The use of selenium in reptiles
I selenium overview
1.1 definitions
Selenium is a Web automated testing tool, which was originally developed for website automated testing. Selenium can directly call the browser. It supports all mainstream browsers (including PhantomJS, which has no interface). It can receive instructions and let the browser automatically load pages, obtain required data, and even screen shots. We can easily write crawlers using selenium.
1.2 function and working principle
Using the browser's native API, it is encapsulated into a set of more object-oriented Selenium WebDriver API to directly operate the elements in the browser page and even the browser itself (screen capture, window size, start, close, install plug-ins, configure certificates, etc.)
II selenium installation
2.1 installing selenium module in python
pip install selenium
2.2 download webdriver (take edge browser as an example)
Check the version of edge browser, and you can see that my version here is 98.0.1108.62
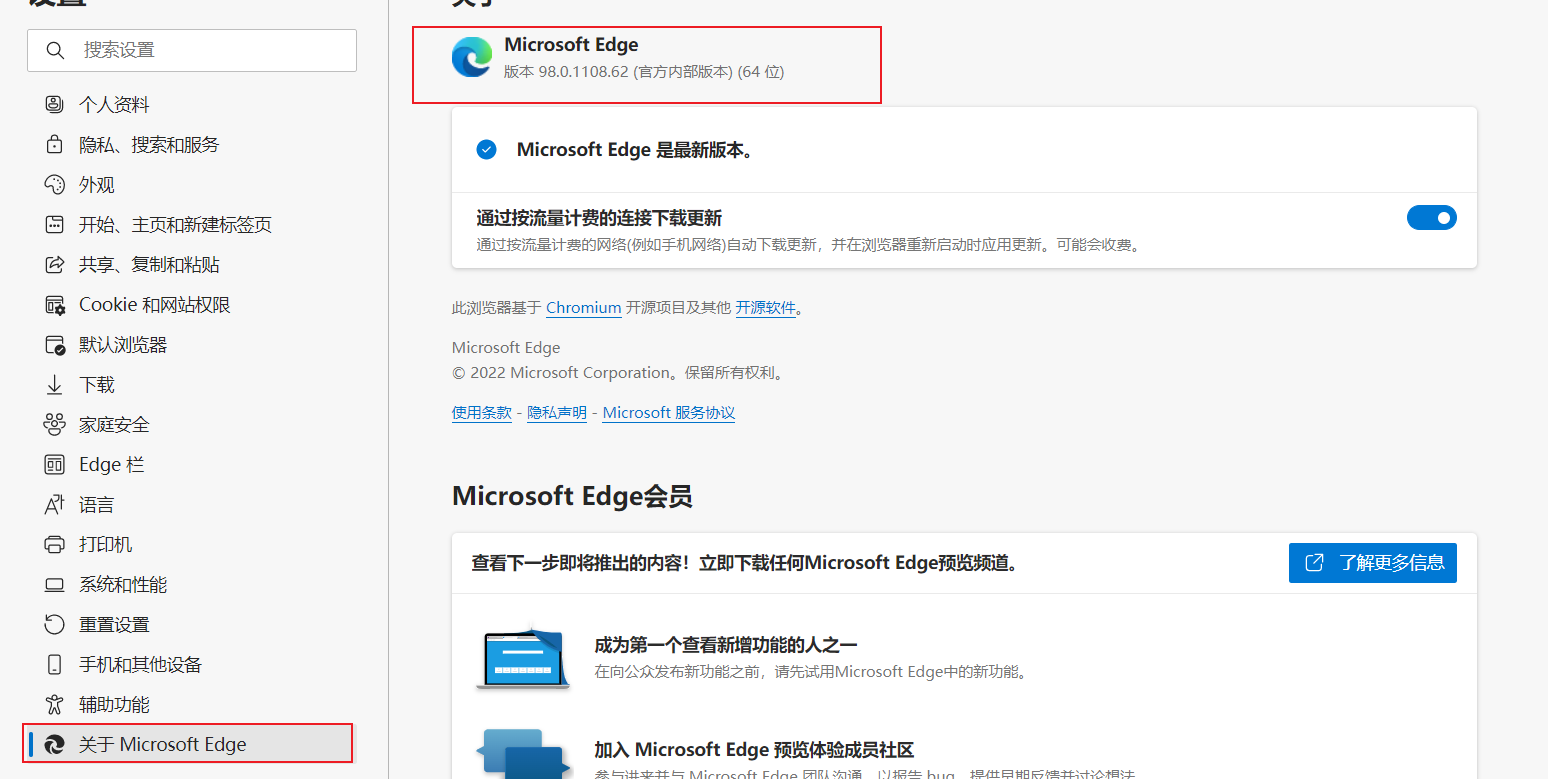
webdriver has different browser download addresses. edge driver is used here
chrome driver: http://chromedriver.storage.googleapis.com/index.html
Firefox driver: https://github.com/mozilla/geckodriver/releases/
Edge drive: https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
Find the corresponding version and click x64 to download it
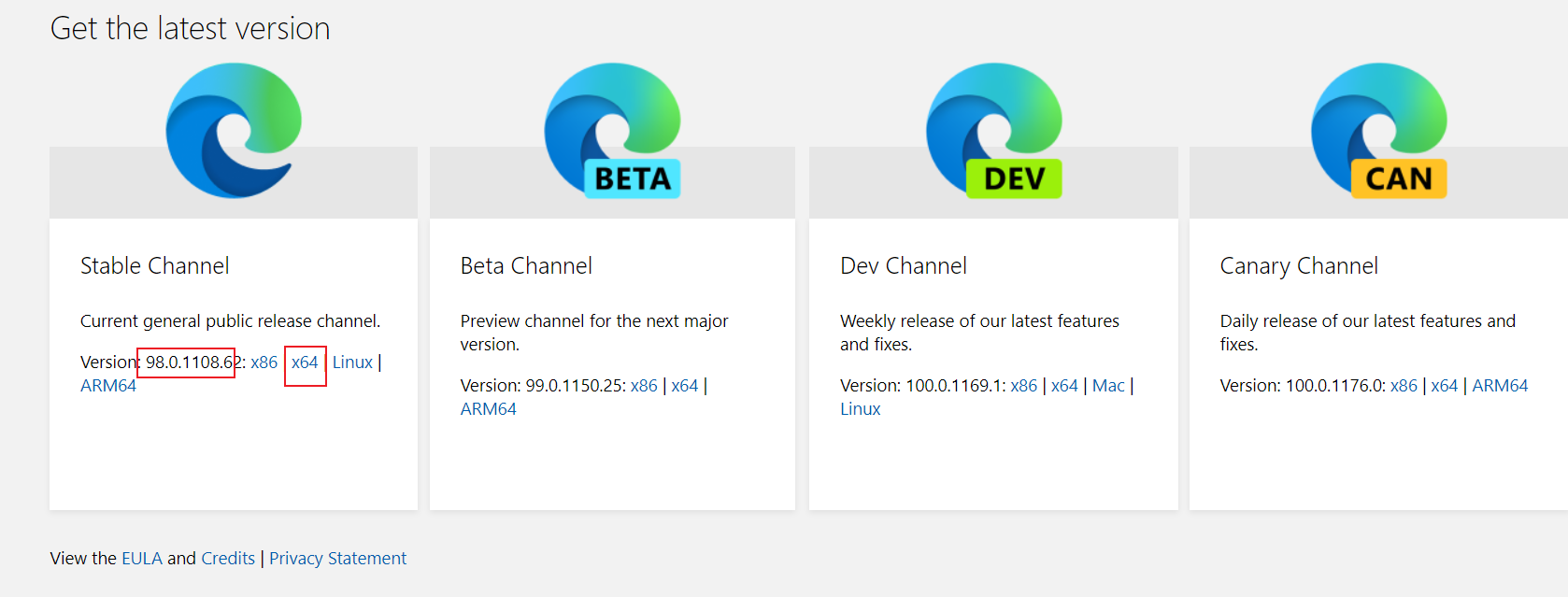
2.3 configuration environment
Download the msedgedriver The EXE file is placed in the directory of the edge browser
