Preface - From Wan Junfeng Kevin
The average delay of the service is basically about 30ms. One of the very big prerequisites is that we make extensive use of MapReduce technology, so that even if our service calls many services, it often depends only on the duration of the slowest request.

For your existing services, you do not need to optimize DB operations, cache, or rewrite business logic. You only need to parallelize orthogonal (irrelevant) requests through MapReduce, and you can greatly reduce the service response time.
In this article, ouyang'an will carefully analyze the implementation details of MapReduce.
Why MapReduce
In the actual business scenario, we often need to obtain the corresponding attributes from different rpc services to assemble into complex objects.
For example, to query product details:
- Commodity service - query commodity attributes
- Inventory service - query inventory attributes
- Price service - query price attribute
- Marketing Services - query marketing attributes
If it is a serial call, the response time will increase linearly with the number of rpc calls, so we generally change the serial to parallel to optimize the performance.
Using waitGroup in a simple scenario can also meet the requirements, but what if we need to verify, process, convert and summarize the data returned by rpc calls? It's a little difficult to continue using waitGroup. There is no such tool in the official library of go (CompleteFuture is provided in java). The author of go zero implements the data batch processing mapReduce concurrency tool class in the process according to the mapReduce architecture idea.
Design ideas
We try to put ourselves in the role of author and sort out the possible business scenarios of concurrency tools:
- Query product details: support concurrent call of multiple services to combine product attributes, and support call errors to end immediately.
- Automatically recommend user cards and coupons on the product details page: it supports concurrent verification of cards and coupons. If verification fails, all cards and coupons will be automatically eliminated and returned.
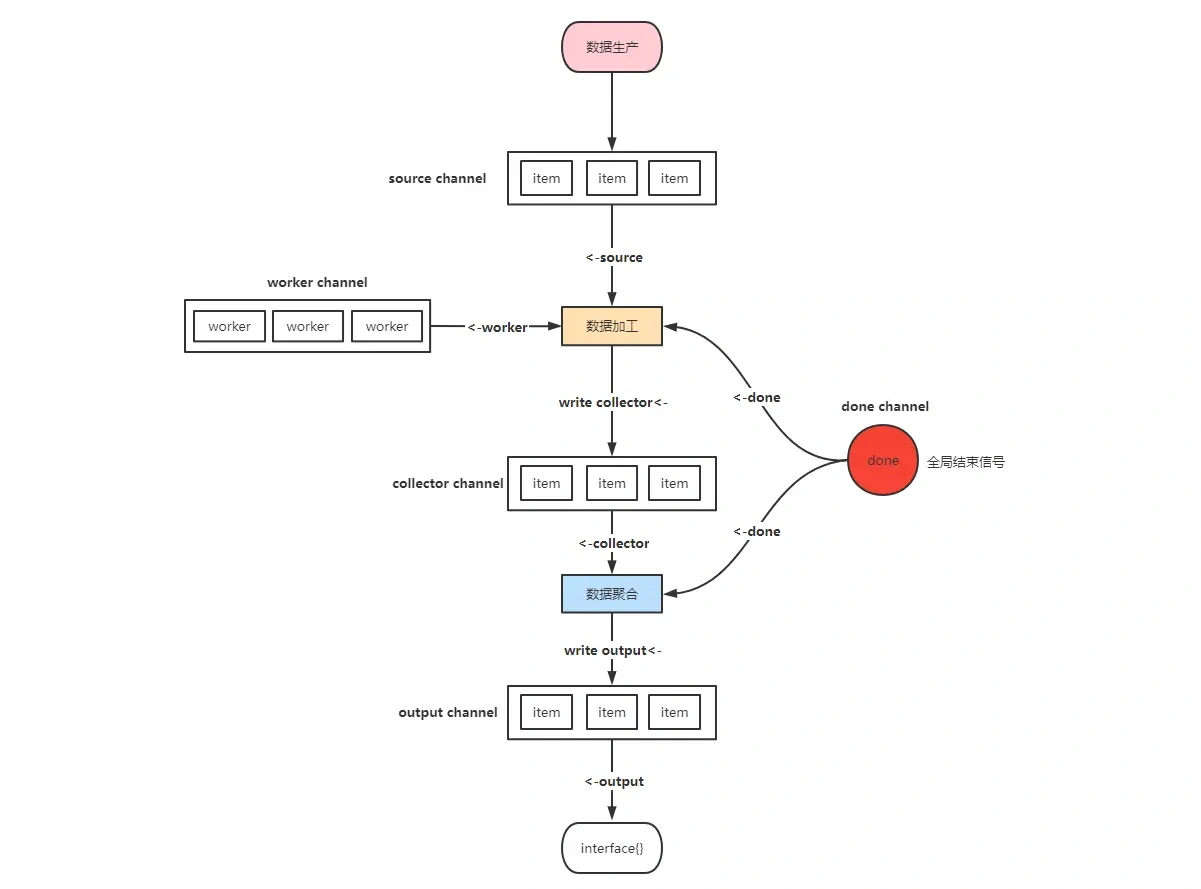
The above is actually processing the input data and finally outputting the cleaned data. There is a very classic asynchronous mode for data processing: producer consumer mode. Therefore, we can abstract the life cycle of data batch processing, which can be roughly divided into three stages:

- Data production generate
- Data processing mapper
- Data aggregation reducer
Among them, data production is an indispensable stage, data processing and data aggregation are optional stages, data production and processing support concurrent calls, and data aggregation basically belongs to pure memory operation, just a single collaborative process.
Let's think about how data should flow between different stages. Since data processing in different stages is performed by different goroutines, it is natural to consider using channel to realize communication between goroutines.

How to terminate the process at any time?
Very simple. Just listen to a global end channel in goroutine.
Go zero code implementation
core/mr/mapreduce.go
Detailed source code can be viewed github.com/Ouyangan/go-zero-annota...
Pre knowledge - basic usage of channel
Because channel is widely used for communication in MapReduce source code, let's mention the basic usage of channel:
- Remember to close the channel after writing
ch := make(chan interface{})
// After writing, you need to actively close the channel
defer func() {
close(ch)
}()
go func() {
// v. Read channel in OK mode
for {
v, ok := <-ch
if !ok {
return
}
t.Log(v)
}
// In the for range mode, the channel is read, the channel is closed, and the loop exits automatically
for i := range ch {
t.Log(i)
}
// Clear the channel, close the channel, and the cycle will exit automatically
for range ch {
}
}()
for i := 0; i < 10; i++ {
ch <- i
time.Sleep(time.Second)
}- Closed channel s still support reading
- Restrict channel read and write permissions
// Read only channel
func readChan(rch <-chan interface{}) {
for i := range rch {
log.Println(i)
}
}
// Write channel only
func writeChan(wch chan<- interface{}) {
wch <- 1
}Interface definition
Let's first look at the three core function definitions:
- Data production
- Data processing
- Data aggregation
// Data production func
// Source - data is written to source after being produced
GenerateFunc func(source chan<- interface{})
// Data processing func
// item - data produced
// Writer - call writer Write() can transfer the processed data back to reducer
// cancel - terminate process func
MapperFunc func(item interface{}, writer Writer, cancel func(error))
// Data aggregation func
// pipe - processed data
// Writer - call writer Write() can return the aggregated data to the user
// cancel - terminate process func
ReducerFunc func(pipe <-chan interface{}, writer Writer, cancel func(error))User oriented method definition
You can use this method to view official documents, which will not be repeated here
There are many user oriented methods, which are mainly divided into two categories:
- No return
- An error occurred in the execution process. Terminate immediately
- The execution process does not pay attention to errors
- There is a return value
- Write the source manually and read the aggregate data channel manually
- Manually write to the source and automatically read the aggregated data channel
- When an external source is passed in, the aggregate data channel is automatically read
// If func is executed concurrently, any error will immediately terminate the process
func Finish(fns ...func() error) error
// Execute func concurrently, and the process will not be terminated even if an error occurs
func FinishVoid(fns ...func())
// The user needs to manually write the production data into the source, and return a channel for reading after processing the data
// opts - optional parameter. Currently, it includes: number of collaborative processes in the data processing stage
func Map(generate GenerateFunc, mapper MapFunc, opts ...Option)
// No return value, no attention to errors
func MapVoid(generate GenerateFunc, mapper VoidMapFunc, opts ...Option)
// No return value, pay attention to the error
func MapReduceVoid(generate GenerateFunc, mapper MapperFunc, reducer VoidReducerFunc, opts ...Option)
// You need to manually write the production data to the source and return the aggregated data
// generate production
// mapper processing
// reducer aggregation
// opts - optional parameter. Currently, it includes: number of collaborative processes in the data processing stage
func MapReduce(generate GenerateFunc, mapper MapperFunc, reducer ReducerFunc, opts ...Option) (interface{}, error)
// Support the incoming data source channel and return aggregated data
// Source - data source channel
// mapper - read source content and process
// Reducer - send data to reducer aggregation after data processing
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error)The core methods are MapReduceWithSource and Map, and other methods call them internally. It's no problem to find out the MapReduceWithSource method.
MapReduceWithSource source source code implementation
Everything is in this picture
// Support the incoming data source channel and return aggregated data
// Source - data source channel
// mapper - read source content and process
// Reducer - send data to reducer aggregation after data processing
func MapReduceWithSource(source <-chan interface{}, mapper MapperFunc, reducer ReducerFunc,
opts ...Option) (interface{}, error) {
// Optional parameter settings
options := buildOptions(opts...)
// The aggregate data channel needs to manually call the write method to write to the output
output := make(chan interface{})
// output will only be read once in the end
defer func() {
// If there are multiple writes, it will cause blocking and lead to co process leakage
// Here, use for range to detect whether the data can be read out. Reading out the data indicates that it has been written for many times
// Why use panic here? It is better to remind the user that the usage is wrong than to fix it automatically
for range output {
panic("more than one element written in reducer")
}
}()
// Create a buffered chan with a capacity of workers
// This means that up to workers are allowed to process data at the same time
collector := make(chan interface{}, options.workers)
// Data aggregation task completion flag
done := syncx.NewDoneChan()
// Writers that support blocking writes to chan
writer := newGuardedWriter(output, done.Done())
// Single case off
var closeOnce sync.Once
var retErr errorx.AtomicError
// Data aggregation task has ended, send completion flag
finish := func() {
// It can only be closed once
closeOnce.Do(func() {
// Send the aggregation task completion signal, and the close function will write a zero value to chan
done.Close()
// Turn off data aggregation chan
close(output)
})
}
// Cancel operation
cancel := once(func(err error) {
// Set error
if err != nil {
retErr.Set(err)
} else {
retErr.Set(ErrCancelWithNil)
}
// Empty source channel
drain(source)
// Call completion method
finish()
})
go func() {
defer func() {
// Clear aggregate task channel
drain(collector)
// Capture panic
if r := recover(); r != nil {
// Call the cancel method to end immediately
cancel(fmt.Errorf("%v", r))
} else {
// Normal end
finish()
}
}()
// Perform data processing
// Note the writer Write writes the processed data to output
reducer(collector, writer, cancel)
}()
// Asynchronous execution of data processing
// source - Data Production
// collector - data collection
// done - end flag
// workers - Concurrent number
go executeMappers(func(item interface{}, w Writer) {
mapper(item, w, cancel)
}, source, collector, done.Done(), options.workers)
// The reducer writes the processed data to the output,
// Read the output when data return is required
// If the output is written more than twice
// Then you can also read data from the defer func at the beginning
// Thus, it can be detected that the user has called the write method multiple times
value, ok := <-output
if err := retErr.Load(); err != nil {
return nil, err
} else if ok {
return value, nil
} else {
return nil, ErrReduceNoOutput
}
}// Data processing
func executeMappers(mapper MapFunc, input <-chan interface{}, collector chan<- interface{},
done <-chan lang.PlaceholderType, workers int) {
// goroutine coordinated synchronization semaphore
var wg sync.WaitGroup
defer func() {
// Wait for the data processing task to complete
// Prevent the data processing collaboration from exiting directly before the data is processed
wg.Wait()
// Close data processing channel
close(collector)
}()
// channel with buffer. The buffer size is workers
// Control the number of CO processes for data processing
pool := make(chan lang.PlaceholderType, workers)
// Data processing writer
writer := newGuardedWriter(collector, done)
for {
select {
// Monitor the external end signal and end directly
case <-done:
return
// Control the number of data processing processes
// Buffer capacity - 1
// When there is no capacity, it will be blocked and wait for the capacity to be released
case pool <- lang.Placeholder:
// Blocking waiting for production data channel
item, ok := <-input
// If ok is false, the input has been closed or cleared
// Execute exit after data processing is completed
if !ok {
// Buffer capacity + 1
<-pool
// End this cycle
return
}
// wg synchronization semaphore + 1
wg.Add(1)
// better to safely run caller defined method
// Perform data processing asynchronously to prevent panic errors
threading.GoSafe(func() {
defer func() {
// wg synchronization semaphore-1
wg.Done()
// Buffer capacity + 1
<-pool
}()
mapper(item, writer)
})
}
}
}summary
I have watched the source code of mapReduce for about two nights. I am tired overall. On the one hand, I am not very proficient in my own go language, especially in the use of channel, which leads me to frequently stop to query relevant documents and understand the author's writing method. On the other hand, I really burn my brain (admire the author's thinking ability) by communicating between multiple goroutine s through channel.
Secondly, when looking at the source code, it will certainly look silly for the first time. In fact, it doesn't matter to find the entry of the program (common basic components are generally oriented methods). First read along the main line, understand each sentence of code, add comments, and then look at the branch code.
If there is something you really don't understand, check the submission record of this code. It is very likely to solve a bug change. For example, I haven't understood this code many times.
// The aggregate data channel needs to manually call the write method to write to the output
output := make(chan interface{})
// output will only be read once in the end
defer func() {
// If there are multiple writes, it will cause blocking and lead to co process leakage
// Here, use for range to detect whether the data can be read out. Reading out the data indicates that it has been written for many times
// Why use panic here? It is better to remind the user that the usage is wrong than to fix it automatically
for range output {
panic("more than one element written in reducer")
}
}()Finally, draw a flow chart and basically understand the source code. For me, this method is stupid but effective.
data
Go Channel details: colobu.com/2016/04/14/Golang-Chann...
Go zero MapReduce document: go-zero.dev/cn/mapreduce.html
Project address
Welcome to go zero and star support us!
Wechat communication group
Focus on the "micro service practice" official account and click on the exchange group to get the community community's two-dimensional code.