Core knowledge points
1.set is an unordered and unrepeated sequence
2. You can create a set with {} or set() function
3. The collection stores immutable types (string, number, tuple)
Note: to create an empty collection, you must use set() instead of {}, because {} is used to create an empty dictionary
Detailed explanation of Python list, tuple, dict and set
Python Sequence: refers to a set of data arranged in a specific order. They can occupy a continuous memory or be scattered into multiple memory blocks. The Sequence types in Python include list, tuple, dict ionary and set.
Data is ordered: lists and tuples are similar. They store elements in order. All elements occupy a piece of continuous memory, and each element has its own index. Therefore, the elements of lists and tuples can be accessed through the index. The difference between them is that lists can be modified, while tuples cannot be modified.
Data is out of order: the data stored in dictionary (dict) and set (set) are out of order, and each element occupies different memory. Among them, dictionary elements are saved in the form of [key value].
Python set collection details
The set in Python, like the set concept in mathematics, is used to save non repeating elements, that is, the elements in the set are unique and different from each other.
Formally, similar to dictionaries, Python collections place all elements in a pair of curly braces {}, with adjacent elements separated by "," as shown below:
{element1,element2,...,elementn}
Where, elementn represents the elements in the collection, and the number is unlimited.
In terms of content, the same set can only store immutable data types, including integer, floating point, string and tuple, but cannot store variable data types such as list, dictionary and set, otherwise the Python interpreter will throw TypeError error. for instance:
>>> {{'a':1}}
Traceback (most recent call last):
File "<pyshell#8>", line 1, in <module>
{{'a':1}}
TypeError: unhashable type: 'dict'
>>> {[1,2,3]}
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
{[1,2,3]}
TypeError: unhashable type: 'list'
>>> {{1,2,3}}
Traceback (most recent call last):
File "<pyshell#10>", line 1, in <module>
{{1,2,3}}
TypeError: unhashable type: 'set'
And it should be noted that the data must be unique, because the set will only retain one copy for each data element. For example:
>>> {1,2,1,(1,2,3),'c','c'}
{1, 2, 'c', (1, 2, 3)}
Because the set collection in Python is unordered, the sorting order of elements may be different each time it is output.
In fact, there are two collection types in Python. One is a set type collection and the other is a frozenset type collection. The only difference between them is that a set type collection can add or delete elements, while a forzenset type collection cannot. This section first introduces the set type collection, and then introduces the forzenset type collection in subsequent chapters.
1. Python creates a set set
Python create set collection:
Python provides two methods to create a set set. They are using {} to create and using the set() function to convert list, tuple and other types of data into a set.
1. Create with {}:
In Python, creating a set set can directly assign a set to a variable like a list, element and dictionary, so as to achieve the purpose of creating a set. Its syntax format is as follows:
setname = {element1,element2,...,elementn}
Among them, setname represents the name of the collection. When naming, it should not only comply with Python naming norms, but also avoid duplicate names with Python built-in functions.
for instance:
a = {1,'c',1,(1,2,3),'c'}
print(a)
>>>
{1, 'c', (1, 2, 3)}
2. set() function creates a set:
The set() function is a built-in function of Python. Its function is to convert iteratable objects such as strings, lists, tuples and range objects into sets. The syntax format of this function is as follows:
setname = set(iteration)
Among them, iteration represents string, list, tuple, range object and other data.
For example:
set1 = set("c.biancheng.net")
set2 = set([1,2,3,4,5])
set3 = set((1,2,3,4,5))
print("set1:",set1)
print("set2:",set2)
print("set3:",set3)
>>>
set1: {'a', 'g', 'b', 'c', 'n', 'h', '.', 't', 'i', 'e'}
set2: {1, 2, 3, 4, 5}
set3: {1, 2, 3, 4, 5}
Note that if you want to create an empty collection, you can only use the set() function. Because you use a pair of {} directly, the Python interpreter treats it as an empty dictionary.
2. Python accesses set set elements
Because the elements in the collection are unordered, you cannot use subscripts to access elements like a list. In Python, the most common way to access collection elements is to use the loop structure to read the data in the collection one by one.
a = {1,'c',1,(1,2,3),'c'}
for ele in a:
print(ele,end=' ')
>>>
1 c (1, 2, 3)
3. Python deletes the set
Like other sequence types, you can also use del() statements for manual function collection types, for example:
a = {1,'c',1,(1,2,3),'c'}
print(a)
del(a)
print(a)
>>>
{1, 'c', (1, 2, 3)}
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\1.py", line 4, in <module>
print(a)
NameError: name 'a' is not defined
Python set basic operations (add, delete, intersection, union, difference)
Adds an element to the set collection
To add elements to the set, you can use the add() method provided by the set type. The syntax format of this method is:
setname.add(element)
Where setname represents the collection of elements to be added, and element represents the content of elements to be added.
It should be noted that the elements added by using the add() method can only be numbers, strings, tuples or boolean type (True and False) values. Variable data such as lists, dictionaries and collections cannot be added, otherwise the Python interpreter will report a TypeError error. For example:
a = {1,2,3}
a.add((1,2))
print(a)
a.add([1,2])
print(a)
>>>
{(1, 2), 1, 2, 3}
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\1.py", line 4, in <module>
a.add([1,2])
TypeError: unhashable type: 'list'
Deletes an element from the set collection
To delete the specified element in the existing set collection, you can use the remove() method. The syntax format of this method is as follows:
setname.remove(element)
Use this method to delete the elements in the collection. Note that if the deleted elements are not included in the collection, this method will throw a KeyError error error, for example:
a = {1,2,3}
a.remove(1)
print(a)
a.remove(1)
print(a)
>>>
{2, 3}
Traceback (most recent call last):
File "C:\Users\mengma\Desktop\1.py", line 4, in <module>
a.remove(1)
KeyError: 1
In the above program, since element 1 in the collection has been deleted, a KeyError error error will be raised when trying to delete it again using the remove() method.
If we don't want the interpreter to prompt KeyError error error when the deletion fails, we can also use the discard() method. This method has the same usage as the remove() method. The only difference is that this method will not throw any error when the deletion of elements in the collection fails.
a = {1,2,3}
a.remove(1)
print(a)
a.discard(1)
print(a)
>>>
{2, 3}
{2, 3}
Python set performs intersection, union and difference set operations
The most common operations of sets are intersection, union, difference set and symmetric difference set operations. Firstly, it is necessary to popularize the meaning of each operation.
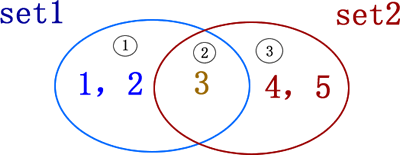
Fig. 1 assembly diagram
In Figure 1, there are two sets, set1={1,2,3} and set2={3,4,5}, which have the same elements and different elements. Taking these two sets as an example, the results of different operations are shown in Table 1.
Table 1 Python set operations
| Arithmetic operation | Python operator | meaning | example | Output results |
|---|---|---|---|---|
| intersection | & | Take the elements common to two sets | >>> set1 & set2 | {3} |
| Union | | | Take all the elements of two sets | >>> set1 | set2 | {1,2,3,4,5} |
| Difference set | - | Take an element in a collection that is not in another collection | >>> set1 - set2 | {1,2} |
| Symmetric difference set | ^ | Take the elements in sets A and B that do not belong to A & B | >>> set1 ^ set2 | {1,2,4,5} |
Detailed explanation of Python set method (full)
In this section, we will learn the methods provided by the set type one by one. First, you can see what methods it has through the dir(set) command:
>>> dir(set) ['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
The specific syntax structure and functions of each method are shown in Table 1.
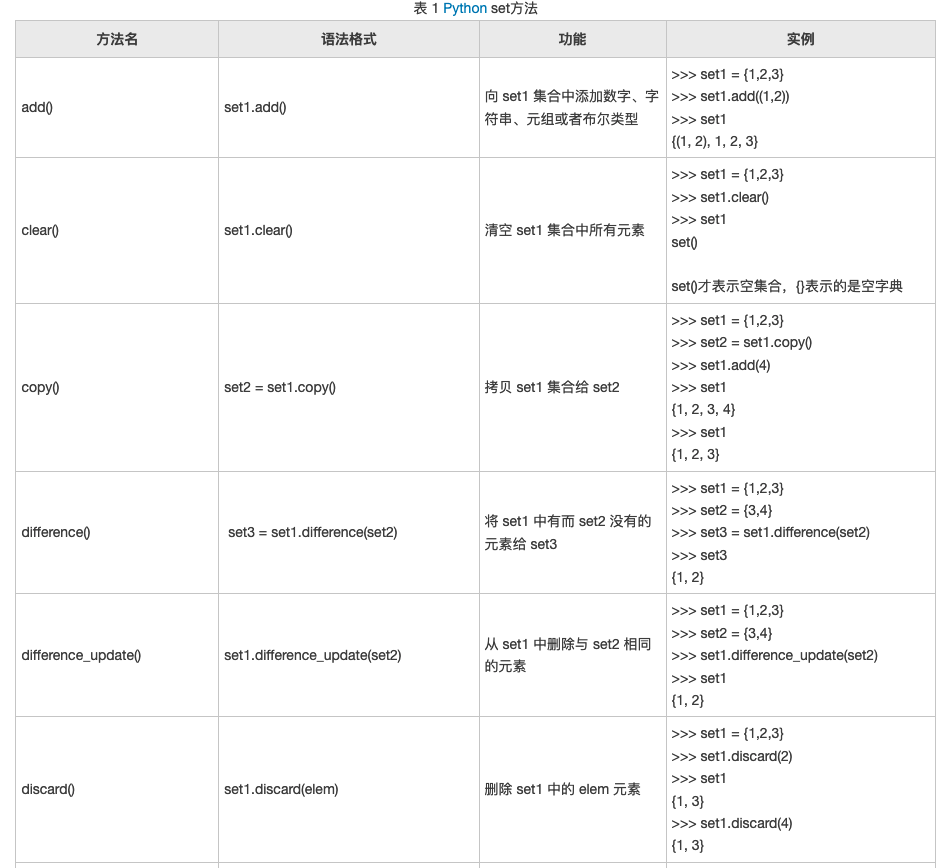
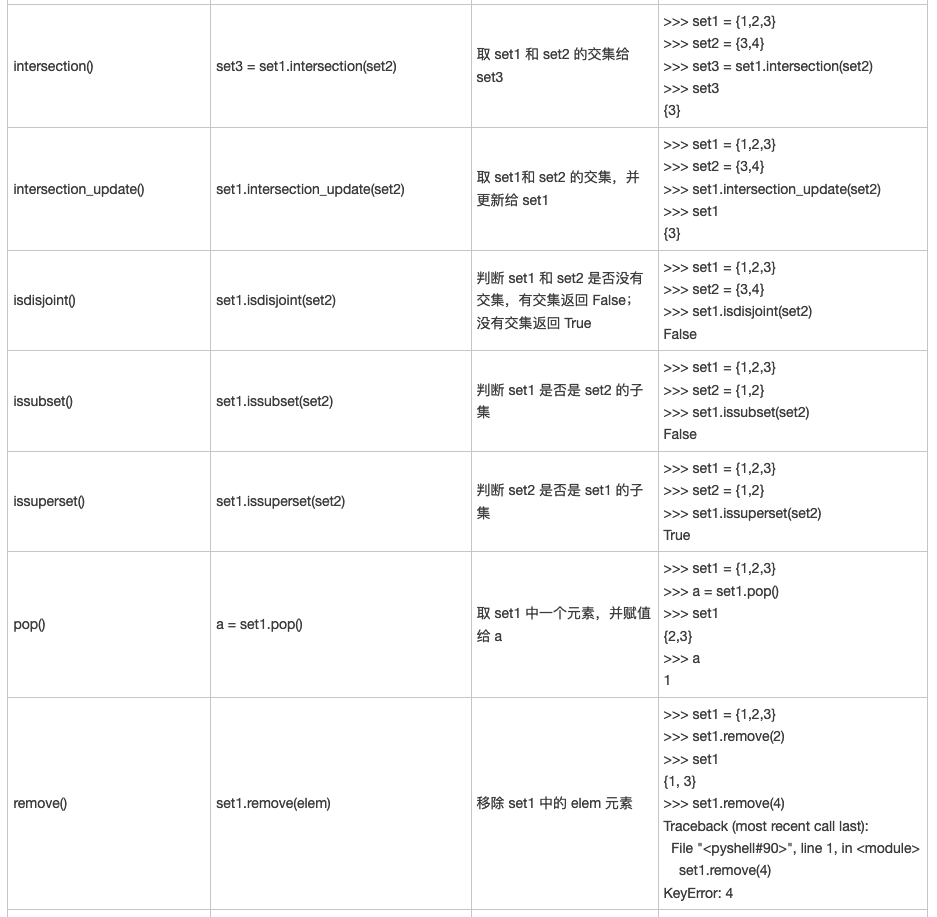
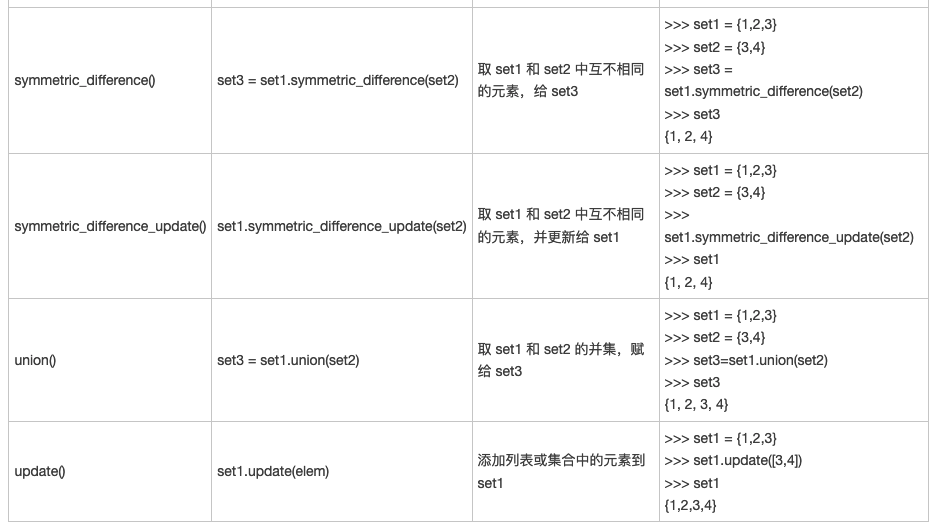
Original reference link: Detailed explanation of Python set method (full)
set.update(x) updates multiple values
update(x), add x to the collection, and the parameters can be list, tuple, dictionary, etc.
Note: adding a dictionary can only add immutable - keys
# update(x), add x to the collection, and the parameters can be list, tuple, dictionary, etc
s = set(('a', 'cc', 'f'))
# Adding a dictionary can only add immutable -- keys
dict_1 = {'name': 'bb', 'age': 'cc', 'f': 11}
s.update(dict_1)
print("Add dictionary"+str(s))
>>>
Add dictionary{'name', 'a', 'age', 'f', 'cc'}
Example 2:
s = set(('a', 'cc', 'f'))
tup_1 = (1, 2,)
s.update(tup_1)
print(s)
>>>
{1, 2, 'a', 'f', 'cc'}
s = set(('a', 'cc', 'f'))
list_1 = ['w', 'a', 1]
s.update(list_1)
print(s)
>>>
{1, 'f', 'w', 'a', 'cc'}
set.add(x) adds the element X to the collection
set.add(x) to add element X to the collection.
# add(x) adds the element X to the collection
s = {1,2,3,4,5,}
s.add('5')
print(s)
>>>
{1, 2, 3, 4, 5, '5'}
set.remove(x) removes elements from the collection. If the removed elements are not in the collection, an error will occur
set.remove(x) removes elements from the collection. If the removed elements are not in the collection, an error will occur
# Remove the elements in the collection. If the removed elements are not in the collection, an error will occur
s = set(('a', 'cc', 'f'))
s.remove('cc')
print(s)
{'a', 'f'}
Example 2:
s = set(('a', 'cc', 'f'))
s.remove('mm')
print(s)
>>>
Traceback (most recent call last):
File "C:/Users/123/PycharmProjects/py2018/test", line 104, in <module>
s.remove('mm')
KeyError: 'mm'
set.pop() randomly deletes the elements in the collection
# Randomly delete elements in the collection
s = set(('a', 'cc', 'f'))
s.pop()
print(s)
{'a', 'cc'}
set.clear() clear the collection
# Empty collection
s = set(('a', 'cc', 'f'))
s.clear()
print(s)
>>>
set()
len(set) calculates the number of set elements
calculation set Number of elements
s = set(('a', 'cc', 'f'))
print('The number of collection elements is:'+str(len(s)))
Set length: 3
set.copy copy collection
set.copy
s = set(('a', 'cc', 'f'))
s1 = s.copy()
print(s1)
{'a', 'f', 'cc'}
Difference Set1 difference(set2)
Difference set(-) (difference)
Copy code
# Difference to find the difference set or use-
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# Two methods of finding difference sets
print("stay s Not in s1 in: "+str(s.difference(s1)))
print('stay s1 Not in s Medium: '+str(s1-s))
Copy code
stay s Not in s1 in: {'cc'}
stay s1 Not in s Medium: {'ww', 1}
Intersection Set1 intersection(set2)
Intersection(&) (intersection)
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# Elements in both sets s and s1
print(s.intersection(s1))
print(s1&s)
{'a', 'f'}
{'a', 'f'}
Union Set1 union(set2)
Union(|) (union)
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# Element in set s or in set s1
print(s.union(s1))
print(s1|s)
{'a', 1, 'f', 'cc', 'ww'}
{'a', 1, 'f', 'cc', 'ww'}
Symmetric difference set Set1 symmetric_ difference(set2)
Symmetric difference set(^) (sysmmetric_difference)
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f', 1, 'ww'}
# Elements other than those common to set s and set s1
print(s.symmetric_difference(s1))
print(s1^s)
>>>
{1, 'ww', 'cc'}
{1, 'ww', 'cc'}
set.issubset(x) determines whether a set is a subset of another set
set.issubset(x) Determine whether a set is a subset of another set
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f'}
print(s.issubset(s1))
print(s1.issubset(s))
>>>
False
True
set.isuperset(x) determines whether a set is the parent of another set
set.isuperset(x) Determines whether a set is the parent of another set
Copy code
s = set(('a', 'cc', 'f'))
s1 = {'a', 'f'}
print(s.issuperset(s1))
print(s1.issuperset(s))
# s1 is a subset of s and s is the parent set of s1
print(s1.issubset(s))
>>>
True
False
True
symmetric_difference_update() symmetric update difference set
symmetric_difference_update() Symmetric renewal difference set
#The same elements in s2 and s1 are removed while updating s2 to s1
s1 = {'ljl','wc','xy','zb','lsy'}
s2 = {'mmf','lsy','syj'}
s1.symmetric_difference_update(s2)
print(s1)
{'syj', 'xy', 'wc', 'ljl', 'zb', 'mmf'}
isdisjoint() detects whether there is no intersection between the two sets. The intersection is False
isdisjoint() Detect whether there is no intersection between the two sets False
s1 = {'ljl','wc','xy','zb','lsy'}
s2 = {'mmf','lsy','syj'}
s3 = {1, 2}
print(s1.isdisjoint(s2))
print(s1.isdisjoint(s3))
>>>
False
True
intersection_update intersection update operation
intersection_update Intersection update operation
Copy code
s1 = {'ljl','wc','xy','zb','lsy'}
s2 = {'mmf','lsy','syj'}
s1.intersection_update(s2)
s2.intersection_update(s1)
print(s1)
print(s2)
>>>
{'lsy'}
{'lsy'}
Reference link: Python set method
Differences and relations between dictionaries and collections in Python
Dictionaries and collections are highly performance optimized data structures, especially for find, add, and delete operations. This section will introduce their performance in specific scenarios and compare them with other data structures such as lists.
For example, there is a list that stores product information (product ID, name and price). The current requirement is to find out the price of a product by using its ID. the implementation code is as follows:
def find_product_price(products, product_id):
for id, price in products:
if id == product_id:
return price
return None
products = [
(111, 100),
(222, 30),
(333, 150)
]
print('The price of product 222 is {}'.format(find_product_price(products, 222)))
>>>
The price of product 222 is 30
Based on the above program, if the list has n elements, because the search process needs to traverse the list, the time complexity in the worst case is O(n). Even if the list is sorted first and then the binary search algorithm is used, the time complexity of O(logn) is required. Moreover, the sorting of the list still needs O(nlogn) time.
However, if the dictionary is used to store these data, the search will be very convenient and efficient. It can be completed with the time complexity of O(1), because the corresponding value can be found directly through the hash value of the key without traversing the dictionary. The implementation code is as follows:
products = {
111: 100,
222: 30,
333: 150
}
print('The price of product 222 is {}'.format(products[222]))
>>>
The price of product 222 is 30
Some readers may not have an intuitive understanding of time complexity. It doesn't matter. Let me give you another example. In the following code, the product with 100000 elements is initialized, and the running time of using list and set to count product price and quantity is calculated respectively:
#You need to use the functions in the time module to count time
import time
def find_unique_price_using_list(products):
unique_price_list = []
for _, price in products: # A
if price not in unique_price_list: #B
unique_price_list.append(price)
return len(unique_price_list)
id = [x for x in range(0, 100000)]
price = [x for x in range(200000, 300000)]
products = list(zip(id, price))
# Time to calculate list version
start_using_list = time.perf_counter()
find_unique_price_using_list(products)
end_using_list = time.perf_counter()
print("time elapse using list: {}".format(end_using_list - start_using_list))
#Use collections to do the same
def find_unique_price_using_set(products):
unique_price_set = set()
for _, price in products:
unique_price_set.add(price)
return len(unique_price_set)
# Time when the collection version was calculated
start_using_set = time.perf_counter()
find_unique_price_using_set(products)
end_using_set = time.perf_counter()
print("time elapse using set: {}".format(end_using_set - start_using_set))
The operation result is:
time elapse using list: 68.78650900000001 time elapse using set: 0.010747099999989018
It can be seen that with only 100000 data, the speed difference between the two is so large. Often, the enterprise's background data has hundreds of millions or even billions of orders of magnitude. Therefore, if an inappropriate data structure is used, it is easy to cause the server to crash, which will not only affect the user experience, but also bring huge property losses to the company.
So why are dictionaries and collections so efficient, especially find, insert, and delete operations?
How dictionaries and collections work
Dictionaries and collections are so efficient that they are inseparable from their internal data structures. Unlike other data structures, the internal structure of dictionaries and collections is a hash table:
For the dictionary, this table stores three elements: hash, key and value.
For a collection, only a single element is stored in the hash table.
For previous versions of Python, its hash table structure is as follows:
| Hash value (hash) key (key) value (value) . | ... 0 | hash0 key0 value0 . | ... 1 | hash1 key1 value1 . | ... 2 | hash2 key2 value2 . | ...
The disadvantage of this structure is that with the expansion of the hash table, it will become more and more sparse. For example, there is such a dictionary:
{'name': 'mike', 'dob': '1999-01-01', 'gender': 'male'}
Then it will be stored in a form similar to the following:
entries = [ ['--', '--', '--'] [-230273521, 'dob', '1999-01-01'], ['--', '--', '--'], ['--', '--', '--'], [1231236123, 'name', 'mike'], ['--', '--', '--'], [9371539127, 'gender', 'male'] ]
Obviously, this is a waste of storage space. In order to improve the utilization of storage space, in addition to the structure of the dictionary itself, the current hash table will separate the index from the hash value, key and value, that is, the following structure is adopted:
Indices
----------------------------------------------------
None | index | None | None | index | None | index ...
----------------------------------------------------
Entries
--------------------
hash0 key0 value0
---------------------
hash1 key1 value1
---------------------
hash2 key2 value2
---------------------
...
---------------------
On this basis, the storage form of the above dictionary under the new hash table structure is:
indices = [None, 1, None, None, 0, None, 2] entries = [ [1231236123, 'name', 'mike'], [-230273521, 'dob', '1999-01-01'], [9371539127, 'gender', 'male'] ]
Through comparison, it can be found that the space utilization rate has been greatly improved.
After knowing the specific design structure, we will analyze how to use the hash table to complete the operations of data insertion, search and deletion.
Hash table insert data
When inserting data into the dictionary, Python will first calculate the corresponding hash value according to the key (through the hash(key) function). When inserting data into the collection, Python will calculate the corresponding hash value according to the element itself (through the hash (use) function).
For example:
dic = {"name":1}
print(hash("name"))
setDemo = {1}
print(hash(1))
The operation result is:
8230115042008314683
1
After obtaining the hash value (for example, hash), combined with the number of data to be stored in the dictionary or collection (for example, n), you can get the position where the element should be inserted into the hash table (for example, hash%n can be used).
If this position in the hash table is empty, this element can be directly inserted into it; Conversely, if this location is already occupied by other elements, Python compares whether the hash value and key of the two elements are equal:
-
If they are equal, it indicates that the element already exists. Compare their values, and update if they are not equal;
-
If they are not equal, this situation is called hash conflict (that is, the keys of the two elements are different, but the hash value obtained is the same). In this case, Python will continue to find the empty position in the hash table using open addressing method, re hashing method, etc. until the position is found.
In case of hash conflict, please refer to the section "detailed explanation of hash table" for the specific meaning of each solution.
Hash table lookup data:
Finding data in the hash table is similar to inserting. Python will find the location where the element should be stored in the hash table according to the hash value, and then compare its hash value and key with the element in the location (the collection directly compares the element value):
-
If equal, it proves that it is found;
-
On the contrary, it proves that there is a hash conflict when storing the element. You need to continue to use the original method to solve the hash conflict until you find the element or find a vacancy.
The empty bit found here indicates that the target element is not stored in the hash table.
Hash table delete element:
For the delete operation, Python will temporarily assign a special value to the element at this position, and then delete it when the hash table is resized.
It should be noted that hash conflicts often reduce the speed of dictionary and collection operations. Therefore, in order to ensure its efficiency, the dictionary and the hash table in the set usually ensure that there is at least 1 / 3 of the remaining space. With the continuous insertion of elements, when the remaining space is less than 1 / 3, Python will regain more memory space and expand the hash table. At the same time, all element positions in the table will be rearranged.
Although hash conflicts and hash table size adjustment will slow down, this happens very rarely. Therefore, on average, the time complexity of insertion, search and deletion can still be guaranteed to be O(1).
Reference link: Similarities and differences between Python dictionary and collection
Reference link: Differences and relations between dictionaries and collections in Python