Keywords of this article:
Thread, thread pool, single thread, multithreading, benefits of thread pool, thread recycling, creation method, core parameters, underlying mechanism, rejection policy, parameter setting, dynamic monitoring, thread isolation
The knowledge related to threads and thread pools is a knowledge point that we will encounter in Java learning or interview. In this article, we will explain thread pools, the benefits of thread pools, creation methods, important core parameters, several important methods, underlying implementation, rejection strategy, parameter setting and dynamic adjustment from threads and processes, parallelism and concurrency, single thread and multithreading, Thread isolation and so on. The main outlines are as follows:
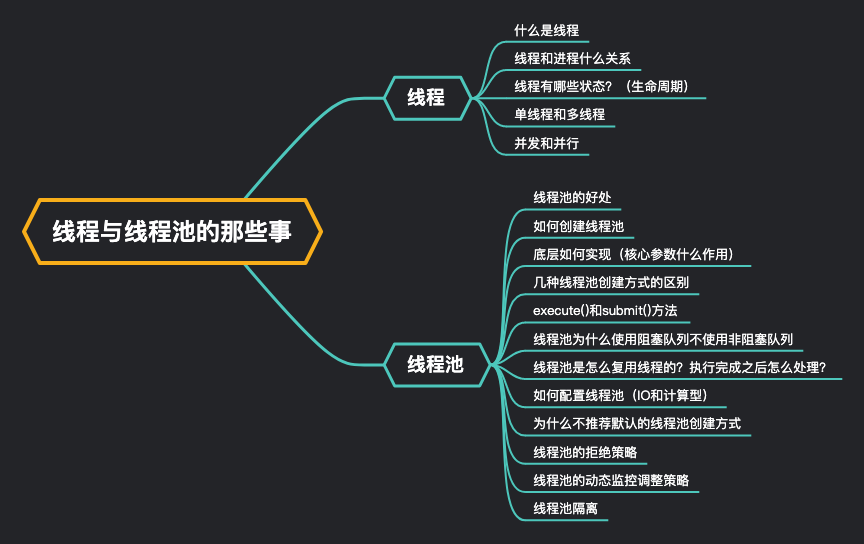
Benefits of thread pooling
Thread pool uses the idea of pooling to manage threads. Pooling technology is to maximize benefits, minimize user risks and manage resources together. This idea is used in many places, not just computers, such as finance, enterprise management, equipment management and so on.
Why thread pool? In a concurrent scenario, if the coder creates a thread pool according to requirements, there may be the following problems:
- It is difficult for us to determine how many threads are running in the system. If we create threads if we use them and destroy them if we don't use them, the consumption of creating and destroying threads is also relatively large
- Suppose there are many requests, maybe crawlers, crazy thread creation, which may exhaust the system resources.
What are the benefits of implementing thread pooling?
- Reduce resource consumption: pooling technology can reuse the created threads and reduce the loss of thread creation and destruction.
- Improve response speed: use existing threads for processing, reducing the time to create threads
- Controllable thread management: threads are scarce resources and cannot be created indefinitely. Thread pools can be uniformly allocated and monitored
- Expand other functions: such as timed thread pool, which can execute tasks regularly
In fact, pooling technology is used in many places, such as:
- Database connection pool: database connections are scarce resources. Create them first, improve response speed, and reuse existing connections
- Instance pool: first create objects in the pool and recycle them to reduce the consumption of back and forth creation and destruction
Thread pool related classes
The following is the inheritance relationship of classes related to thread pool:
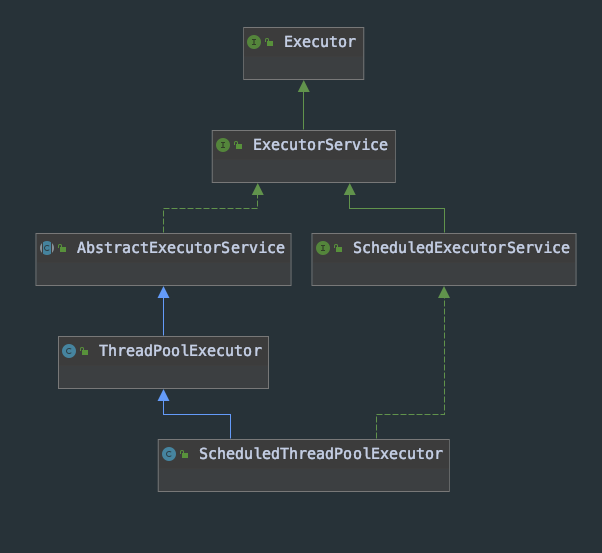
Executor
Executor is a top-level interface. There is only one method execute(Runnable command), which defines the scheduling thread pool to execute tasks. It defines the basic specification of thread pool, and executing tasks is its bounden duty.
ExecutorService
ExecutorService inherits from Executor, but it is still an interface. It has some more methods:
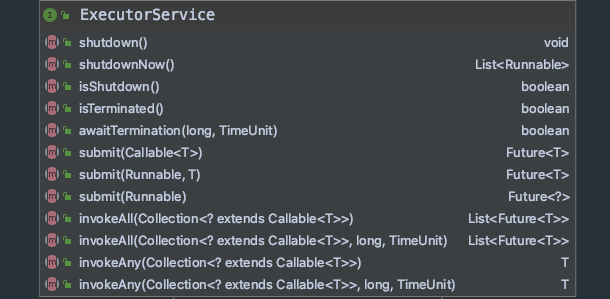
- void shutdown(): close the thread pool and wait for the task to finish executing.
- List < runnable > shutdownnow(): immediately close the thread pool, try to stop all actively executing tasks, stop the processing of waiting tasks, and return a list of waiting tasks (not yet executed).
- boolean isShutdown(): judge whether the thread pool has been closed, but the thread may still be executing.
- boolean isTerminated(): after executing shutdown / shutdown now, all tasks have been completed, and this state is true.
- Boolean await termination (long timeout, timeunit unit): after the shutdown is executed, the blocking will wait until the terminated state, unless it times out or is interrupted.
- <T> Future < T > submit (callable < T > task): submit a task with a return value, and return the future that has no result of the task, and call future The get () method can return the result when the task is completed.
- <T> Future < T > submit (runnable task, t result): submit a task and pass in the returned result. This result has no effect, but only specifies the type and a returned result.
- Future<?> Submit (runnable task): submit a task and return to future
- <T> List < Future < T > > invokeall (collection <? Extensions callable < T > > tasks): execute tasks in batch, obtain the list of Future, and submit tasks in batch.
- <T> List < future < T > > invokeall (collection <? Extends callable < T > > tasks, long timeout, timeunit unit): submit tasks in batch and specify the timeout time
- <T> T invokeany (collection <? Extensions callable < T > > tasks): blocking, obtaining the result value of the first completed task,
- <T> T invokeany (collection <? Extensions callable < T > > tasks, long timeout, timeunit unit): blocking, obtaining the value of the first completion result and specifying the timeout time
Some students may have questions about the previous < T > Future < T > submit (runnable task, t result). What is the function of this reuslt?
In fact, it has no effect. It just holds it. After the task is completed, it still calls future Get () returns this result. It uses result new to create an ftask. In fact, it uses RunnableAdapter, a wrapper class of Runnable. There is no special processing for the result. When calling the call() method, it returns this result directly. (specific implementation in Executors)
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
// Return incoming results
return result;
}
}
There is another method worth mentioning: invokeAny(): use the method invokeAny() in ExecutorService in ThreadPoolExecutor to obtain the result of the first completed task. When the first task is completed, it will call interrupt() method to interrupt other tasks.
Note that ExecutorService is an interface, which is defined and does not involve implementation. The previous explanations are based on its name (specified specification) and its general implementation.
You can see that ExecutorService defines some operations of the thread pool, including closing, judging whether to close, whether to stop, submitting tasks, batch submitting tasks, and so on.
AbstractExecutorService
AbstractExecutorService is an abstract class that implements the ExecutorService interface, which is the basic implementation of most thread pools. The timed thread pool is not concerned first. The main methods are as follows:
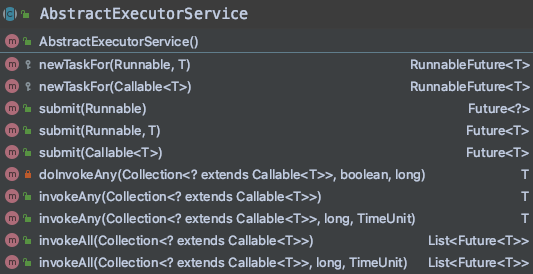
It not only implements the submit, invokeAll, invokeAny and other methods, but also provides a newTaskFor method to build RunnableFuture objects. Those objects that can obtain the returned results of the task are obtained through newTaskFor. Do not expand the introduction of all the source codes inside, just take the submit() method as an example:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
// Encapsulation task
RunnableFuture<Void> ftask = newTaskFor(task, null);
// Perform tasks
execute(ftask);
// Return RunnableFuture object
return ftask;
}
However, in AbstractExecutorService, the most important method is not implemented, that is, the execute() method. How does the thread pool execute? Different thread pools can have different implementations. Generally, they inherit AbstractExecutorService (scheduled tasks have other interfaces). The most commonly used one is ThreadPoolExecutor.
ThreadPoolExecutor
Here comes the point!!! ThreadPoolExecutor is generally the thread pool class we usually use. The so-called creation of thread pool is to use it if it is not a timed thread pool.
First look at the internal structure (property) of ThreadPoolExecutor:
public class ThreadPoolExecutor extends AbstractExecutorService {
// State control is mainly used to control the state of the thread pool. It is the core traversal and uses atomic classes
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// The number of bits used to represent the number of threads (bit operation is used. One part represents the number of threads and the other part represents the status of thread pool)
// SIZE = 32 indicates 32 bits, then COUNT_BITS is 29 bits
private static final int COUNT_BITS = Integer.SIZE - 3;
// The capacity of the thread pool, that is, the maximum value represented by 27 bits
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// State quantity, which is stored in the high order and the first three of the 32 bits
// 111 (the first bit is the sign bit, and 1 represents a negative number). The thread pool is running
private static final int RUNNING = -1 << COUNT_BITS;
// 000
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001
private static final int STOP = 1 << COUNT_BITS;
// 010
private static final int TIDYING = 2 << COUNT_BITS;
// 011
private static final int TERMINATED = 3 << COUNT_BITS;
// Take out the running state
private static int runStateOf(int c) { return c & ~CAPACITY; }
// Number of fetched threads
private static int workerCountOf(int c) { return c & CAPACITY; }
// Get ctl with running status and number of threads
private static int ctlOf(int rs, int wc) { return rs | wc; }
// Task waiting queue
private final BlockingQueue<Runnable> workQueue;
// Reentrant master lock (thread safe for some operations)
private final ReentrantLock mainLock = new ReentrantLock();
// Collection of threads
private final HashSet<Worker> workers = new HashSet<Worker>();
// In Condition, replace wait() with await(), notify() with signal() and notifyAll() with signalAll(),
// The traditional thread communication mode and condition can be realized. Condition is no different from traditional thread communication. The strength of condition is that it can establish different conditions for multiple threads
private final Condition termination = mainLock.newCondition();
// Maximum thread pool size
private int largestPoolSize;
// Number of tasks completed
private long completedTaskCount;
// Thread factory
private volatile ThreadFactory threadFactory;
// Task reject processor
private volatile RejectedExecutionHandler handler;
// Survival time of non core threads
private volatile long keepAliveTime;
// Timeout allowed for core threads
private volatile boolean allowCoreThreadTimeOut;
// Number of core threads
private volatile int corePoolSize;
// Maximum worker thread capacity
private volatile int maximumPoolSize;
// Default reject processor (discard task)
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
// Turn off license at runtime
private static final RuntimePermission shutdownPerm =
new RuntimePermission("modifyThread");
// context
private final AccessControlContext acc;
// Only one thread
private static final boolean ONLY_ONE = true;
}
Thread pool status
As can be seen from the above code, a 32-bit object is used to save the state of the thread pool and the capacity of the thread pool. The upper 3 bits are the state of the thread pool, while the remaining 29 bits are the number of threads saved:
// State quantity, which is stored in the high order and the first three of the 32 bits
// 111 (the first bit is the sign bit, and 1 represents a negative number). The thread pool is running
private static final int RUNNING = -1 << COUNT_BITS;
// 000
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 001
private static final int STOP = 1 << COUNT_BITS;
// 010
private static final int TIDYING = 2 << COUNT_BITS;
// 011
private static final int TERMINATED = 3 << COUNT_BITS;
Various states are different, and their changes are as follows:
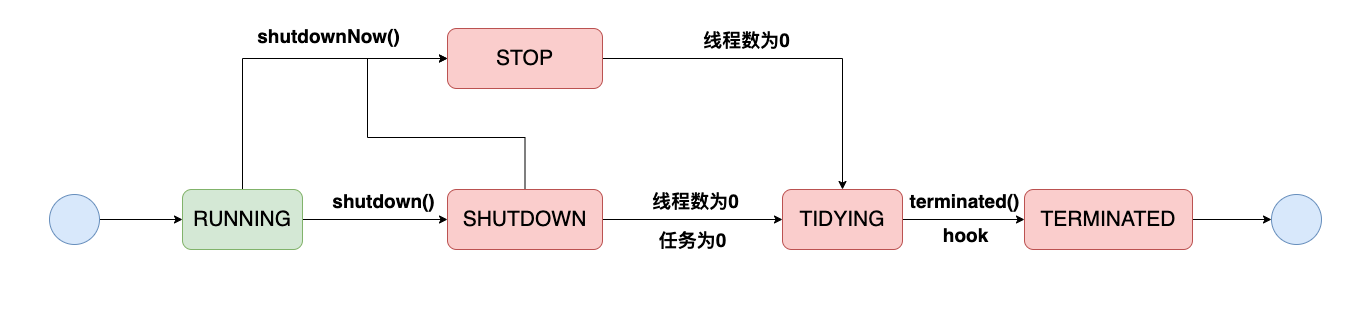
- RUNNING: RUNNING status. It can accept or process tasks
- SHUTDOWN: the task cannot be accepted, but it can be processed
- STOP: you cannot accept or process a task, or interrupt the current task
- TIDYING: all threads stop
- TERMINATED: the last state of the thread pool
Worker implementation
Thread pool must have a pool, and it is the place where threads are placed. It is represented as Worker in ThreadPoolExecutor. This is an internal class:

Thread pool is actually a collection of workers (workers who constantly receive and complete tasks). HashSet:
private final HashSet<Worker> workers = new HashSet<Worker>();
How is Worker implemented?
In addition to inheriting AbstractQueuedSynchronizer, that is, AQS, which is essentially a queue lock, a simple mutex lock, which is generally used when interrupting or modifying the worker state.
AQS is introduced internally for Thread safety. When a Thread executes a task, runWorker(Worker w) is called. This method is not the method of worker, but the method of ThreadPoolExecutor. As can be seen from the following code, every time the state of the worker is modified, it is Thread safe. Worker holds a Thread, which can be understood as the encapsulation of threads.
How does runWorker(Worker w) work? Keep this question first and explain it in detail later.
// Implement Runnable and encapsulate the thread
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
// Serialization id
private static final long serialVersionUID = 6138294804551838833L;
// worker running thread
final Thread thread;
// The initialization task may be empty. If the task is not empty, other incoming tasks can be run directly instead of being added to the task queue
Runnable firstTask;
// Thread task counter
volatile long completedTasks;
// Assign a task to keep workers busy. The task may be empty
Worker(Runnable firstTask) {
// Initialize the status of AQS queue lock
setState(-1); // Prohibit interruptions until runWorker
this.firstTask = firstTask;
// From the thread factory, take out a thread for initialization
this.thread = getThreadFactory().newThread(this);
}
// In fact, runWorker is called
public void run() {
// Continuously cycle to obtain tasks for execution
runWorker(this);
}
// 0 means it is not locked
// 1 indicates the locked state
protected boolean isHeldExclusively() {
return getState() != 0;
}
// Exclusive, trying to obtain the lock. If it succeeds, it returns true, and if it fails, it returns false
protected boolean tryAcquire(int unused) {
// CAS optimistic lock
if (compareAndSetState(0, 1)) {
// Success, current thread exclusive lock
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
// Exclusive mode, trying to release the lock
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
// Lock. AQS method is called
public void lock() { acquire(1); }
// Try locking
public boolean tryLock() { return tryAcquire(1); }
// Unlock
public void unlock() { release(1); }
// Is it locked
public boolean isLocked() { return isHeldExclusively(); }
// If it starts, it can be interrupted
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
Task queue
In addition to the setting out process pool, if there are many tasks and there are not so many threads, there must be a place to put tasks and act as a buffer, that is, the task queue, which is shown in the code as follows:
private final BlockingQueue<Runnable> workQueue;
Reject policy and processor
The memory of the computer is always limited, so we can't always add content to the queue, so the thread pool provides us with a choice, and we can choose a variety of queues. At the same time, when there are too many tasks, the threads are full, and the task queue is also full, we need to make a certain response, that is, reject or throw an error and lose the task? What tasks are lost, which may need to be customized.
How to create a thread pool
As for how to create a thread pool, the ThreadPoolExecutor actually provides a construction method. The main parameters are as follows. If it is not passed, the default will be used:
- Number of core threads: the number of core threads, which generally refers to the resident threads. When there is no task, it will not be destroyed
- Maximum number of threads: the maximum number of threads allowed to be created in the thread pool
- Survival time of non core threads: refers to how long non core threads can survive without tasks
- Unit of time: the unit of survival time
- Queue for storing tasks: used to store tasks
- Thread factory
- Reject processor: if adding a task fails, it will be processed by the processor
// Specify the number of core threads, the maximum number of threads, the survival time of non core threads without tasks, time unit, and task queue
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
// Specify the number of core threads, the maximum number of threads, the survival time of non core threads without tasks, time unit, task queue, thread pool factory
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
// Specify the number of core threads, the maximum number of threads, the survival time of non core threads without tasks, time unit, task queue, reject task processor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
}
// In the end, this method is actually called
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
In fact, in addition to specifying the above parameters, JDK also encapsulates some methods of directly creating thread pools for us, that is, Executors:
// Thread pool with fixed number of threads and unbounded queue
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
// The thread pool and unbounded queue of a single thread are executed serially according to the order of task submission
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
// Dynamic adjustment. There is no core thread. All threads are ordinary threads. Each thread survives for 60s and uses a blocking queue with a capacity of 1
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
// Timed task thread pool
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
However, it is generally not recommended to use the thread pool encapsulated by others above!!!
Bottom parameters and core methods of thread pool
After reading the above creation parameters, you may be a little confused, but it doesn't matter. Let's tell you one by one:
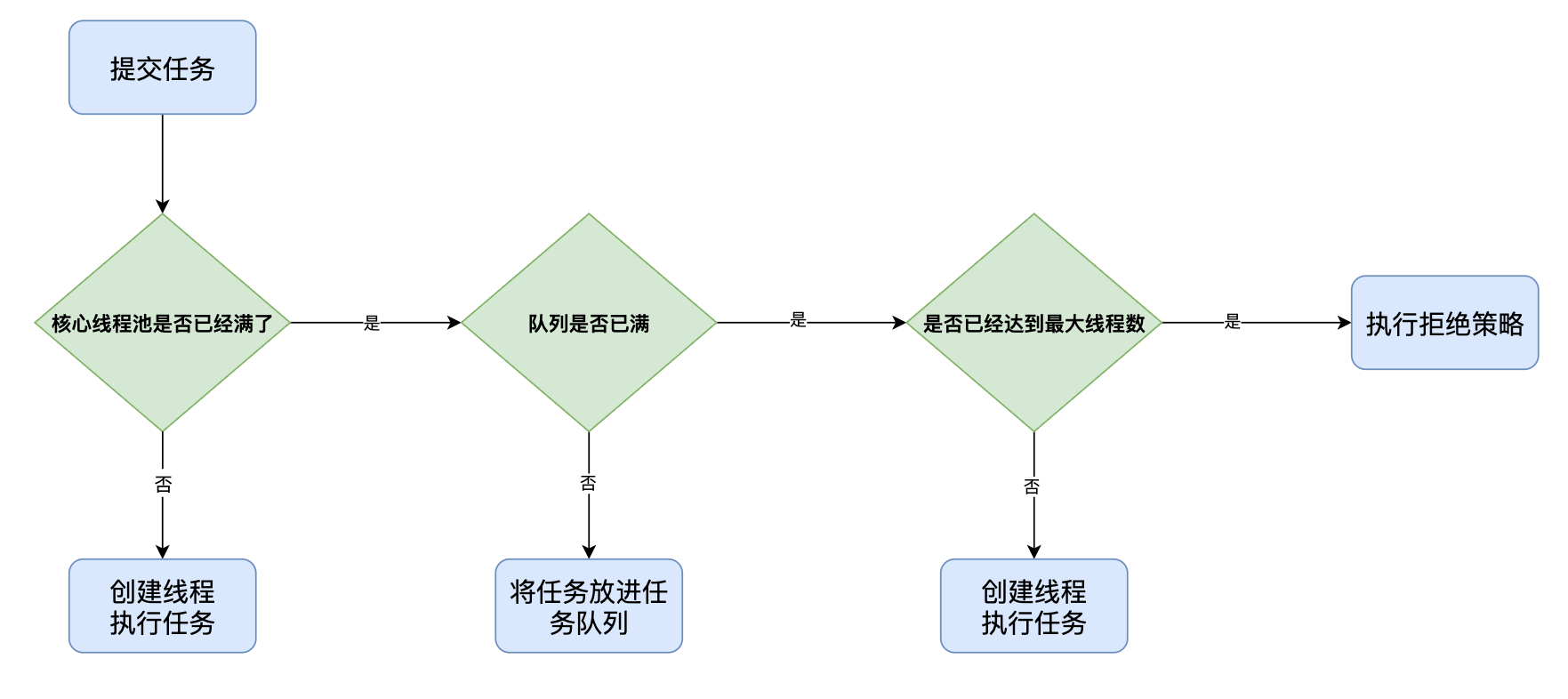
It can be seen that when a task comes in, first judge whether the core thread pool is full. If not, it will continue to create threads. Note that if a task comes in, creates a thread to execute, completes execution, and the thread is idle, will another task continue to use the previous thread, or recreate a thread to execute?
The answer is to recreate threads, so that the thread pool can quickly reach the size of the number of core threads, so as to quickly respond to subsequent tasks.
If the number of threads has reached the number of core threads, a task comes, and the threads in the thread pool are not idle, it will judge whether the queue is full. If the queue still has space, it will put the task into the queue and wait for the thread to receive and execute.
If the task queue is full and the task cannot be placed, it will judge whether the number of threads has reached the maximum number of threads. If not, it will continue to create threads and execute tasks. At this time, non core threads will be created.
If the maximum number of threads has been reached, we cannot continue to create threads. We can only execute the reject policy. The default reject policy is to discard tasks. We can customize the reject policy.
It is worth noting that if there are many tasks before and some non core threads are created, then when there are fewer tasks, you can't get the tasks. After a certain time, the non core threads will be destroyed, leaving only the number of threads in the core thread pool. This time is the previously mentioned keepAliveTime.
Submit task
When submitting a task, we see that execute() will first obtain the status and number of thread pools. If the number of threads has not reached the number of core threads, threads will be added directly, otherwise they will be placed in the task queue. If the task queue cannot be placed, threads will continue to be added, but not core threads.
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// Get status and number
int c = ctl.get();
// If the number is less than the number of core threads
if (workerCountOf(c) < corePoolSize) {
// Add directly
if (addWorker(command, true))
return;
// If adding fails, continue to get
c = ctl.get();
}
// Judge whether the thread pool is running, and put the task in the queue
if (isRunning(c) && workQueue.offer(command)) {
// Check again
int recheck = ctl.get();
// Determine whether the thread pool is still running
if (! isRunning(recheck) && remove(command))
// If not, reject and remove the task
reject(command);
else if (workerCountOf(recheck) == 0)
// If the number of threads is 0 and it is still running, add it directly
addWorker(null, false);
}else if (!addWorker(command, false))
// Failed to add task queue, rejected
reject(command);
}
In the above source code, we call an important method: addWorker(Runnable firstTask, boolean core). This method is mainly to increase the thread of work. Let's see how it executes.
private boolean addWorker(Runnable firstTask, boolean core) {
// Go back to the current location and try again
retry:
for (;;) {
// Get status
int c = ctl.get();
int rs = runStateOf(c);
// Greater than SHUTDOWN indicates that the thread pool has stopped
// ! (rs = = shutdown & & firsttask = = null & &! Workqueue. Isempty()) indicates that at least one of the three conditions is not met
// Not equal to shutdown indicates that it is greater than shutdown
// firstTask != null task is not empty
// workQueue.isEmpty() queue is empty
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// Number of worker threads
int wc = workerCountOf(c);
// Compliance with capacity
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// Add successfully, jump out of the loop
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// cas failed, try again
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// The previous thread count increased successfully
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// Created a worker and wrapped the task
w = new Worker(firstTask);
final Thread t = w.thread;
// Thread created successfully
if (t != null) {
// Acquire lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Reconfirm status
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// If the thread has started, it fails
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// Add thread to collection
workers.add(w);
// Get size
int s = workers.size();
// Determine the maximum number of thread pools
if (s > largestPoolSize)
largestPoolSize = s;
// Worker thread added
workerAdded = true;
}
} finally {
// Unlock
mainLock.unlock();
}
// If already added
if (workerAdded) {
// Start thread
t.start();
workerStarted = true;
}
}
} finally {
// If not started
if (! workerStarted)
// Failure handling
addWorkerFailed(w);
}
return workerStarted;
}
Processing tasks
When introducing the Worker class earlier, we explained that its run() method actually calls the external runWorker() method. Let's take a look at the runWorker() method:
First of all, it will directly handle its own firstTask. This task is not in the task queue, but held by itself:
final void runWorker(Worker w) {
// Current thread
Thread wt = Thread.currentThread();
// First task
Runnable task = w.firstTask;
// Reset to null
w.firstTask = null;
// Allow interruptions
w.unlock();
boolean completedAbruptly = true;
try {
// The task is not empty, or the obtained task is not empty
while (task != null || (task = getTask()) != null) {
// Lock
w.lock();
//If the thread pool stops, ensure that the thread is interrupted;
//If not, make sure the thread is not interrupted. this
//In the second case, recheck is required
// shutdown - now competition while clearing interrupts
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// Callback method before execution (can be implemented by ourselves)
beforeExecute(wt, task);
Throwable thrown = null;
try {
// Perform tasks
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// Callback method after execution
afterExecute(task, thrown);
}
} finally {
// Set to null
task = null;
// Update completed task
w.completedTasks++;
w.unlock();
}
}
// complete
completedAbruptly = false;
} finally {
// The processing thread exits the related work
processWorkerExit(w, completedAbruptly);
}
}
It can be seen from the above that if the current task is null, it will get a task. Let's take a look at getTask(), which involves two parameters, one is whether to allow the core thread to be destroyed, and the other is whether the number of threads is greater than the number of core threads. If the conditions are met, the task will be taken out of the queue. If it cannot be obtained after timeout, it will return null, It means that if the task is not retrieved, the previous cycle will not be executed, and the thread will be triggered to destroy processWorkerExit().
private Runnable getTask() {
// Timeout
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// The SHUTDOWN state continues to process tasks in the queue, but does not receive new tasks
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// Number of threads
int wc = workerCountOf(c);
// Whether core threads are allowed to timeout or the number of threads is greater than the number of core threads
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
// If the thread reduction succeeds, null will be returned, which will be processed by processWorkerExit()
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// If the core thread is allowed to close or exceed the core thread, you can get the task within the timeout time, or take out the task directly
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
// If you can get the task, you can certainly carry it out
if (r != null)
return r;
// Otherwise, you will not get the task and timeout
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
Destroy thread
As mentioned earlier, if the current task of the thread is empty and the core thread is allowed to be destroyed, or if the thread exceeds the number of core threads and waits for a certain time, but the task is not obtained from the task queue after timeout, it will jump out of the loop and execute to the subsequent thread destruction (end) program. What do I do when I destroy threads?
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// If the thread ends suddenly, the number of previous threads has not been adjusted, so it needs to be adjusted here
if (completedAbruptly)
decrementWorkerCount();
// Acquire lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Number of tasks completed
completedTaskCount += w.completedTasks;
// Remove thread
workers.remove(w);
} finally {
// Unlock
mainLock.unlock();
}
// Try to stop
tryTerminate();
// Get status
int c = ctl.get();
// Smaller than stop, at least shutdown
if (runStateLessThan(c, STOP)) {
// If it's not done suddenly
if (!completedAbruptly) {
// The minimum value is either 0 or the number of core threads. If the core threads are allowed to time out and destroy, it is 0
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// If the minimum is 0 or the queue is not empty, a thread is reserved
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// As long as the number of threads is greater than or equal to the minimum, the current thread is terminated
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// Otherwise, you may need to add new worker threads
addWorker(null, false);
}
}
How to stop a thread pool
To stop the thread pool, you can use shutdown() or shutdown now (). shutdown() can continue to process the tasks in the queue, while shutdown now () will immediately clean up the tasks and return the unexecuted tasks.
public void shutdown() {
// Acquire lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Check stop permission
checkShutdownAccess();
// Update status
advanceRunState(SHUTDOWN);
// Interrupt all threads
interruptIdleWorkers();
// callback hooks
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
// Stop now
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
// Acquire lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Check stop permission
checkShutdownAccess();
// Update status to stop
advanceRunState(STOP);
// Interrupt all threads
interruptWorkers();
// Clear queue
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
// Return to task list (incomplete)
return tasks;
}
execute() and submit() methods
- The execute() method can submit a task that does not need a return value, and cannot judge whether the task is successfully executed by the thread pool
- The submit() method is used to submit the task that needs the return value. The thread pool will return an object of type future. Through this object, we can block by calling the get() method until we get the result of the thread execution completion. At the same time, we can also use the wait method get (long timeout, TimeUnit unit) with timeout time. In this way, no matter whether the thread execution is completed or not, if it is time, it will not block and return null directly. The returned RunnableFuture object inherits the two interfaces of RunnableFuture < V >
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
Why do thread pools use blocking queues?
Blocking queue, first of all a queue, must have the property of first in first out.
Blocking is the evolution of this model. The general queue can be used in the production and consumer model, that is, data sharing. Someone puts tasks in it and someone constantly takes tasks out of it. This is an ideal state.
However, if it is not ideal, the speed of generating tasks and consuming tasks is different. If there are many tasks in the queue and the consumption is slow, you can consume them slowly, or the producer has to pause generating tasks (blocking the producer thread). You can use offer(E o, long timeout, TimeUnit unit) to set the waiting time. If you cannot add BlockingQueue to the queue within the specified time, it will return failure. You can also use put(Object) to put the object into the blocking queue. If there is no space, this method will block until there is space.
If the consumption speed is fast and the producer has no time to produce, when obtaining the task, you can use poll(time). If there is data, you can get it directly. If there is no data, you can wait for time and return null. You can also use take() to retrieve the first task. If there is no task, it will be blocked until there are tasks in the queue.
The above describes the properties of blocking queue, so why use it?
- If a task is generated, it is put into the queue when it comes, and the resources are easily exhausted.
- To create a thread, you need to obtain a lock. This is a global lock of the thread pool. If each thread continuously obtains and unlocks the lock, the overhead of thread context switching is also relatively large. It's better to wait when the queue is empty.
Common blocking queues
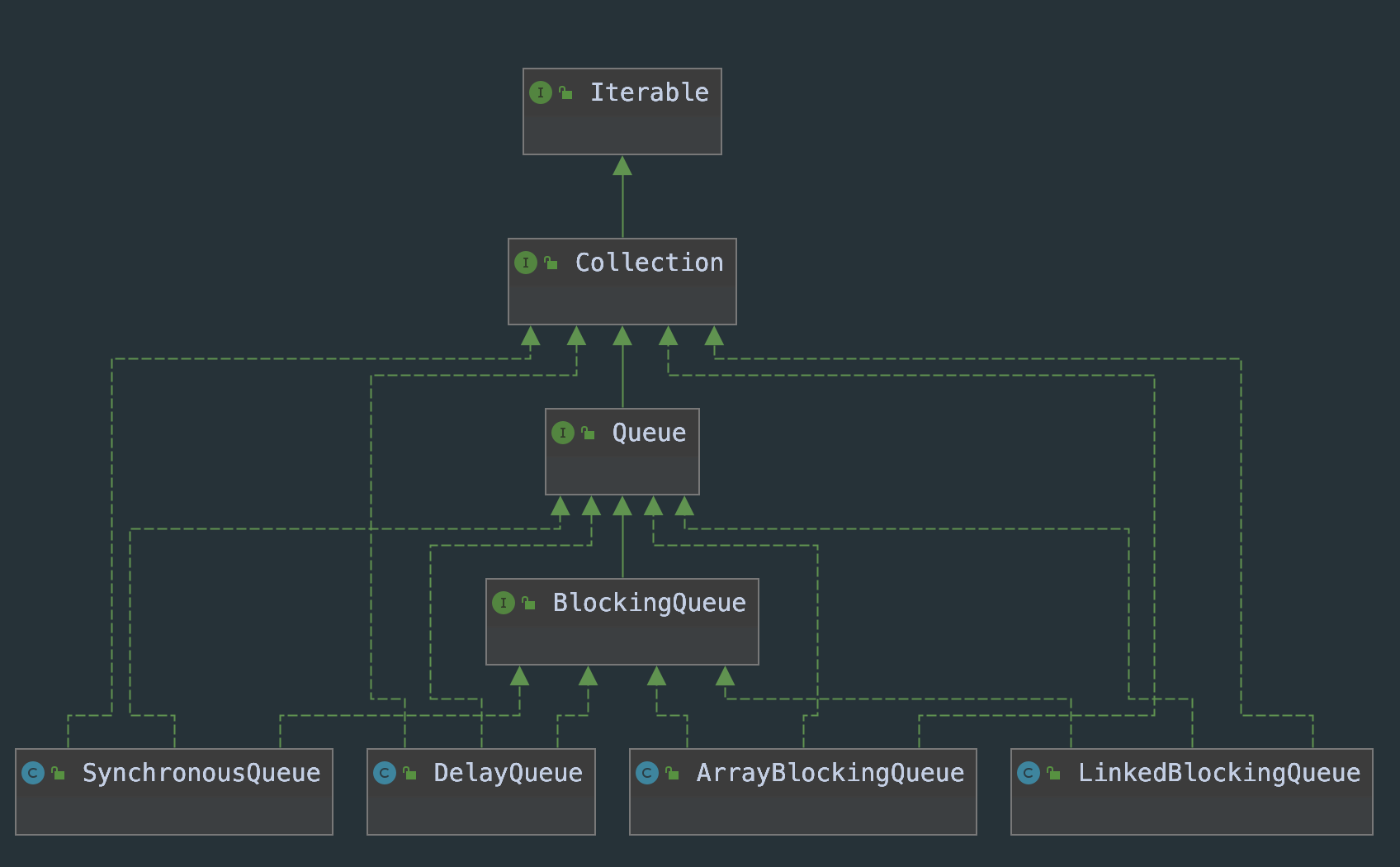
- ArrayBlockingQueue: Based on array implementation, there is a fixed length array inside, which saves the positions of the head and tail of the queue at the same time.
- LinkedBlockingQueue: blocking match based on linked list. Producers and consumers use independent locks and have strong parallelism. If the capacity is not specified, the default capacity is invalid, which is easy to run out of system memory.
- DelayQueue: delay queue. There is no size limit. Production data will not be blocked and consumption data will. This element can only be obtained from the queue when the specified delay time is up.
- PriorityBlockingQueue: a priority based blocking queue, which is consumed according to priority. The internal control synchronization is fair lock.
- SynchronousQueue: there is no buffer. The producer directly gives the task to the consumer, without the intermediate buffer.
How do thread pools reuse threads? How to deal with the completed thread
In the previous source code analysis, this problem has been explained. The thread of the thread pool calls the run() method, which actually calls runWorker(), which is an endless loop, unless the task cannot be obtained. If there is no task firstTask and the task cannot be obtained from the task queue, when it times out, it will judge whether the core thread can be destroyed, Or the number of core threads is exceeded. Only when the conditions are met will the current thread end.
Otherwise, it will always be in a cycle and will not end.
We know that the start() method can only be called once, so when calling the run() method, call the external runWorker(), and let it cycle continuously to obtain the task when runWorker(). Get the task and call the run() method of the task.
The thread that has completed execution will call processWorkerExit(), which is analyzed earlier. It will acquire locks, reduce the number of threads and remove them from the collection. After removal, it will judge whether there are too few threads. If so, it will be added back. I think it is a remedy.
How to configure thread pool parameters?
Generally speaking, there is a formula. If it is a computing (CPU) - intensive task, the number of core threads can be set to - 1 processor cores. If it is io intensive (many network requests), it can be set to 2 * processor cores. However, this is not a silver bullet. Everything should proceed from reality. It is best to conduct pressure test in the test environment and practice to get true knowledge. Many times, a machine has more than one thread pool or other threads, so the parameters should not be set too full.
Generally, for an 8-core machine, it is almost enough to set 10-12 core threads. All this must be calculated according to the specific value of the business. Setting too many threads, context switching, fierce competition and too few settings make it impossible to make full use of computer resources.
Computing (CPU) intensive consumption is mainly CPU resources. The number of threads can be set to N (number of CPU cores) + 1. One thread more than the number of CPU cores is to prevent accidental page interruption of threads or the impact of task suspension caused by other reasons. Once the task is suspended, the CPU will be idle, and in this case, an extra thread can make full use of the idle time of the CPU.
io intensive systems will spend most of their time dealing with I/O interaction, and threads will not occupy CPU for processing during the time period of dealing with I/O. at this time, they can hand over the CPU to other threads for use. Therefore, in the application of I/O-Intensive tasks, we can configure more threads. The specific calculation method is 2N.
Why not recommend the default thread pool creation method?
In Ali's programming specification, it is not recommended to use the default method to create threads, because the parameters of threads created in this way are often default. The creator may not know much about it and it is easy to have problems. It is best to create threads through new ThreadPoolExecutor() to facilitate parameter control. The problems created by default are as follows:
- Executors.newFixedThreadPool(): unbounded queue, memory may be burst
- Executors.newSingleThreadExecutor(): single thread, inefficient, serial.
- Executors.newCachedThreadPool(): there is no core thread, the maximum number of threads may be infinite, and the memory may explode.
To create a thread pool with specific parameters, developers must understand the role of each parameter and will not set parameters arbitrarily to reduce memory overflow and other problems.
It is generally reflected in several problems:
- How to set the task queue?
- How many core threads?
- What is the maximum number of threads?
- How to refuse the task?
- When creating a thread, there is no name, so it is difficult to find the traceability problem.
Rejection policy of thread pool
Thread pool generally has the following four rejection strategies. In fact, we can see from its internal classes:
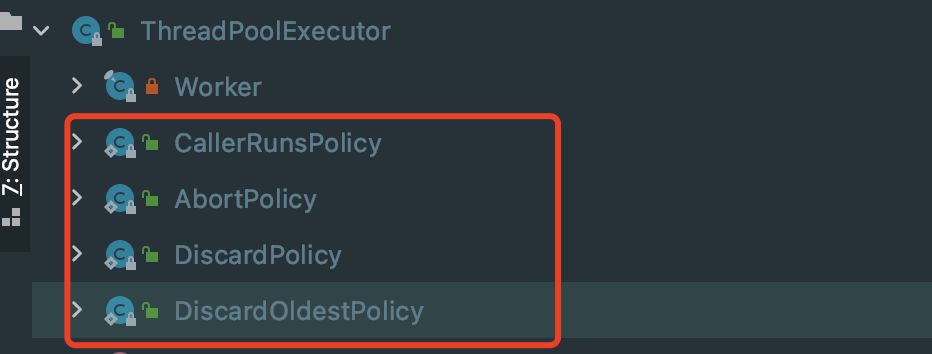
- AbortPolicy: throw an exception directly without executing a new task, indicating that the thread pool is full
- DisCardPolicy: it does not execute new tasks, but it will not throw exceptions. It is silent
- DisCardOldSetPolicy: discards the oldest task in the message queue and becomes a new task
- CallerRunsPolicy: directly call the current execute to execute the task
Generally speaking, the above rejection strategy is not particularly ideal. Generally, if the task is full, the first thing to do is to see whether the task is necessary. If it is not necessary and non core, you can consider rejecting it and report an error reminder. If it is necessary, you must save it. You can't lose the task whether using mq messages or other means. In these processes, logging is very necessary. We should not only protect the thread pool, but also be responsible for the business.
Thread pool monitoring and dynamic adjustment
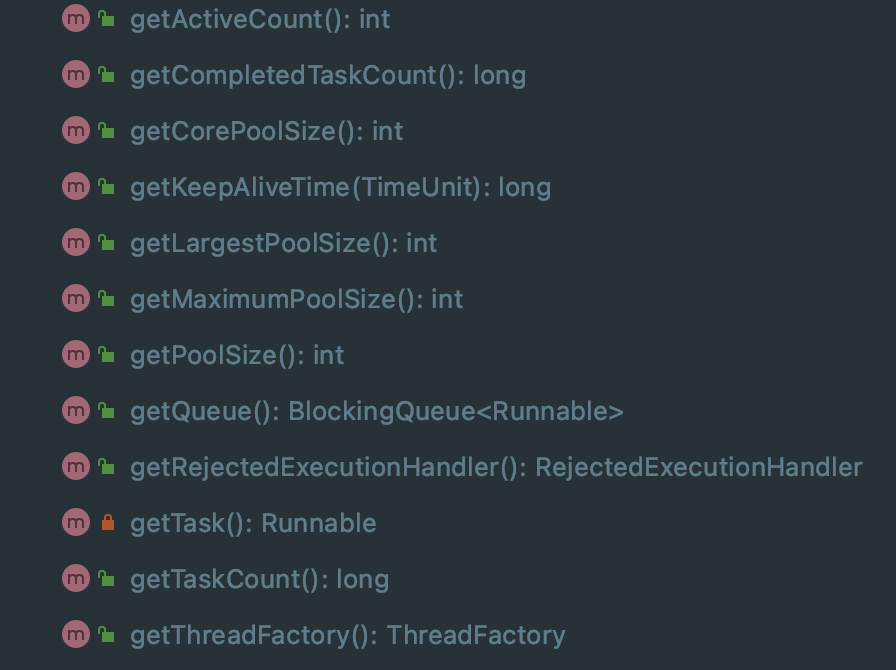
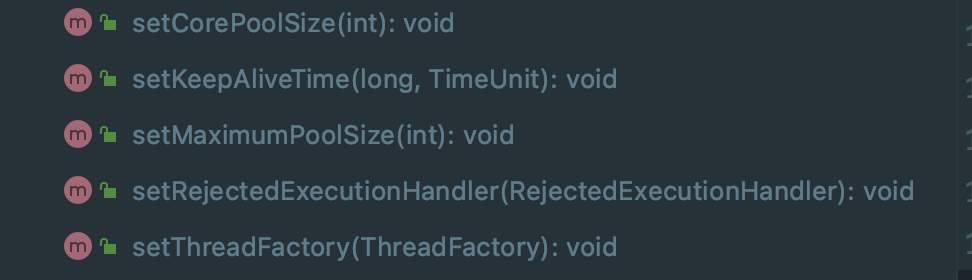
The thread pool provides API s to dynamically obtain the status of the thread pool, and set the parameters and status of the thread pool:
To view the status of the thread pool:
To modify the status of a thread pool:
On this point, meituan's thread pool article makes it very clear, and even makes a platform for real-time adjustment of thread pool parameters, which can track and monitor thread pool activity, task execution Transaction (frequency and time-consuming), Reject exception, internal statistical information of thread pool, etc. I won't start here https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html , this is the idea we can refer to.
Thread pool isolation
Thread isolation, as many students may know, is that different tasks are run in different threads, and thread pool isolation is generally isolated according to the business type. For example, the order processing thread is placed in a thread pool, and the member related processing is placed in a thread pool.
It can also be isolated through the core and non core. The core processing processes are put together and the non core processes are put together. The two use different parameters and different rejection strategies to ensure that multiple thread pools are not affected as much as possible, and the operation of the core thread is kept as much as possible. The non core thread can tolerate failure.
This technology is used in hystrix. Hystrix thread isolation technology is used to prevent avalanches between different network requests. Even if the thread pool of a dependent service is full, it will not affect other parts of the application.
About the author
Qin Huai, the official account of Qin Huai grocery store, is not in the right place for a long time. Personal writing direction: Java source code analysis, JDBC, Mybatis, Spring, redis, distributed, sword finger Offer, LeetCode, etc. I carefully write every article. I don't like the title party and fancy. I mostly write a series of articles. I can't guarantee that what I write is completely correct, but I guarantee that what I write has been practiced or searched for information. Please correct any omissions or mistakes.