What is pooling technology
Common pooling technologies include: connection pool, object pool, memory pool, thread pool, etc. The core of pooling technology is reuse.
Thread pool concept
The cost of starting a new thread is relatively high because it involves interaction with the operating system. Using thread pool can improve performance, especially when a large number of threads with short lifetime need to be created in the program.
Advantages of thread pool
- Reduce resource consumption. Reduce the overhead of thread creation and destruction by reusing the created threads.
- Improve response speed. When the task arrives, the task can be executed immediately without waiting for the thread to be created.
- Improve thread manageability. Threads are scarce resources. If they are created without restrictions, they will not only consume system resources, but also reduce the stability of the system. Using thread pool can be uniformly allocated, tuned and monitored.
Process of thread pool
- If the current number of wokers is less than the corePoolSize, create a new woker and assign the current task to the woker thread. If successful, return.
- If the first step fails, try to put the task into the blocking queue. If it succeeds, return.
- If the second step fails, judge that if the current number of wokers is less than maximumPoolSize, create a new woker and assign the current task to the woker thread. If it succeeds, return.
- If the third step fails, the reject policy is called to process the task.
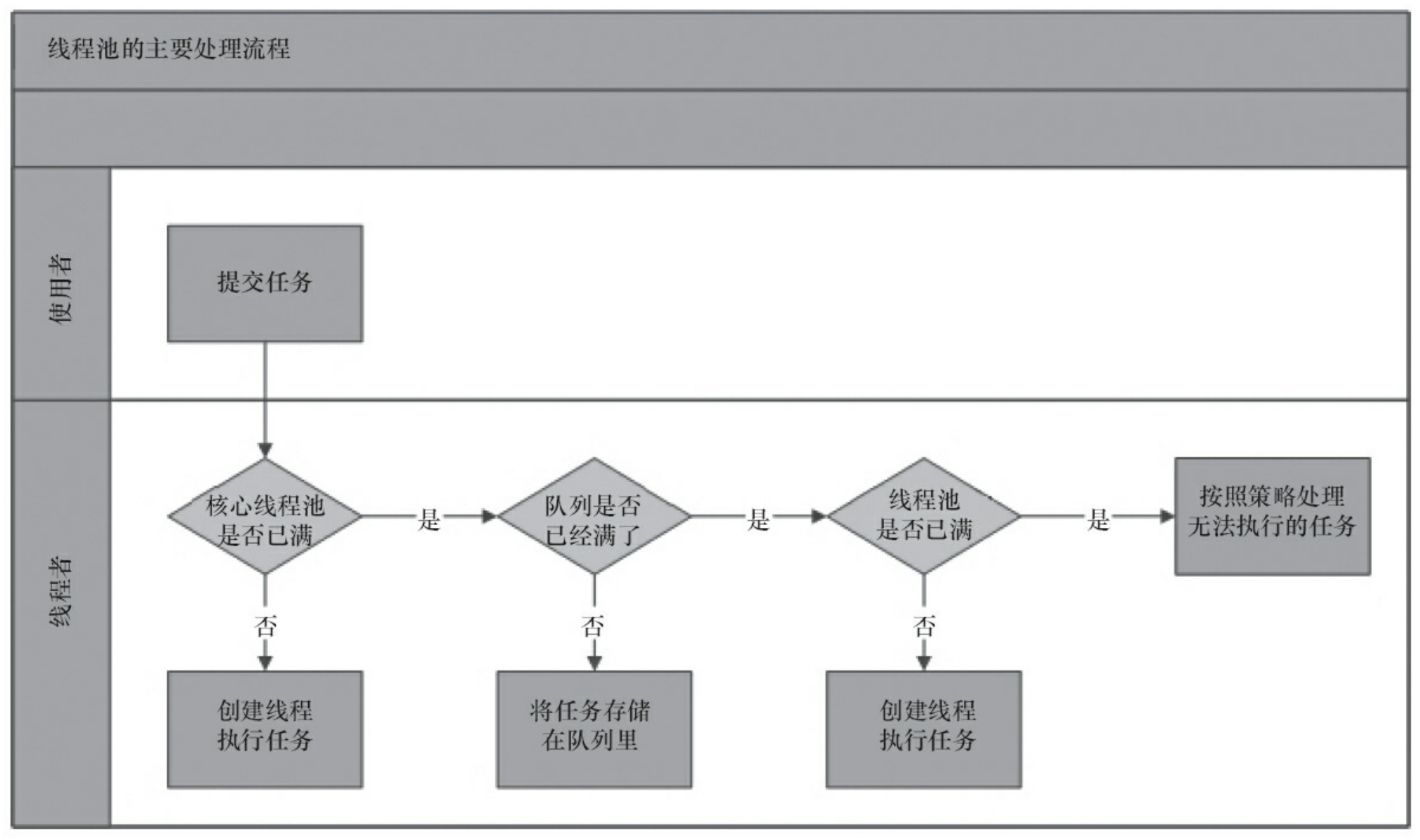
Implementation of thread pool
Create a series of threads in advance and save them in this thread pool. When there is a task to be executed, take out the thread from the thread pool to execute. When there is no task, put the thread back into the thread pool.
Core source code implementation
The essence of thread pool is to use a thread safe work queue to connect worker threads and client threads. Client threads return after putting tasks into the work queue, while worker threads constantly take work out of the work queue and execute it.
When the work queue is empty, all worker threads wait on the work queue. When a client submits a task, it will notify any worker thread. With a large number of tasks submitted, more worker threads will be awakened.
Note that the core thread will not be destroyed after completing the task, but will be blocked by the blocking queue when looping getTask(). Only when the number of threads is greater than the number of core threads, those ordinary threads will be destroyed.
Constructor parameters:
corePoolSize: The number of core threads in the thread pool. When a task is submitted, the thread pool creates a new thread to execute the task until the current number of threads is equal to corePoolSize,Even if there are other idle threads, they can perform new tasks,It will also continue to create threads; If the current number of threads is corePoolSize,The tasks that continue to be submitted are saved in the blocking queue and wait to be executed;
maximumPoolSize: The maximum number of threads allowed in the thread pool. If the current blocking queue is full and the task continues to be submitted, a new thread will be created to execute the task, provided that the current number of threads is less than maximumPoolSize;When a blocked queue is an unbounded queue,be maximumPoolSize It doesn't work,Because threads that cannot be committed to the core thread pool will continue to be put into the pool workQueue.
keepAliveTime: Thread lifetime(When the thread pool allows threads to timeout and the number of running threads exceeds corePoolSize When, the thread will be shut down according to the time set by this variable)
TimeUnit: keepAliveTime Unit of
BlockingQueue<Runnable> workQueue: Buffer queue, a blocking queue for tasks that are too late to execute
RejectedExecutionHandler handler: Reject processing task class (default: AbortPolicy Throw exception)
AbortPolicy: Throw an exception directly, default policy;
CallerRunsPolicy: Use the thread of the caller to execute the task;
DiscardOldestPolicy: Discard the top task in the blocking queue and execute the current task;
DiscardPolicy: Directly discard the task;
Of course, it can also be implemented according to the application scenario RejectedExecutionHandler Interface to customize saturation policies, such as logging or tasks that cannot be handled by persistent storage.
threadFactory: Create a thread factory. Through the custom thread factory, you can set a thread name with recognition for each new thread. Default to DefaultThreadFactory
---------------------------------------—
//constructor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor.java
private final BlockingQueue<Runnable> workQueue;//Buffer queue
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));//Atomic classes are used to count
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//1. The number of currently running threads is less than the number of core threads. Directly add the task to the worker to start running.
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
//If it fails, get the latest thread pool data
c = ctl.get();
}
/*2 When the number of running threads is greater than the number of core threads, the if branch above is for the case that the number of running threads is greater than the corePoolSize and the cache queue join task operation is successful.
It is running and the task is successfully added to the buffer queue. Normally, the processing logic has been completed.
However, for the sake of insurance, the confirmation judgment of abnormal state is added. If the state is abnormal, the remove operation will continue. If true, the task will be rejected according to the rejection processing policy;*/
//When the number of running threads is greater than the number of core threads, if the thread pool is still running, put the task into the blocking queue for execution.
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//When the task is successfully put into the queue, if recheck finds that the thread pool is no longer running, it will delete the task from the queue
if (! isRunning(recheck) && remove(command))
//After the deletion is successful, the rejection policy passed in by the construction parameter will be called.
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
/*3 Here, the number of running threads exceeds the corePoolSize and the cache queue is full.
Note that the second parameter is false, which can be seen in the addWorker method below, which is to judge the maximum number of threads in the thread pool and the maximumPoolSize.*/
else if (!addWorker(command, false))
//If the creation of a woker based on maximumPoolSize fails, the number of threads in the thread pool has reached the maximum and the queue is full, the reject policy passed in the construction parameters will be called
reject(command);
}
addWorker method
private boolean addWorker(Runnable firstTask, boolean core) {
// CAS + dead loop realizes the verification and update logic of thread pool status and thread number
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//Create a new worker thread with the specified task as a parameter
w = new Worker(firstTask);
//The variable t represents the woker thread
final Thread t = w.thread;
if (t != null) {
// Thread pool reentry lock
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// The thread starts and executes the task (worker. Thread (firsttask) start())
// Find the run method of the Worker's implementation
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
//If the woker fails to start, carry out some remedial work, such as modifying the current woker quantity, etc
addWorkerFailed(w);
}
return workerStarted;
}
Worker class
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
//The runWorker method is called in the Worker class run method.
public void run() {
runWorker(this);
}
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
runWorker method
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
//Task is the task specified by the Woker constructor input parameter, that is, the task submitted by the user
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
// First execute the firstTask, then get the task (getTask()) from the workerQueue, and execute it circularly
//We all know that the time set by the construction parameter represents the thread in the thread pool, that is, the survival time of the woker thread. If it expires, the woker thread will be recycled
//The implementation of this logic is in getTask.
//For tasks that are too late to execute, the thread pool will be put into a blocking queue. The getTask method is to get the task from the blocking queue. The survival time set by the user is
//Get the maximum waiting time of the task from the blocking queue. If getTask returns null, it means that woker has waited for the specified time and still hasn't finished
//When the task is retrieved, the loop body will be skipped and the destruction logic of woker thread will be entered.
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//This method is an empty implementation. If necessary, users can inherit this class for implementation
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run(); //The run method that runs the incoming thread
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//When the specified task is completed and the executable task cannot be obtained from the blocking queue, it will enter here to do some aftermath work
//For example, woker between corePoolSize and maximumPoolSize will be recycled
processWorkerExit(w, completedAbruptly);
}
}
getTask() method
Get tasks from the blocking task queue. If allowCoreThreadTimeOut(true) is set or the number of currently running tasks is greater than the set number of core threads, then timed =true. Workqueue is used Poll (keepalivetime, timeunit. Nanoseconds) fetches tasks from the task queue. If it is not set, then workqueue take() takes the task. For the blocking queue, poll(long timeout, TimeUnit unit) will go to the task within the specified time. If it is not taken, it will return null. take() will keep blocking, waiting for the task to be added.
At this point, I believe we can understand why our thread pool can wait for the execution of tasks without being destroyed. In fact, it just enters the blocking state.
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
//Dead cycle
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling? Note that this determines whether to destroy the thread
//The condition is that allowCoreThreadTimeOut is enabled, or the number of bus processes is greater than the number of core threads
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
Use of thread pool
Java provides four thread pools through Executors:
- newCachedThreadPool creates a cacheable thread pool. If the length of the thread pool exceeds the processing needs, idle threads can be recycled flexibly. If there is no recyclable thread, a new thread will be created.
- newFixedThreadPool creates a fixed length thread pool, which can control the maximum concurrent number of threads. The exceeded threads will wait in the queue.
- newScheduledThreadPool creates a fixed length thread pool that supports scheduled and periodic task execution.
- Newsinglethreadexecution creates a singleton thread pool, which only uses a unique worker thread to execute tasks, ensuring that all tasks are executed in the specified order (FIFO, LIFO, priority).
The bottom layers of these four thread pools are generated by the constructor of ThreadPoolExecutor.
//Fixed length linear pool
//The value of corePoolSize is the same as that of maximumPoolSize, and an unbounded blocking queue is passed in at the same time
//The threads in this thread pool will be maintained at the specified number of threads and will not be recycled
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//Cache thread pool
//The thread pool corePoolSize is 0 and maximumPoolSize is integer MAX_ VALUE
//This means that a woker is created for a task, and the recovery time is 60s
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
//Scheduling thread pool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
//Single pass pool
//There is only one thread in the thread pool for task execution, and the others are put into the blocking queue
//The wrapped FinalizableDelegatedExecutorService class implements the finalize method, which will close the thread pool during JVM garbage collection
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
Use examples:
import java.util.*;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();//Create a cacheable thread pool
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);//Create a fixed length thread pool to control the maximum concurrent number of threads. The exceeded threads will wait in the queue
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(3);//Create a fixed length routing pool to support regular and periodic task execution
ExecutorService single = Executors.newSingleThreadExecutor();//Create a singleton thread pool, which will only use a unique working thread to execute tasks, and ensure that all tasks are executed in the specified order (FIFO, LIFO, priority)
for(int i=0;i<10;i++){
final int index = i;
try {
Thread.sleep(index*500);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(index);
}
});
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(index);
}
});
//Regular 3s execution
scheduledExecutorService.schedule(new Runnable() {
@Override
public void run() {
System.out.println("delay 3s");
}
}, 3, TimeUnit.SECONDS);
single.execute(new Runnable() {
@Override
public void run() {
System.out.println(index);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
Two methods can be used to submit tasks to the thread pool: execute() and submit().
The submit() method is used to submit the task that needs the return value. The thread pool will return an object of type future through this
The future object can judge whether the task is executed successfully, and the return value can be obtained through the get() method of future. The get() side
Method will block the current thread until the task is completed, while using get (long timeout, timeunit) method will block the current thread
The process returns immediately after a period of time. At this time, it is possible that the task has not been completed.
Future<Object> future = executor.submit(harReturnValuetask);
try {
Object s = future.get();
} catch (InterruptedException e) {
// Handling interrupt exceptions
} catch (ExecutionException e) {
// Handle the exception of unable to execute the task
} finally {
// Close thread pool
executor.shutdown();
}
Thread pool design size
Tasks are generally divided into CPU intensive and IO intensive
The higher the proportion of thread waiting time, the more threads are required. The higher the proportion of thread CPU time, the fewer threads are required.
Estimation formula:
Optimal number of threads = ((thread waiting time + thread CPU time) / thread CPU time) * number of CPUs
Optimal number of threads = (ratio of thread waiting time to thread CPU time + 1) * number of CPUs
General experience sets the size
1. CPU intensive
Try to use a smaller thread pool. Generally, the number of Cpu cores is + 1
Because the CPU utilization of CPU intensive tasks is very high, if you open too many threads, you can only increase the number of thread context switches and bring additional overhead
2. IO intensive
Method 1: you can use a large thread pool, generally the number of CPU cores * 2
The utilization rate of IO intensive CPU is not high, which allows the CPU to process other tasks while waiting for IO and make full use of CPU time