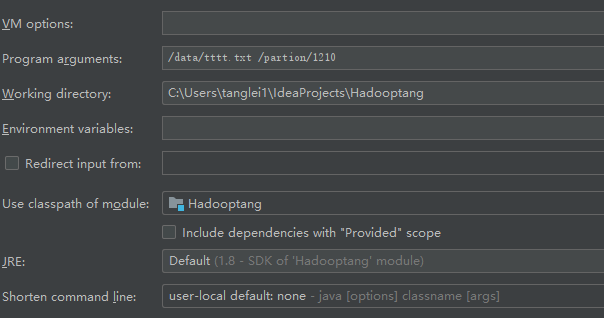
The partitioner of MapReduce is HashPartitioner
Principle: first, hash the key output from the map, then reduce the number of tasks on the module. According to the result, determine the output kv pair, which is taken by the matching reduce task.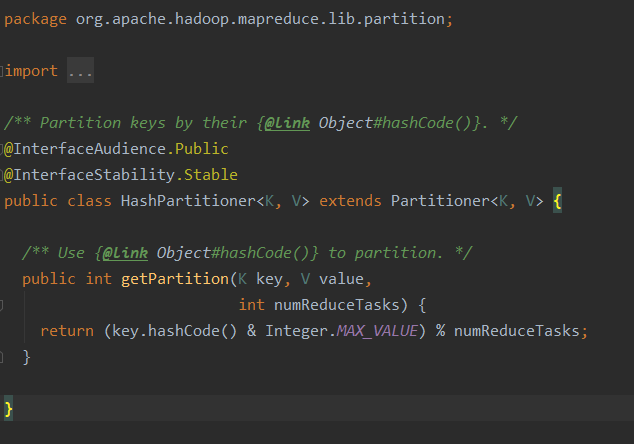
Custom partition needs to inherit the Partitioner and copy the getpariton() method
Custom partition class: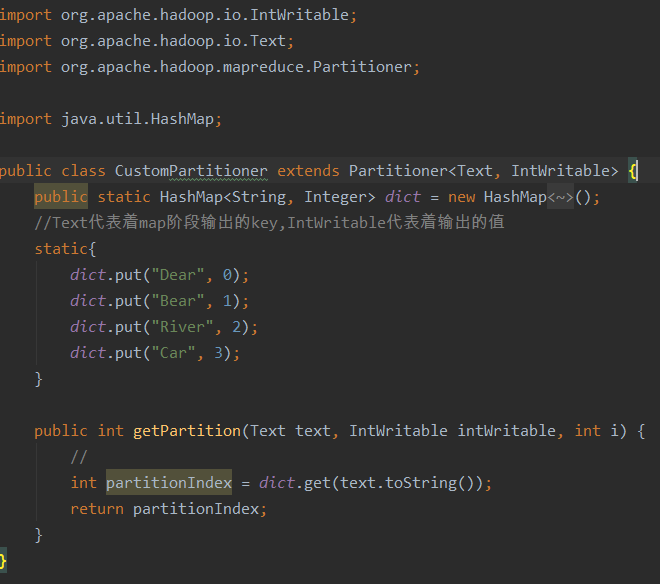
Note: the output of map is < K, V > key value pair
Where int partitionIndex = dict.get(text.toString()), partitionIndex is the value to get K
Attachment: calculated text
Dear Dear Bear Bear River Car Dear Dear Bear Rive Dear Dear Bear Bear River Car Dear Dear Bear Rive
It needs to be set in the main function to specify the custom partition class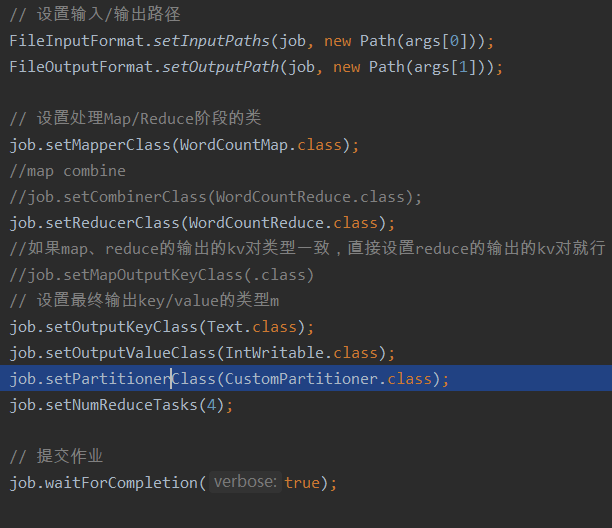
Custom partition class:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
public static HashMap<String, Integer> dict = new HashMap<String, Integer>();
//Text represents the key output in the map phase, and IntWritable represents the value output
static{
dict.put("Dear", 0);
dict.put("Bear", 1);
dict.put("River", 2);
dict.put("Car", 3);
}
public int getPartition(Text text, IntWritable intWritable, int i) {
//
int partitionIndex = dict.get(text.toString());
return partitionIndex;
}
}Note: the output result of map is the key value pair < K, V >, int partitionIndex = dict.get (text. Tostring()); the partitionIndex in map output key value pair is the key value, that is, the value of K.
Class Maper:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// Once for each word, output as intermediate result
context.write(new Text(word), new IntWritable(1));
}
}
}Reducer class:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split("\t");
for (String word : words) {
// Once for each word, output as intermediate result
context.write(new Text(word), new IntWritable(1));
}
}
}main function:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// jar bag
job.setJarByClass(WordCountMain.class);
// Set input / output format through job
//job.setInputFormatClass(TextInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
// Set input / output path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// Set the class to process the Map/Reduce phase
job.setMapperClass(WordCountMap.class);
//map combine
//job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//If the output kv pair types of map and reduce are the same, just set the output kv pair of reduce directly; if not, you need to set the output kv type of map and reduce respectively
//job.setMapOutputKeyClass(.class)
// Set the type m of the final output key/value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(CustomPartitioner.class);
job.setNumReduceTasks(4);
// Submit homework
job.waitForCompletion(true);
}
}main function parameter setting: