Preface
Starting today, I'm going to roll up my sleeve and write Python crawlers directly. The best way to learn a language is to do it purposefully, so I'm going to do this with 10 + blogs.Hope you can do it well.
In order to write the crawler well, we need to prepare a Firefox browser, also need to prepare the crawler tool, the crawler tool, I use the tcpdump that comes with CentOS, plus wireshark, these two software installation and use, I suggest you still learn, we should use them later.
Network request module requests
The large number of open source modules in Python makes coding very simple, and the first module we want the crawler to understand is requests.
Install requests
Open Terminal: Use Command
pip3 install requests
Waiting for installation to complete
Next, type the following command in the terminal
# mkdir demo # cd demo # touch down.py
The linux command above creates a folder named demo, then a down.py file. You can also use the GUI tool to create various files by right-clicking, just like you do with windows.
To improve the efficiency of development on linux, we need to install a visual studio code development tool
For how to install vscode, refer to the official https://code.visualstudio.com/docs/setup/linux Detailed instructions are provided.
For centos, the following are true:
sudo rpm --import https://packages.microsoft.com/keys/microsoft.asc sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/vscode\nenabled=1\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/yum.repos.d/vscode.repo'
Then install with the yum command
yum check-update sudo yum install code
After successful installation, the following image will appear in your CentOS
Next, let's talk about what we did above, because we have a gnome graphical interface here, so there are some operations that follow, and I'll explain them directly in the style of windows
Open Software > File > Open File > Find the down.py file we just created
After that, enter it in VSCODE
import requests #Import Module
def run(): #Declare a run method
print("Running code file") #print contents
if __name__ == "__main__": #Main Program Entry
run() #Call the run method above
tips: This tutorial is not an introductory Python 3 course, so there are some coding basics that you understand by default, such as Python without a semicolon end and need to align formats.I will try to write the comment as completely as possible
Press ctrl+s on the keyboard to save the file, if prompt permission is insufficient, then enter the password as prompted
Enter the demo directory through the terminal and enter
python3 down.py
Display the following results to indicate that compilation is OK
[root@bogon demo]# python3 down.py Running code file
Next, let's start testing if the requests module can be used
Modify the
import requests
def run():
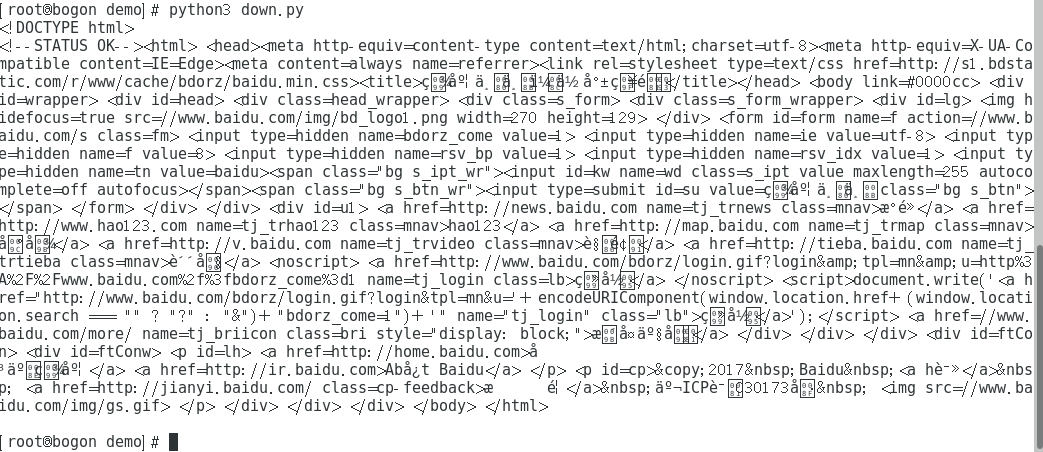
response = requests.get("http://www.baidu.com")
print(response.text)
if __name__ == "__main__":
run()
Run results (the following image shows you successfully run):
Next, let's actually try downloading a picture, like the one below

Modify the code, before that we'll modify something
Since every time you modify a file, you are prompted to have administrator privileges, so you can use the linux command to modify privileges.
[root@bogon linuxboy]# chmod -R 777 demo/
import requests
def run():
response = requests.get("http://www.newsimg.cn/big201710leaderreports/xibdj20171030.jpg")
with open("xijinping.jpg","wb") as f :
f.write(response.content)
f.close
if __name__ == "__main__":
run()After running the code, a file was found inside the folder
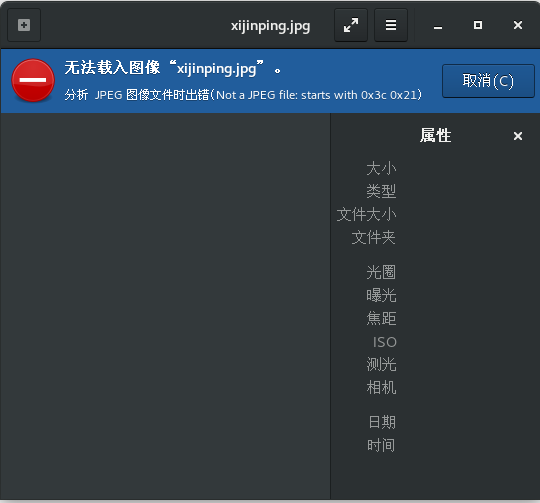
But when I opened the file, I found it was not accessible, which means it was not downloaded at all.
We continue to modify the code because there are some restrictions on the server pictures that we can open with the browser, but the Python code can't be downloaded completely.
Modify Code
import requests
def run():
# Header file, header is a dictionary type
headers = {
"Host":"www.newsimg.cn",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5383.400 QQBrowser/10.0.1313.400"
}
response = requests.get("http://www.newsimg.cn/big201710leaderreports/xibdj20171030.jpg",headers=headers)
with open("xijinping.jpg","wb") as f :
f.write(response.content)
f.close
if __name__ == "__main__":
run()
Okay, compile the python file at the terminal this time
python3 down.py
Picture downloaded
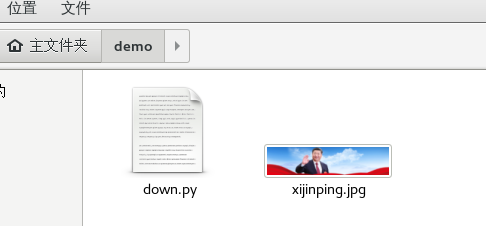
We focused on the requests.get section of the code above, adding a headers argument.So our program downloads the complete picture.
Python Crawler Page Analysis
With this simple case above, the next step will be much simpler.How do crawls work?
Enter Domain Name - > Download Source Code - > Analysis Picture Path - > Download Picture
That's his step above
enter field name
The website we're going to crawl today is called http://www.meizitu.com/a/pure.html
Why crawl this site because it's crawlable.
Okay, let's go ahead and analyze this page
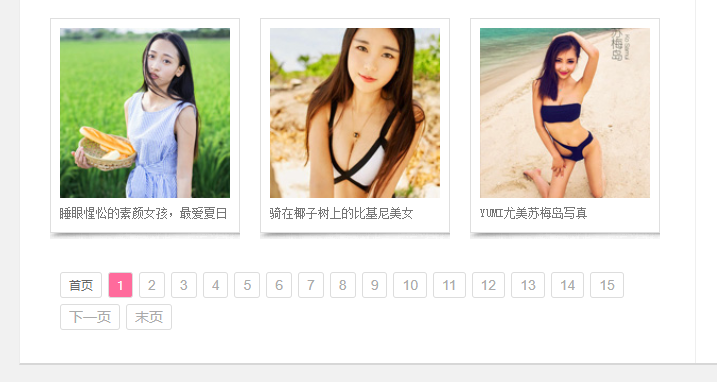
One important thing about being a crawler is that you need to find where to page because paging represents a regular, regular pattern, so we can crawl (you can do it smarter, enter the home page address, and the crawler can analyze all the addresses in this site by itself)
In the picture above, we found a page break, so find a rule
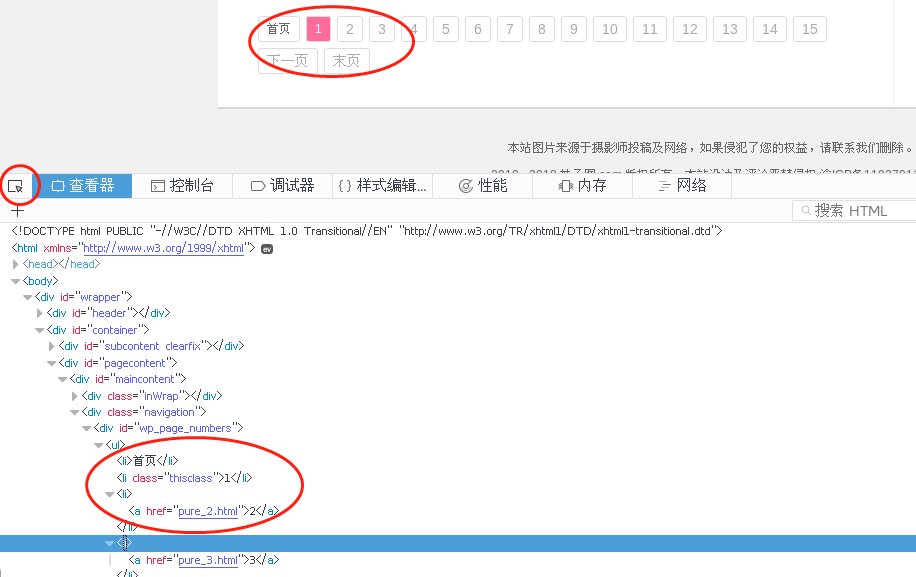
Discover Paging Rules Using Developer Tools for Firefox Browser
