_spin_unlock(raw_spinlock_t *lock) __releases(lock)
{
mmiowb_spin_unlock();
arch_spin_unlock(&lock->raw_lock);
__release(lock);
}
static inline void do_raw_spin_lock(raw_spinlock_t *lock) __acquires(lock)
{
__acquire(lock);
arch_spin_lock(&lock->raw_lock);
mmiowb_spin_lock();
}For arch_spin_lock(),arch_ spin_ The underlying implementation of unlock () has been changing in different kernel versions.
For kernel4 The core of this version is ldaxr, ldaxr exclusive instruction and stlrh release instruction
(linux/arch/arm64/include/asm/spinlock.h)
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
" nop\n"
" nop\n"
" nop\n"
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" nop\n"
" staddlh %w1, %0")
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}
Big release of 5T technical resources! Including but not limited to: C/C + +, Arm, Linux, Android, artificial intelligence, MCU, raspberry pie, etc. In the above, everyone is a geek. The official account will be returned to peter for free.

Remember to click to share, praise and watch, and recharge me