This article was first published in Simple book of mooring and floating purpose:https://www.jianshu.com/u/204...
| edition | date | remarks |
|---|---|---|
| 1.0 | 2021.12.20 | Article launch |
0. Preface
When I first came into contact with Flink, it was shared by some leading players in the industry - we will use it to process massive data. In this scenario, the problem of how to avoid the side effects of JVM GC brought by StopTheWorld has been lingering in my mind. After using Flink and reading the relevant source code (based on 1.14.0), I finally have some answers. I will share them with you in this article.
1. Insufficient JVM memory management
In addition to the StopTheWorld mentioned above, the memory management of the JVM also brings the following problems:
- Memory waste: when a Java object is stored in memory, it will be divided into three parts: object header, instance data and filling part. Firstly, in 32-bit and 64 bit implementations, the object header occupies 32 bit and 64 bit respectively. In order to provide overall efficiency, the data in the JVM memory is not stored continuously, but is stored in an integer multiple of 8byte. Even if you only have 1 byte, it will automatically padding7 bytes.
- Cache miss: as we all know, the CPU has L1, 2 and 3-level caches. When the CPU reads the data in memory, it will read the adjacent data in memory into the cache - this is a practical means of the principle of program locality. Data recently accessed by the CPU, In the short term, the CPU needs to access (time); the data near the data accessed by the CPU needs to be accessed by the CPU in the short term (space). However, as mentioned earlier, Java objects are not stored continuously on the heap, so when the CPU reads objects on the JVM, the cached data in the adjacent memory area is often not required for the CPU's next calculation. At this time, the CPU can only idle and wait for data to be read from memory (the speed of the two is not the same order of magnitude). If the data happens to be swap ped to the hard disk, it is even more difficult.
2. Flink's evolution scheme
In v0 Before 10, Flink used the implementation of on heap memory. Simply put, it is to allocate memory through Unsafe and reference it in the form of byte array. The application layer maintains type information to obtain corresponding data. But there are still problems:
- When the heap memory is too large, the JVM startup time will be very long, and the Full GC will reach the minute level.
- Low IO efficiency: at least one memory copy is required to write to the disk or network on the heap.
So in v0 After 10, Flink introduced out of heap memory management. See Jira: Add an off-heap variant of the managed memory . In addition to solving the problem of in heap memory, it also brings some benefits:
- Out of heap memory can be shared between processes. This means Flink can do some convenient fault recovery.
Of course, everything has two sides. The disadvantages are:
- Allocating objects with a short life cycle is more expensive on off heap memory than on heap memory.
- Troubleshooting is more complex when out of heap memory errors occur.
This implementation can also be found in Spark. It is called MemoryPool and supports both in heap and out of heap memory modes. See memorymode for details scala; Kafka has a similar idea - save its messages through the ByteBuffer of Java NIO.
3. Source code analysis
In general, the implementation of Flink in this area is relatively clear - like the operating system, there are memory segments and data structures such as memory pages.
3.1 memory segment
It is mainly implemented as MemorySegment. In V1 12 front MemorySegment
It is only an interface, and its implementation has two hybridmemorysegments and HeapMemorySegment. In the later development, we found that no one used HeapMemorySegment, but HybridMemorySegment. In order to optimize performance - to avoid checking the function table to confirm the called function every time, HeapMemorySegment was removed, and HybridMemorySegment was moved to MemorySegment - this will lead to nearly 2.7 times the call speed optimization.: Off-heap Memory in Apache Flink and the curious JIT compiler And Jira: Don't explicitly use HeapMemorySegment in raw format serde.
MemorySegment is mainly responsible for referencing memory segments and reading and writing data in them -- it supports basic types well, while complex types need external serialization. The specific implementation is relatively simple. We can roughly see the implementation from the declaration of field. The only thing I need to talk about is LITTLE_ENDIAN: different CPU architectures will have different storage order - PowerPC will adopt the Big Endian mode and store the least significant bytes at a low address; x86 uses Little Endian to store data, and low addresses store the most significant bytes.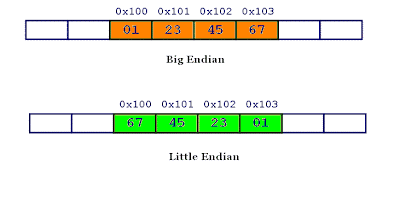
To tell you the truth, I was slightly shocked when I read this code, because I have written Java for so many years and almost have no perception of the underlying hardware. I didn't expect that Java code should consider the logic compatible with CPU architecture.
At this time, some students will ask, how does this MemorySegments work in Flink? We can see a test case: testPagesSer in BinaryRowDataTest:
First, there are MemorySegments, write data to RowData through the corresponding BinaryRowWriter, and then write RowData to RandomAccessOutputView through BinaryRowDataSerializer:
@Test
public void testPagesSer() throws IOException {
MemorySegment[] memorySegments = new MemorySegment[5];
ArrayList<MemorySegment> memorySegmentList = new ArrayList<>();
for (int i = 0; i < 5; i++) {
memorySegments[i] = MemorySegmentFactory.wrap(new byte[64]);
memorySegmentList.add(memorySegments[i]);
}
{
// multi memorySegments
String str = "Lala Lala, I'm a happy painter, Lala Lala, I'm a happy painter," + "Lala Lala, I'm a happy painter.";
BinaryRowData row = new BinaryRowData(1);
BinaryRowWriter writer = new BinaryRowWriter(row);
writer.writeString(0, fromString(str));
writer.complete();
RandomAccessOutputView out = new RandomAccessOutputView(memorySegments, 64);
BinaryRowDataSerializer serializer = new BinaryRowDataSerializer(1);
serializer.serializeToPages(row, out);
BinaryRowData mapRow = serializer.createInstance();
mapRow =
serializer.mapFromPages(
mapRow, new RandomAccessInputView(memorySegmentList, 64));
writer.reset();
writer.writeString(0, mapRow.getString(0));
writer.complete();
assertEquals(str, row.getString(0).toString());
BinaryRowData deserRow =
serializer.deserializeFromPages(
new RandomAccessInputView(memorySegmentList, 64));
writer.reset();
writer.writeString(0, deserRow.getString(0));
writer.complete();
assertEquals(str, row.getString(0).toString());
}
// ignore some code
}3.2 memory pages
A MemorySegment corresponds to a 32KB Memory block by default. In stream processing, it is easy to have more than 32KB of data, so it is necessary to cross MemorySegment. Then the person who writes the corresponding logic needs to hold multiple memorysegments. Therefore, Flink provides the implementation of Memory pages. It will hold multiple MemorySegment instances to facilitate the framework developers to quickly write Memory related code without paying attention to one MemorySegment.
It is abstracted as DataInputView and DataOutputView, which read and write data respectively.
Next, let's take a look at the actual code. Let's take our most common use of KafkaProducer as an example:
|-- KafkaProducer#invoke / / serializedValue is specified here \-- KeyedSerializationSchema#serializeValue / / serialize the value of record
Let's pick an implementation and take TypeInformationKeyValueSerializationSchema as an example:
|-- TypeInformationKeyValueSerializationSchema#Deserialize / / implementation class of keyedserializationschema |-- DataInputDeserializer#setBuffer / / this is the implementation of DataInputView, which uses an internal byte array to store data. It's strange that MemorySegement is not used here. |-- TypeSerializer#deserialize / / its implementation will read data from DataInputView and return data for different types
In fact, the example here is not appropriate. Because KeyedSerializationSchema has been marked as obsolete. The community recommends that we use Kafka serialization schema. The first reason is that the abstraction of KeyedSerializationSchema is not suitable for Kafka. When Kafka adds new fields to Record, it is difficult to abstract them in this interface - this interface only focuses on key, value and topic.
If we expand with KafkaSerializationSchema, we can look at the typical implementation - KafkaSerializationSchemaWrapper. We can find out what we care about:
@Override
public ProducerRecord<byte[], byte[]> serialize(T element, @Nullable Long timestamp) {
byte[] serialized = serializationSchema.serialize(element);
final Integer partition;
if (partitioner != null) {
partition = partitioner.partition(element, null, serialized, topic, partitions);
} else {
partition = null;
}
final Long timestampToWrite;
if (writeTimestamp) {
timestampToWrite = timestamp;
} else {
timestampToWrite = null;
}
return new ProducerRecord<>(topic, partition, timestampToWrite, null, serialized);
}This serializationschema declaration is an interface called serializationschema. You can see that it has a large number of implementations, many of which correspond to DataStream and format in SQL API. Take TypeInformationSerializationSchema as an example to continue tracking:
@Public
public class TypeInformationSerializationSchema<T>
implements DeserializationSchema<T>, SerializationSchema<T> {
//ignore some filed
/** The serializer for the actual de-/serialization. */
private final TypeSerializer<T> serializer;
....See the familiar interface TypeSerializer again. As mentioned above, its implementation will interact with different types from DataInputView and DataOutputView to provide the ability of serialization and deserialization. It can also be seen in its method signature:
/**
* Serializes the given record to the given target output view.
*
* @param record The record to serialize.
* @param target The output view to write the serialized data to.
* @throws IOException Thrown, if the serialization encountered an I/O related error. Typically
* raised by the output view, which may have an underlying I/O channel to which it
* delegates.
*/
public abstract void serialize(T record, DataOutputView target) throws IOException;
/**
* De-serializes a record from the given source input view.
*
* @param source The input view from which to read the data.
* @return The deserialized element.
* @throws IOException Thrown, if the de-serialization encountered an I/O related error.
* Typically raised by the input view, which may have an underlying I/O channel from which
* it reads.
*/
public abstract T deserialize(DataInputView source) throws IOException;
/**
* De-serializes a record from the given source input view into the given reuse record instance
* if mutable.
*
* @param reuse The record instance into which to de-serialize the data.
* @param source The input view from which to read the data.
* @return The deserialized element.
* @throws IOException Thrown, if the de-serialization encountered an I/O related error.
* Typically raised by the input view, which may have an underlying I/O channel from which
* it reads.
*/
public abstract T deserialize(T reuse, DataInputView source) throws IOException;
/**
* Copies exactly one record from the source input view to the target output view. Whether this
* operation works on binary data or partially de-serializes the record to determine its length
* (such as for records of variable length) is up to the implementer. Binary copies are
* typically faster. A copy of a record containing two integer numbers (8 bytes total) is most
* efficiently implemented as {@code target.write(source, 8);}.
*
* @param source The input view from which to read the record.
* @param target The target output view to which to write the record.
* @throws IOException Thrown if any of the two views raises an exception.
*/
public abstract void copy(DataInputView source, DataOutputView target) throws IOException;So how is TypeSerializer#deserialize called? These details are not what this article needs to care about. Here we show a call chain. Interested readers can look at the specific code along the call chain:
|-- TypeSerializer#deserialize |-- StreamElementSerializer#deserialize |-- TypeInformationKeyValueSerializationSchema#deserialize |-- KafkaDeserializationSchema#deserialize |-- KafkaFetcher#Partitionconsumerrecords handler / / it's clear here. Here are the objects from FlinkKafkaConsumer new
3.3 buffer pool
Another interesting class is LocalBufferPool, which encapsulates MemorySegment. It is generally used for network Buffer, which is the package of network exchange data. When the result partition starts to write data, it needs to apply for Buffer resources from LocalBufferPool.
Write logic:
|-- Task#constructor / / construction task |-- NettyShuffleEnvironment#createResultPartitionWriters / / create a result partition for writing results |-- ResultPartitionFactory#create \-- ResultPartitionFactory#createBufferPoolFactory / / a simple BufferPoolFactory is created here |-- PipelinedResultPartition#constructor |-- BufferWritingResultPartition#constructor |-- SortMergeResultPartition#constructor or BufferWritingResultPartition#constructor |-- ResultPartition#constructor \-- ResultPartition#Step / / register the buffer pool into the result partition
In addition, NetworkBuffer implements abstractreferencecountedbytebuffer of Netty. This means that the classic is used here Reference counting algorithm , when the Buffer is no longer needed, it will be recycled.
4. Others
4.1 relevant Flink Jira
The following is a list of Jira I have referred to when writing this article:
- Add an off-heap variant of the managed memory: https://issues.apache.org/jir...
- Separate type specific memory segments.: https://issues.apache.org/jir...
- Investigate potential out-of-memory problems due to managed unsafe memory allocation: https://issues.apache.org/jir...
- Adjust GC Cleaner for unsafe memory and Java 11: https://issues.apache.org/jir...
- FLIP-49 Unified Memory Configuration for TaskExecutors: https://issues.apache.org/jir...
- Don't explicitly use HeapMemorySegment in raw format serde: https://issues.apache.org/jir...
- Refactor HybridMemorySegment: https://issues.apache.org/jir...
- use flink's buffers in netty: https://issues.apache.org/jir...
- Add copyToUnsafe, copyFromUnsafe and equalTo to MemorySegment: https://issues.apache.org/jir...