http://www.meizitu.com/a/pure_1.html http://www.meizitu.com/a/pure_2.html http://www.meizitu.com/a/pure_3.html http://www.meizitu.com/a/pure_4.html
Okay, then use Python to implement this part (there are some object-oriented writing, no basic students, please Baidu to find some basic, but for you to learn, these are very simple)
import requests
all_urls = [] #Our stitched galleries and list paths
class Spider():
#Constructor to initialize data use
def __init__(self,target_url,headers):
self.target_url = target_url
self.headers = headers
#Get all the URL s you want to grab
def getUrls(self,start_page,page_num):
global all_urls
#Loop to get URL s
for i in range(start_page,page_num+1):
url = self.target_url % i
all_urls.append(url)
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
target_url = 'http://www.meizitu.com/a/pure_%d.html' #Picture sets and list rules
spider = Spider(target_url,headers)
spider.getUrls(1,16)
print(all_urls)
The code above may require some Python basics to understand, but if you look closely, there are a few key points
The first is class Spider(): We declare a class, and then we use def u init_ to declare a constructor, which I think you'll learn in 30 minutes by looking for a tutorial.
There are many ways to stitch URL s, and I'm using the most direct, string stitching here.
Notice that there is a global variable all_urls in the code above that I use to store all our paging URL s
Next, it's the core part of the crawler code
We need to analyze the logic on the page.Open first http://www.meizitu.com/a/pure_1.html , right-click Review Elements.
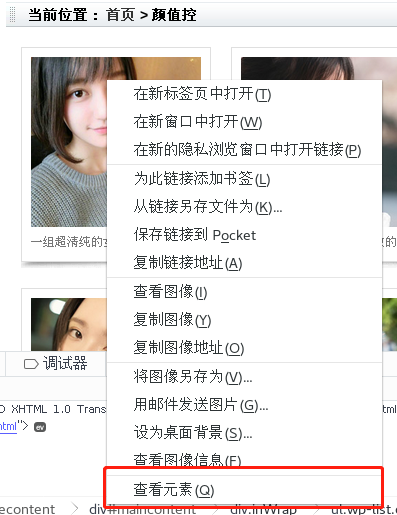
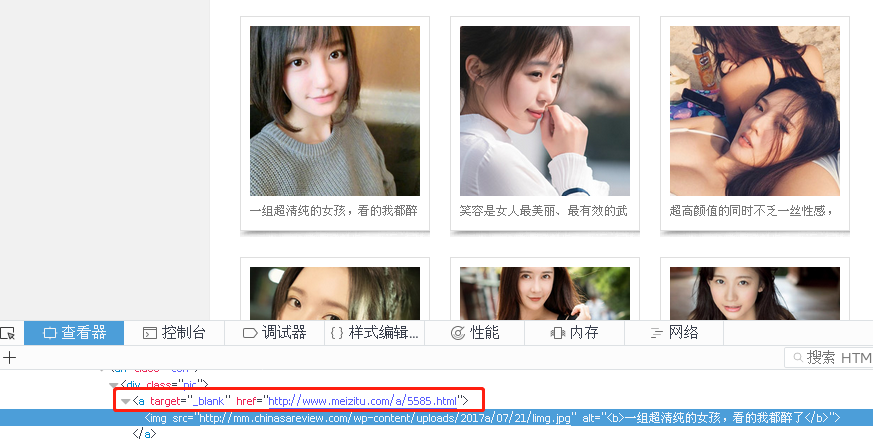
Discover links in the red box above
After clicking on the pictures, I find I go to a picture details page and find that there is actually a group of pictures. Now the problem is
We need to solve the first step http://www.meizitu.com/a/pure_1.html Crawl all of these pages http://www.meizitu.com/a/5585.html This address
Here we use multithreaded crawling (there is also a design pattern called the observer pattern)
import threading #Multithreaded module
import re #regular expression module
import time #Time Module
First, three modules are introduced, multithreaded, regular expression, and time module.