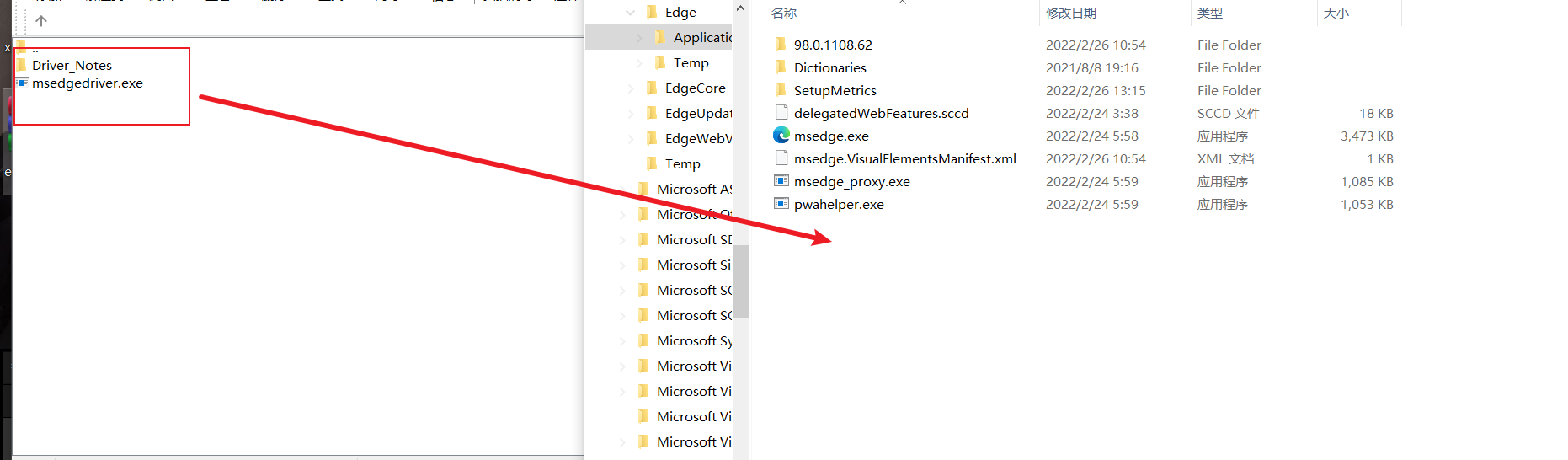
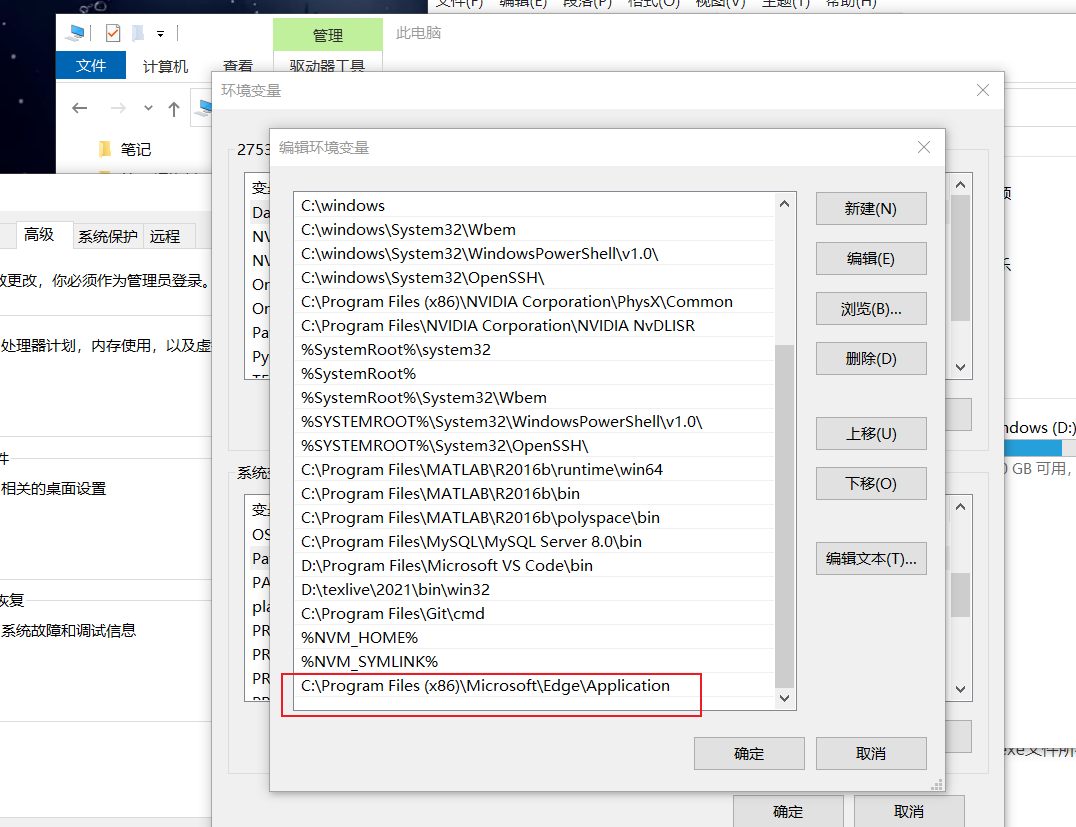
Set msedgedriver The path of the directory where the EXE file is located is added to the environment variable
2.4 simple application
Use python to open the browser and search for python in Baidu
import time
from selenium import webdriver
#Create drive object
#To register environment variables
# driver=webdriver.Edge()
#There is no registered executable_ The path where the driver is located in path
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.baidu.com')
time.sleep(5)
#Search for python in Baidu search box
driver.find_element_by_id('kw').send_keys('python')
driver.find_element_by_id('su').click()
time.sleep(6)
driver.quit()
III Object driver
The above example probably has the basic use of webdriver. Now create a driver object
from selenium import webdriver #Create drive object #To register environment variables # driver=webdriver.Edge() #There is no registered executable_ The path where the driver is located in path driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
3.1 common attributes and methods of driver object
In the process of using selenium, after instantiating the driver object, the driver object has some common properties and methods
- driver.page_source the web page source code rendered by the current tab browser (does not involve the source code of capturing packets, just copy it)
- driver.current_url the url of the current tab (of the response)
- driver.close() closes the current tab. If there is only one tab, close the entire browser
- driver.quit() closes the browser
- driver. Forward page
- driver. Back page
- driver. save_ Screenshot of screenshot (img_name) page
3.2 positioning label elements
The element can be positioned in the tag and returned in a variety of ways
find_element_by_id (Returns an element) find_element(s)_by_class_name (Get the element list according to the class name) find_element(s)_by_name (According to the label name Property value returns a list of elements that contain label objects) find_element(s)_by_xpath (Returns a list containing elements) find_element(s)_by_link_text (Get the element list according to the link text) find_element(s)_by_partial_link_text (Get the list of elements based on the text contained in the link) find_element(s)_by_tag_name (Get the element list according to the tag name) find_element(s)_by_css_selector (according to css Selector to get the list of elements)
be careful:
- find_element and find_ Differences between elements:
- If there is more than one s, the list will be returned, and if there is no s, the first tag object matched will be returned
- find_ Throw an exception if the element does not match, find_ If the elements do not match, an empty list will be returned
- by_link_text and by_ partial_ link_ The difference between text: all text and containing a text
3.3 extract text content
find_element can only get the element, not the data directly. If you need to get the data, you need to use the following methods
- Click on the element click()
- Click the located label object
- Enter data element into the input box send_ keys(data)
- Enter data for the anchored label object
- Get the text element text
- Get the text content by locating the text attribute of the obtained label object
- Get the attribute value element get_ Attribute ("attribute name")
- Get of tag object obtained by locating_ The attribute function passes in the attribute name to get the value of the attribute
Chestnuts:
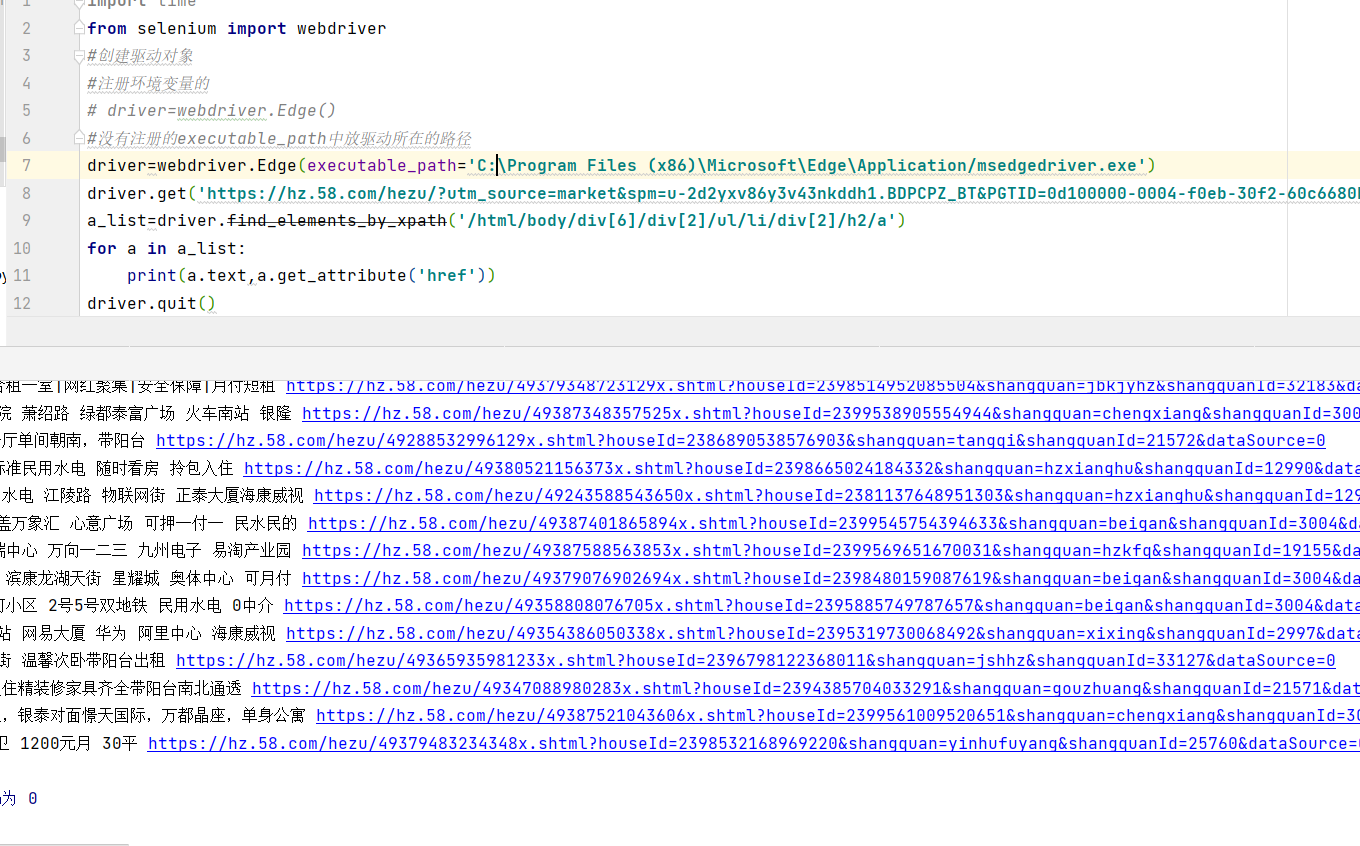
Take 58 city – > co renting as an example, grab all the house names and links on the current page
import time
from selenium import webdriver
#Create drive object
#To register environment variables
# driver=webdriver.Edge()
#There is no registered executable_ The path where the driver is located in path
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('https://hz.58.com/hezu/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d100000-0004-f0eb-30f2-60c6680bc9c2&ClickID=2')
a_list=driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
for a in a_list:
print(a.text,a.get_attribute('href'))
driver.quit()
Operation results:
IV selenium tab switching
4.1 page tab switching
When selenium controls the browser to open multiple tabs, how to control the browser to switch between different tabs? need
We do the following two steps:
-
Gets the window handle of all tabs
-
Use the window handle word to switch to the tab pointed to by the handle
-
The window handle here refers to the identification pointing to the tab object
-
Specific method
# 1. Get the list of handles of all current tabs current_windows = driver.window_handles # 2. Switch according to the index subscript of the tab handle list driver.switch_to.window(current_windows[0])
example:
Open two pages and switch to the second
import time
from selenium import webdriver
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.baidu.com')
time.sleep(3)
driver.find_element_by_id('kw').send_keys('python')
driver.find_element_by_id('su').click()
#Open a tag by executing js
js='window.open("https://www.sogou.com")'
# Execute js code
driver.execute_script(js)
#Get all windows
windows=driver.window_handles
time.sleep(3)
#Switch according to window index
driver.switch_to.window(windows[0])
time.sleep(3)
driver.switch_to.window(windows[1])
time.sleep(3)
driver.quit()
Secondary 58 climbing
import time
from selenium import webdriver
#Create drive object
#To register environment variables
# driver=webdriver.Edge()
#There is no registered executable_ The path where the driver is located in path
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://www.58.com')
time.sleep(1)
# Click the sharing link
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[1]/div/div[1]/div[1]/span[3]/a').click()
time.sleep(1)
#switch windows
driver.switch_to.window(driver.window_handles[-1])
time.sleep(1)
#Find the object list through xpath
a_list=driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a')
for a in a_list:
print(a.text,a.get_attribute('href'))
driver.quit()
4.2 iframe label switching
frame is a common technology in html, that is, a page is nested with another web page, and selenium cannot access it by default
The corresponding solution to the content in iframe is
Find the iframe object frame through xpath_ Element (xpath can't see the content)
Via driver switch_ to. Frame (frame_element) can enter the iframe page
Find the connection of "account password login" through id and click it to enter the "account password login page"
Find the input box of account and password and the login button through id
Example: log in to QQ space
import time
from selenium import webdriver
#Create drive object
#To register environment variables
# driver=webdriver.Edge()
#There is no registered executable_ The path where the driver is located in path
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://i.qq.com')
time.sleep(1)
l_iframe=driver.find_element_by_xpath('//*[@id="login_frame"]')
print(l_iframe)
#Enter ifram tab
driver.switch_to.frame(l_iframe)
driver.find_element_by_id('switcher_plogin').click()
time.sleep(1)
#Enter account number
driver.find_element_by_id('u').send_keys('Yours QQ account number')
time.sleep(1)
#Input password
driver.find_element_by_id('p').send_keys('*Your password')
time.sleep(1)
driver.find_element_by_id('login_button').click()
time.sleep(10)
#Slider label, drag it manually and try again
driver.find_element_by_id('login_button').click()
driver.quit()
V Get cookies
5.1 cookie overview
Cookie s, sometimes in the plural form, refer to Cookies stored in some websites in order to identify users and track session s
Data on the user's local terminal (usually encrypted). The specifications defined in RFC2109 and 2965 have been abandoned, and the latest replaced specification is RFC6265.
The Cookie is generated by the server and sent to the user agent (usually the browser), and the browser will protect the key/value of the Cookie
Stored in a text file in a directory, the Cookie will be sent to the server the next time the same website is requested (provided that the browser is set to enable)
Use cookies). The cookie name and value can be defined by the server-side development. For JSP, jsessionid can also be written directly,
In this way, the server can know whether the user is a legal user and whether it needs to log in again.
purpose
The server can use the arbitrariness of the information contained in Cookies to filter and regularly maintain these information to judge the error in HTTP transmission
Status. The most typical application of Cookies is to determine whether the registered user has logged in to the website. The user may be prompted whether to log in next time
When you enter this website, keep user information to simplify login procedures. These are the functions of Cookies. Another important application is shopping
"Car" and so on. Users may choose different products from different pages of the same website over a period of time, and these information will be written in
Cookies to extract information at the time of final payment.
Get cookie s
driver.get_cookies() returns a list containing complete cookie information! Not only name and value, but also
There are cookies such as domain and other dimensions of information. So if you want to use the obtained cookie information with the requests module
If yes, you need to convert the cookie dictionary into name and value as key value pairs
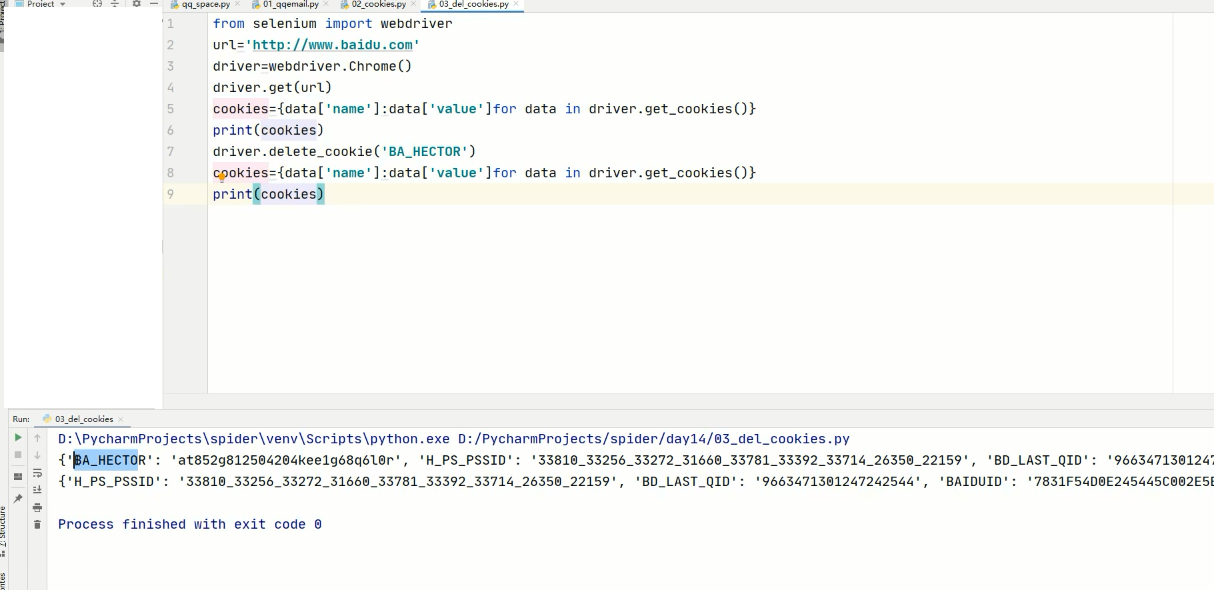
# Get all cookie information of the current tab
print(driver.get_cookies())
# Convert cookie s into Dictionaries
cookies_dict = {cookie['name']: cookie['value']} for cookie in
driver.get_cookies()}
5.3 deleting cookie s
#Delete a cookie
driver.delete_cookie("CookieName")
# Delete all cookie s
driver.delete_all_cookies()
Vi Page waiting
6.1 forced waiting
- It's actually time sleep()
- Disadvantages: it is not intelligent, the setting time is too short, and the elements have not been loaded; If the setting time is too long, it will waste time
6.2 implicit waiting
- Implicit waiting is for element positioning. Implicit waiting sets a time to judge whether the element is successfully positioned within a period of time, such as
If you are finished, go to the next step - If the location is not successful within the set time, the timeout loading will be reported
- Sample code
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # Implicit wait, max. 10 seconds
driver.get('https://www.baidu.com')
driver.find_element_by_xpath()
6.3 display waiting
Check whether the waiting conditions are met every few seconds. If they are met, stop waiting and continue to execute subsequent codes
If there is no achievement, continue to wait until the specified time is exceeded, and a timeout exception will be reported
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as ec
from selenium.webdriver.common.by import By
#Create drive object
#To register environment variables
# driver=webdriver.Edge()
#There is no registered executable_ The path where the driver is located in path
driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
driver.get('http://baidu.com')
WebDriverWait(driver,20,0.5).until(
ec.presence_of_element_located((By.LINK_TEXT,'hao123'))
)
print(driver.find_element_by_link_text('hao123').get_attribute('href'))
driver.quit()
VII selenium anti climbing
7.1 using proxy ip
Method of using proxy ip
#Instantiate configuration object
options = webdriver.ChromeOptions()
#The configuration object adds commands that use proxy ip
options.add_argument('--proxy-server=http://202.20.16.82:9527')
Instantiate with configuration object driver object
#driver = webdriver.Edge(chrome_options=options)
7.2 replacing user agent
#Instantiate configuration object
options = webdriver.ChromeOptions()
#Add and replace UA command for configuration object
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
#Instantiate the driver object with the configuration object
driver = webdriver.Edge(chrome_options=options)
7.3 fishing net climbing
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
class DouYuSpider(object):
def __init__(self):
self.url='https://www.douyu.com/directory/all'
# self.opt=webdriver.EdgeOptions().add_argument('--headless')
self.driver=webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application/msedgedriver.exe')
def parse_data(self):
time.sleep(10)
#Get the list of live rooms
room_list=self.driver.find_elements_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div')
print(len(room_list))
data_list=[]#List of all data
#Traverse room_list grabs the data of each live broadcast room
for r in room_list:
temp={}
temp['title']=r.find_element_by_xpath('./a/div[2]/div[1]/h3').text
temp['type']=r.find_element_by_xpath('./a/div[2]/div[1]/span').text
temp['owner']=r.find_element_by_xpath('./a/div[2]/div[2]/h2/div').text
temp['num']=r.find_element_by_xpath('./a/div[2]/div[2]/span').text
#There is a problem here. You can't grab it with the comments below
temp['image']=self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/ul/li/div/a/div[1]/div[1]/picture/img').get_attribute('src')
# temp['image'] = r.find_element_by_xpath('./a/div[1]/div[1]/picture/img').get_attribute('src')
data_list.append(temp)
return data_list,len(room_list)
def save_data(self,data_list):
for data in data_list:
print(data)
def main(self):
# the number of pages
number=0
self.driver.get(self.url)
while True:
data_list,num=self.parse_data()
self.save_data(data_list)
if num<120:
break
try:
self.driver.execute_script('scrollTo(0,1000000)')
# el_text=self.driver.find_element_by_xpath('//*[@id="listAll"]/section[2]/div[2]/div/ul/li[9]/span')
#It can also be written like this
el_text=self.driver.find_element(by=By.XPATH,value='//*[contains(text(), "next")] ')
el_text.click()
number+=1
print(f'The first{number}page')
except Exception as e:
print(e)
break
self.driver.quit()
if __name__ == '__main__':
spider=DouYuSpider()
spider.main()

VIII No interface mode
Using selenium will call the browser to run. If you don't want the browser to hang out, you can add the following configuration
Instantiate configuration object
options = webdriver.EdgeOptions()
The configuration object adds a command to turn on the no interface mode
options.add_argument("--headless")
Usually one is enough
Configuration object addition disabled gpu Command of
options.add_argument("--disable-gpu")
Instantiate with configuration object driver object
driver = webdriver.Edge(options=options)
Note: the 59 + version of chrome browser in macos and the 57 + version in Linux can only use the interface free mode!