Add a new global variable, and since it is a multithreaded operation, we need to introduce a thread lock
all_img_urls = [] #Array of Picture List Pages
g_lock = threading.Lock() #Initialize a lock
Declare a producer's class that is used to constantly get the picture details page address and add it to the global variable all_img_urls
#Producer, responsible for extracting picture list links from each page
class Producer(threading.Thread):
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
global all_urls
while len(all_urls) > 0 :
g_lock.acquire() #Lock mechanism is required when accessing all_urls
page_url = all_urls.pop() #Remove the last element through the pop method and return the value
g_lock.release() #Release locks immediately after use to facilitate use by other threads
try:
print("Analysis"+page_url)
response = requests.get(page_url , headers = headers,timeout=3)
all_pic_link = re.findall('<a target=\'_blank\' href="(.*?)">',response.text,re.S)
global all_img_urls
g_lock.acquire() #There is also a lock here
all_img_urls += all_pic_link #Notice the splicing of arrays here. It's a new syntax for python to use += without append.
print(all_img_urls)
g_lock.release() #Release lock
time.sleep(0.5)
except:
pass
The code above uses the concept of inheritance, and I inherit a subclass from threading.Thread, which you can flip over http://www.runoob.com/python3/python3-class.html The novice bird tutorial is OK.
Thread lock, in the code above, when we operate all_urls.pop(), we don't want other threads to operate on it at the same time, otherwise there will be an accident, so we use g_lock.acquire() to lock the resource, and then after using it, remember to immediately release g_lock.release(), otherwise the resource will always be occupied and the program cannot proceed.Yes.
Match URL s in Web pages, I use regular expressions, and later we'll use other methods to match.
The re.findall() method is to get all the matches, regular expressions, and you can find a 30-minute introductory tutorial and see if that's OK.
Where the code goes wrong, I put it
try: except: inside, of course, you can also customize errors.
If the above code is OK, then we can write it at the program entry
for x in range(2):
t = Producer()
t.start()
Execute the program because our roducer inherits from the threading.Thread class, so one of the ways you have to do this is def run, which I believe you've seen in the code above.And then we can do it ~~
Run result:
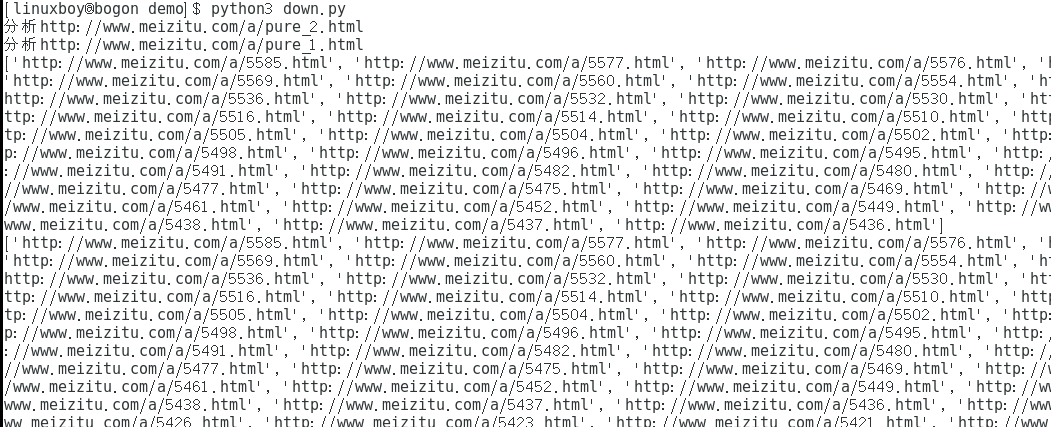
In this way, the list of picture details pages is already stored by us.
Next, we need to do this. I want to wait until the picture details page is all available for the next analysis.
Add code here
#threads= []
#Open two threads to access
for x in range(2):
t = Producer()
t.start()
#threads.append(t)
# for tt in threads:
# tt.join()
print("Come to me")
Comment on the key code and run as follows
[linuxboy@bogon demo]$ python3 down.py Analyze http://www.meizitu.com/a/pure_2.html Analyze http://www.meizitu.com/a/pure_1.html Come to me ['http://www.meizitu.com/a/5585.html',
Open the above tt.join and other code comments
[linuxboy@bogon demo]$ python3 down.py Analyze http://www.meizitu.com/a/pure_2.html Analyze http://www.meizitu.com/a/pure_1.html ['http://www.meizitu.com/a/5429.html', ...... Come to me
An essential difference is that we are multithreaded, so when the program runs, print("Going to Me") doesn't wait for the other threads to finish, it runs, but when we transform into the code above, adding the key code tt.join(), the main thread's code waits until the child thread finishes runningAfter that, run down.That's enough, as I just said, to get a collection of all the picture details pages first.
What a join does is thread synchronization, where the main thread enters a blocked state after it encounters a join and waits until the execution of other sub-threads is finished before the main thread continues.This person may meet frequently in the future.
Here's an array of consumer/observer pages that keep an eye on the pictures we've just captured.
Add a global variable to store the obtained picture links
pic_links = [] #Picture Address List
#Consumer
class Consumer(threading.Thread) :
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'www.meizitu.com'
}
global all_img_urls #Invoke an array of global picture details pages
print("%s is running " % threading.current_thread)
while len(all_img_urls) >0 :
g_lock.acquire()
img_url = all_img_urls.pop()
g_lock.release()
try:
response = requests.get(img_url , headers = headers )
response.encoding='gb2312' #Since the page code we're calling is GB2312, we need to set it up
title = re.search('<title>(.*?) | Beauty Girl</title>',response.text).group(1)
all_pic_src = re.findall('<img alt=.*?src="(.*?)" /><br />',response.text,re.S)
pic_dict = {title:all_pic_src} #python dictionary
global pic_links
g_lock.acquire()
pic_links.append(pic_dict) #Dictionary Array
print(title+" Success")
g_lock.release()
except:
pass
time.sleep(0.5)
See no, the code above is actually very similar to what we just wrote. Later, I will modify this part of the code on github more concisely, but this is the second lesson. We have a long way to go.
Some of the more important parts of the code I've written with comments, you can refer to them directly.It's important to note that I've used two regular expressions above, one for matching titles and one for URLs of images. This title is used to create different folders later, so be careful.
#Open 10 threads to get links
for x in range(10):
ta = Consumer()
ta.start()
Run result:
[linuxboy@bogon demo]$ python3 down.py Analyze http://www.meizitu.com/a/pure_2.html Analyze http://www.meizitu.com/a/pure_1.html ['http://www.meizitu.com/a/5585.html', ...... <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running Come to me <function current_thread at 0x7f7caef851e0> is running <function current_thread at 0x7f7caef851e0> is running Pure and picturesque, photographer's imperial beans succeed Ye Zixuan, the God of man and woman, succeeded in filming a group of popular portraits recently The Queen of the United States (bao) Chest (ru) brings the temptation of uniform to succeed Happy and successful are those who open their eyes to see you every day Lovely girl, may the warm wind take care of purity and persistence for success Pure sisters like a ray of sunshine warm this winter for success...
Do you feel you're a big step closer to success?
Next, let's do the same thing we mentioned about storing pictures, or write a custom class
class DownPic(threading.Thread) :
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST':'mm.chinasareview.com'
}
while True: # This place is written as an infinite loop to constantly monitor if the picture link array is updated
global pic_links
# Uplock
g_lock.acquire()
if len(pic_links) == 0: #Unlock if there are no pictures
# In any case, release the lock
g_lock.release()
continue
else:
pic = pic_links.pop()
g_lock.release()
# Walk through the dictionary list
for key,values in pic.items():
path=key.rstrip("\\")
is_exists=os.path.exists(path)
# Judgement Result
if not is_exists:
# Create a directory if it doesn't exist
# Create Directory Operation Function
os.makedirs(path)
print (path+'Directory created successfully')
else:
# Do not create if directory exists and prompt that directory already exists
print(path+' directory already exists')
for pic in values :
filename = path+"/"+pic.split('/')[-1]
if os.path.exists(filename):
continue
else:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
After we get the link to the picture, we need to download it. The code above is to create a file directory that we got to the title before, and then create a file in the directory with the code below.
Introducing a new module involving file operations
import os #Directory Operation Module
# Walk through the dictionary list
for key,values in pic.items():
path=key.rstrip("\\")
is_exists=os.path.exists(path)
# Judgement Result
if not is_exists:
# Create a directory if it doesn't exist
# Create Directory Operation Function
os.makedirs(path)
print (path+'Directory created successfully')
else:
# Do not create if directory exists and prompt that directory already exists
print(path+' directory already exists')
for pic in values :
filename = path+"/"+pic.split('/')[-1]
if os.path.exists(filename):
continue
else:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
Because of our picture link array, which holds the dictionary format of
[{"Sister 1":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]},{"Sister 2":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]},{"Sister 3":["http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/01.jpg","http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/02.jpg"."http://mm.chinasareview.com/wp-content/uploads/2016a/08/24/03.jpg"]}]
You need to loop through the first layer, get the title, create the directory, then download the pictures in the second layer. In the code, we're modifying it to add exception handling.
try:
response = requests.get(pic,headers=headers)
with open(filename,'wb') as f :
f.write(response.content)
f.close
except Exception as e:
print(e)
pass
Then write code in the main program
#Open 10 threads to save pictures
for x in range(10):
down = DownPic()
down.start()
Run result:
[linuxboy@bogon demo]$ python3 down.py Analyze http://www.meizitu.com/a/pure_2.html Analyze http://www.meizitu.com/a/pure_1.html ['http://www.meizitu.com/a/5585.html', 'http://www.meizitu.com/a/5577.html', 'http://www.meizitu.com/a/5576.html', 'http://www.meizitu.com/a/5574.html', 'http://www.meizitu.com/a/5569.html', ....... <function current_thread at 0x7fa5121f2268> is running <function current_thread at 0x7fa5121f2268> is running <function current_thread at 0x7fa5121f2268> is running Come to me Pure sisters like a ray of sunshine warm this winter for success Pure sisters like a ray of sunshine warm this winter catalog was created successfully Lovely girl, may the warm wind take care of purity and persistence for success Lovely girl, may warm wind care for purity and persistence create catalogue successfully Super beauty, pure you and blue sky complement each other for success Ultra-beautiful, pure catalogue created with you and blue sky Beautiful frozen person, successful Taekwondo girls in the snow The delicate eyebrows of five senses are like the success of a fairy tale princess Have a confident and charming smile, every day is a brilliant success The exquisite eyebrows of five senses are like the successful creation of the Princess Catalogue in fairy tales With a confident and charming smile, every day is a brilliant catalog created successfully Pure and picturesque, photographer's imperial beans succeed
Simultaneous occurrence under file directory
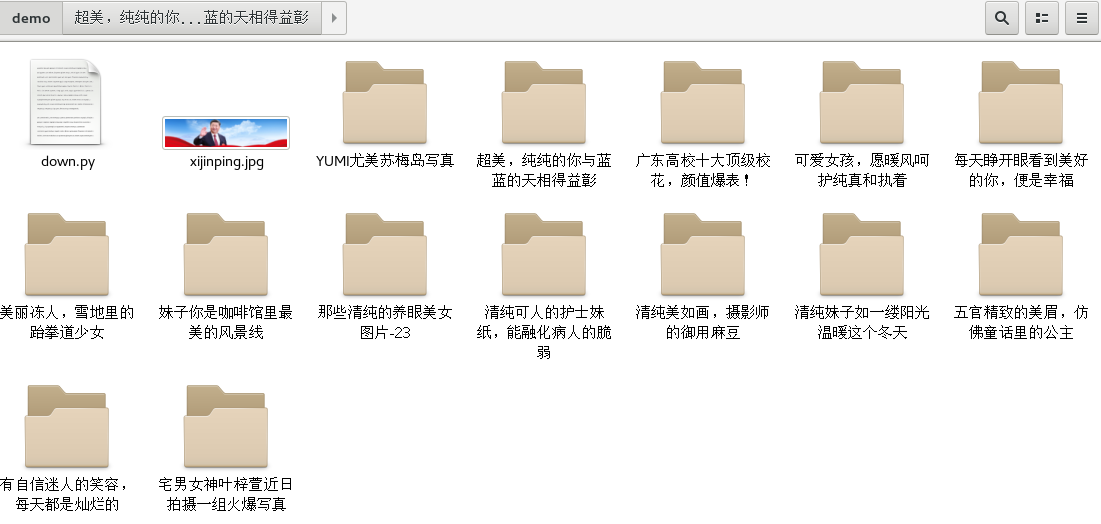
Click to open a directory

Okay, today's simple crawl is
Finally, we write it at the top of the code
# -*- coding: UTF-8 -*-
Prevent non-ASCII character'xe5'in file error problems.
Finally, put the github code address: