Multi threading module of Py's journey to the West - Mr. Yuan - blog Park (cnblogs.com)
Threads and processes
What is a thread?
Thread is the smallest unit that the operating system can schedule operations. It is included in the process and is the actual operation unit in the process. A thread refers to a single sequential control flow in a process. Multiple threads can be concurrent in a process, and each thread executes different tasks in parallel
A thread is an execution context, which is all the information a CPU needs to execute a stream of instructions.
Suppose you're reading a book, and you want to take a break right now, but you want to be able to come back and resume reading from the exact point where you stopped. One way to achieve that is by jotting down the page number, line number, and word number. So your execution context for reading a book is these 3 numbers.
If you have a roommate, and she's using the same technique, she can take the book while you're not using it, and resume reading from where she stopped. Then you can take it back, and resume it from where you were.
Threads work in the same way. A CPU is giving you the illusion that it's doing multiple computations at the same time. It does that by spending a bit of time on each computation. It can do that because it has an execution context for each computation. Just like you can share a book with your friend, many tasks can share a CPU.
On a more technical level, an execution context (therefore a thread) consists of the values of the CPU's registers.
Last: threads are different from processes. A thread is a context of execution, while a process is a bunch of resources associated with a computation. A process can have one or many threads.
Clarification: the resources associated with a process include memory pages (all the threads in a process have the same view of the memory), file descriptors (e.g., open sockets), and security credentials (e.g., the ID of the user who started the process).
What is a process?
An executing instance of a program is called a process.
Each process provides the resources needed to execute a program. A process has a virtual address space, executable code, open handles to system objects, a security context, a unique process identifier, environment variables, a priority class, minimum and maximum working set sizes, and at least one thread of execution. Each process is started with a single thread, often called the primary thread, but can create additional threads from any of its threads.
What is the difference between process and thread?
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
Python GIL(Global Interpreter Lock)
CPython implementation detail: In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once (even though certain performance-oriented libraries might overcome this limitation). If you want your application to make better use of the computational resources of multi-core machines, you are advised to use multiprocessing. However, threading is still an appropriate model if you want to run multiple I/O-bound tasks simultaneously.
threading module
Two calling modes of one thread
Direct call
Example 1:

Inherited call:
II. Join & daemon
setDaemon(True):
Declaring a thread as a daemon must be set before the start() method call. If it is not set as a daemon, the program will be suspended indefinitely. This method is basically the opposite of join. When we are running a program, we execute a main thread. If the main thread creates another sub thread, the main thread and the sub thread will be divided into two ways and run separately. When the main thread finishes and wants to exit, we will check whether the sub thread is completed. If the child thread does not complete, it will wait for the child thread to exit. But sometimes what we need is to exit with the main thread as long as the main thread is completed, no matter whether the sub thread is completed or not. At this time, we can use the setDaemon method
join():
The parent thread of the child thread will be blocked until the child thread finishes running.
Other methods
Triple synchronous lock
import time
import threading
def addNum():
global num #Get this global variable in each thread
# num-=1
temp=num
print('--get num:',num )
#time.sleep(0.1)
num =temp-1 #- 1 operation on this public variable
num = 100 #Set a shared variable
thread_list = []
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #Wait for all threads to complete execution
t.join()
print('final num:', num )
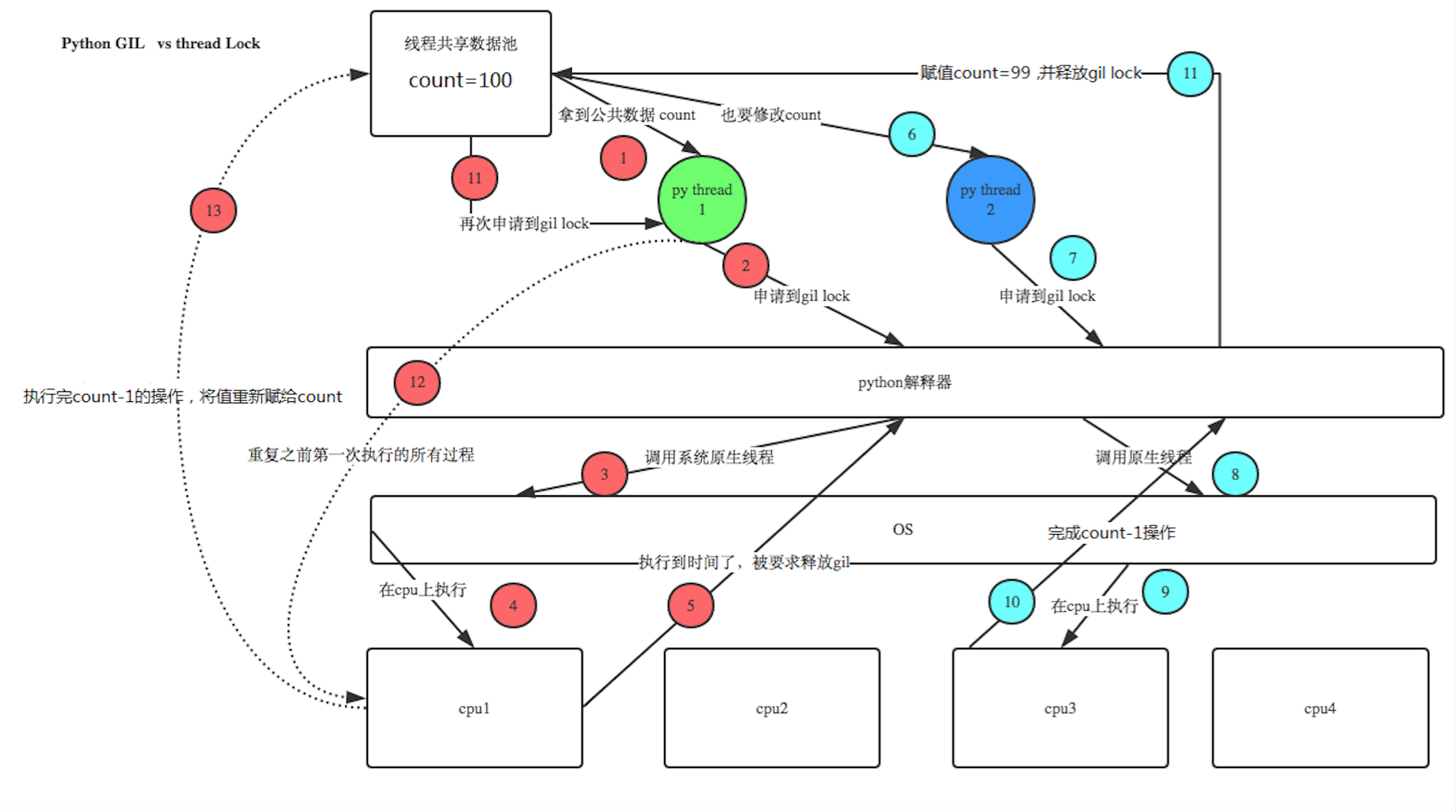
be careful:
1: why num-=1 no problem? This is because the action is too fast (the action is completed within the switching time)
2: if sleep(1), the phenomenon will be more obvious. Each of the 100 threads must be switched before they finish executing. As we said, sleep is equivalent to IO blocking and will not be switched back within 1s, so the final result must be 99
Multiple threads operate the same shared resource at the same time, which causes resource damage. What should we do?
Some students want to use join, but join will stop the whole thread, resulting in serialization and losing the meaning of multithreading. We only need to execute the calculation (involving the operation of public data) serially.
We can solve this problem through synchronization lock
import time
import threading
def addNum():
global num #Get this global variable in each thread
# num-=1
lock.acquire()
temp=num
print('--get num:',num )
#time.sleep(0.1)
num =temp-1 #- 1 operation on this public variable
lock.release()
num = 100 #Set a shared variable
thread_list = []
lock=threading.Lock()
for i in range(100):
t = threading.Thread(target=addNum)
t.start()
thread_list.append(t)
for t in thread_list: #Wait for all threads to complete execution
t.join()
print('final num:', num )
Problem solved, but
Excuse me: what is the relationship between synchronous lock and GIL?
Python threads are under the control of GIL. The access between threads to the whole Python interpreter and the C API provided by Python are mutually exclusive, which can be regarded as the mutual exclusion mechanism of Python kernel level. But this kind of mutual exclusion is beyond our control. We also need another controllable mutual exclusion mechanism - user level mutual exclusion. The kernel level protects the shared resources of the kernel through mutual exclusion. Similarly, the user level mutual exclusion protects the shared resources in the user program.
However, if you have an operation, such as x += 1, this operation requires multiple bytecodes operations. During the execution of multiple bytecodes of this operation, the thread may be changed halfway. In this way, the situation of data races occurs.
Four thread deadlock and recursive lock
When sharing multiple resources between threads, if two threads occupy part of the resources and wait for each other's resources at the same time, it will cause deadlock, because the system judges that these resources are in use, and all these two threads will wait without external force. Here is an example of Deadlock:
Solution: use recursive lock to
1 2 lockA=threading.Lock() lockB=threading.Lock()<br>#--------------<br>lock=threading.RLock()
In order to support multiple requests for the same resource in the same thread, python provides a "reentrant Lock": threading RLock. RLOCK internally maintains a Lock and a counter variable. The counter records the number of times to acquire, so that resources can be acquired multiple times. Until all acquires of one thread are release d, other threads can obtain resources.
application
V. condition variable synchronization
There are a kind of threads that need to meet the conditions before they can continue to execute. Python provides threading The condition object is used to support conditional variable threads. In addition to RLock() or Lock() methods, it also provides wait(), notify(), and notifyAll() methods.
lock_con=threading.Condition([Lock/Rlock]): lock is an optional option. It does not pass a human lock. The object automatically creates an RLock().
wait(): When the condition is not met, the thread will release the lock and enter the waiting block; notify(): Call after condition creation, notify waiting pool to activate a thread; notifyAll(): Call after condition creation, notify waiting pool to activate all threads.
example
Vi. synchronization condition (Event)
Conditional synchronization has almost the same meaning as conditional variable synchronization, but the lock function is missing, because conditional synchronization is designed in a conditional environment that does not access shared resources. event=threading.Event(): conditional environment object, the initial value is False;
event.isSet(): return event Status value of;
event.wait(): If event.isSet()==False Will block the thread;
event.set(): set up event The status value of is True,All threads in the blocking pool are activated to enter the ready state and wait for the scheduling of the operating system;
event.clear(): recovery event The status value of is False.
Example 1:
import threading,time
class Boss(threading.Thread):
def run(self):
print("BOSS: Everyone will work overtime until 22 tonight:00. ")
event.isSet() or event.set()
time.sleep(5)
print("BOSS: <22:00>You can get off work.")
event.isSet() or event.set()
class Worker(threading.Thread):
def run(self):
event.wait()
print("Worker: Alas... Life is hard!")
time.sleep(0.25)
event.clear()
event.wait()
print("Worker: OhYeah!")
if __name__=="__main__":
event=threading.Event()
threads=[]
for i in range(5):
threads.append(Worker())
threads.append(Boss())
for t in threads:
t.start()
for t in threads:
t.join()
Example 2:
import threading,time
import random
def light():
if not event.isSet():
event.set() #wait There is no obstruction #Green status
count = 0
while True:
if count < 10:
print('\033[42;1m--green light on---\033[0m')
elif count <13:
print('\033[43;1m--yellow light on---\033[0m')
elif count <20:
if event.isSet():
event.clear()
print('\033[41;1m--red light on---\033[0m')
else:
count = 0
event.set() #Turn on the green light
time.sleep(1)
count +=1
def car(n):
while 1:
time.sleep(random.randrange(10))
if event.isSet(): #green light
print("car [%s] is running.." % n)
else:
print("car [%s] is waiting for the red light.." %n)
if __name__ == '__main__':
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in range(3):
t = threading.Thread(target=car,args=(i,))
t.start()
Seven semaphores
Semaphores are used to control the number of concurrent threads. BoundedSemaphore or Semaphore manages a built-in counter, which is - 1 whenever acquire() is called and + 1 when release() is called.
The counter cannot be less than 0. When the counter is 0, acquire() will block the thread to the synchronous locking state until other threads call release(). (similar to the concept of parking space)
The only difference between BoundedSemaphore and Semaphore is that the former will check whether the value of the counter exceeds the initial value of the counter when calling release(). If so, an exception will be thrown.
example:
import threading,time
class myThread(threading.Thread):
def run(self):
if semaphore.acquire():
print(self.name)
time.sleep(5)
semaphore.release()
if __name__=="__main__":
semaphore=threading.Semaphore(5)
thrs=[]
for i in range(100):
thrs.append(myThread())
for t in thrs:
t.start()
Eight multithreading tools (queue)
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
Method of queue class
Create a queue object
import Queue
q = Queue.Queue(maxsize = 10)
Queue.Queue Class is the synchronous implementation of a queue. The queue length can be infinite or finite. Can pass Queue Optional arguments to the constructor of maxsize To set the queue length. If maxsize Less than 1 indicates that the queue length is infinite.Put a value in the queue
q.put(10)
Call queue object put()Method inserts an item at the end of the queue. put()There are two parameters, the first one item Required, the value of the inserted item; the second block It is an optional parameter. The default is
1. If the queue is currently empty and block Is 1, put()Method causes the calling thread to pause,Until a cell is empty. If block Is 0, put Method will raise Full Abnormal.Take a value from the queue
q.get()
Call queue object get()Method deletes and returns an item from the queue header. Optional parameters are block,Default to True. If the queue is empty and block by True,get()Pause the calling thread until an item is available. If the queue is empty and block by False,The queue will raise Empty Abnormal.Python Queue Modules have three types of queues and constructors:
1,Python Queue Modular FIFO Queue first in first out. class queue.Queue(maxsize)
2,LIFO Similar to heap, i.e. first in and last out. class queue.LifoQueue(maxsize)
3,Another is that the lower the priority queue level, the first out. class queue.PriorityQueue(maxsize)Common methods in this package(q = Queue.Queue()):
q.qsize() Returns the size of the queue
q.empty() If the queue is empty, return True,conversely False
q.full() If the queue is full, return True,conversely False
q.full And maxsize Size correspondence
q.get([block[, timeout]]) Get queue, timeout waiting time
q.get_nowait() Quite q.get(False)
Non blocking q.put(item) Write to queue, timeout waiting time
q.put_nowait(item) Quite q.put(item, False)
q.task_done() After completing a job, q.task_done() Function sends a signal to the queue where the task has been completed
q.join() In fact, it means waiting until the queue is empty before performing other operations
example
Example 1:
import threading,queue
from time import sleep
from random import randint
class Production(threading.Thread):
def run(self):
while True:
r=randint(0,100)
q.put(r)
print("Produced%s Steamed stuffed bun"%r)
sleep(1)
class Proces(threading.Thread):
def run(self):
while True:
re=q.get()
print("eat up%s Steamed stuffed bun"%re)
if __name__=="__main__":
q=queue.Queue(10)
threads=[Production(),Production(),Production(),Proces()]
for t in threads:
t.start()
Example 2:
import time,random
import queue,threading
q = queue.Queue()
def Producer(name):
count = 0
while count <20:
time.sleep(random.randrange(3))
q.put(count)
print('Producer %s has produced %s baozi..' %(name, count))
count +=1
def Consumer(name):
count = 0
while count <20:
time.sleep(random.randrange(4))
if not q.empty():
data = q.get()
print(data)
print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data))
else:
print("-----no baozi anymore----")
count +=1
p1 = threading.Thread(target=Producer, args=('A',))
c1 = threading.Thread(target=Consumer, args=('B',))
p1.start()
c1.start()
Example 3:
#Implement a thread to continuously generate a random number into a Queue (consider using the Queue module)
# Implement a thread to continuously take out odd numbers from the above queue
# Implement another thread to continuously take even numbers from the above queue
import random,threading,time
from queue import Queue
#Producer thread
class Producer(threading.Thread):
def __init__(self, t_name, queue):
threading.Thread.__init__(self,name=t_name)
self.data=queue
def run(self):
for i in range(10): #Randomly generate 10 numbers, which can be modified to any size
randomnum=random.randint(1,99)
print ("%s: %s is producing %d to the queue!" % (time.ctime(), self.getName(), randomnum))
self.data.put(randomnum) #Store the data in the queue in turn
time.sleep(1)
print ("%s: %s finished!" %(time.ctime(), self.getName()))
#Consumer thread
class Consumer_even(threading.Thread):
def __init__(self,t_name,queue):
threading.Thread.__init__(self,name=t_name)
self.data=queue
def run(self):
while 1:
try:
val_even = self.data.get(1,5) #Get (self, block = true, timeout = none), 1 is the blocking wait, and 5 is the timeout of 5 seconds
if val_even%2==0:
print ("%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(),self.getName(),val_even))
time.sleep(2)
else:
self.data.put(val_even)
time.sleep(2)
except: #Wait for input, and an exception will be reported if it exceeds 5 seconds
print ("%s: %s finished!" %(time.ctime(),self.getName()))
break
class Consumer_odd(threading.Thread):
def __init__(self,t_name,queue):
threading.Thread.__init__(self, name=t_name)
self.data=queue
def run(self):
while 1:
try:
val_odd = self.data.get(1,5)
if val_odd%2!=0:
print ("%s: %s is consuming. %d in the queue is consumed!" % (time.ctime(), self.getName(), val_odd))
time.sleep(2)
else:
self.data.put(val_odd)
time.sleep(2)
except:
print ("%s: %s finished!" % (time.ctime(), self.getName()))
break
#Main thread
def main():
queue = Queue()
producer = Producer('Pro.', queue)
consumer_even = Consumer_even('Con_even.', queue)
consumer_odd = Consumer_odd('Con_odd.',queue)
producer.start()
consumer_even.start()
consumer_odd.start()
producer.join()
consumer_even.join()
consumer_odd.join()
print ('All threads terminate!')
if __name__ == '__main__':
main()
Note: the list is thread unsafe
import threading,time
li=[1,2,3,4,5]
def pri():
while li:
a=li[-1]
print(a)
time.sleep(1)
try:
li.remove(a)
except:
print('----',a)
t1=threading.Thread(target=pri,args=())
t1.start()
t2=threading.Thread(target=pri,args=())
t2.start()
IX. context manager in Python (contextlib module)
The task of the context manager is to prepare before code block execution and clean up after code block execution
1. How to use the context manager:
How to open a file and write "hello world"
1 2 3 4 5 filename="my.txt" mode="w" f=open(filename,mode) f.write("hello world") f.close()
When an exception occurs (such as a disk full), there is no chance to execute line 5. Of course, we can use try finally statement blocks for packaging:
1 2 3 4 5 writer=open(filename,mode) try: writer.write("hello world") finally: writer.close()
When we rewrite the with statement, it becomes ugly:
1 2 with open(filename,mode) as writer: writer.write("hello world")
as refers to the content returned from the open() function and assigns it to a new value. with completed the task of try finally.
2. Custom context manager
The with statement is similar to try finally and provides a context mechanism. Two built-in functions must be provided inside the class to which the with statement is applied__ enter__ And__ exit__. The former is executed before the execution of the body code, and the latter is executed after the execution of the body code. The variable after as is in__ enter__ Function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class echo(): def output(self): print "hello world" def __enter__(self): print "enter" return self #You can return anything you want def __exit__(self,exception_type,value,trackback): print "exit" if exception_type==ValueError: return True else: return Flase >>>with echo as e: e.output() Output: enter hello world exit
Complete__ exit__ The functions are as follows:
1 def __exit__(self,exc_type,exc_value,exc_tb)
Where, exc_type: exception type; exc_value: abnormal value; exc_tb: exception tracking information
When__ exit__ When True is returned, the exception is not propagated
3. contextlib module
The function of the contextlib module is to provide a more easy-to-use context manager, which is implemented through the Generator. The contextmanager in contextlib serves as a decorator to provide a context management mechanism for function level. The common frameworks are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from contextlib import contextmanager @contextmanager def make_context(): print 'enter' try: yield "ok" except RuntimeError,err: print 'error',err finally: print 'exit' >>>with make_context() as value: print value Output is: enter ok exit
Among them, yield is written into try finally to ensure exception safety (can handle exceptions). The value of the variable after as is returned by yield. The statement before yield can be regarded as the operation before the code block is executed, and the operation after yield can be regarded as the operation after yield__ exit__ Operation in function.
Take thread lock as an example:
@contextlib.contextmanager
def loudLock():
print 'Locking'
lock.acquire()
yield
print 'Releasing'
lock.release()
with loudLock():
print 'Lock is locked: %s' % lock.locked()
print 'Doing something that needs locking'
#Output:
#Locking
#Lock is locked: True
#Doing something that needs locking
#Releasing
4,contextlib.nested: reduce nesting
For:
1 2 3 with open(filename,mode) as reader: with open(filename1,mode1) as writer: writer.write(reader.read())
You can use contextlib Simplified by nested:
1 2 with contextlib.nested(open(filename,mode),open(filename1,mode1)) as (reader,writer): writer.write(reader.read())
In python 2.7 and later, it was replaced by a new syntax:
1 2 with open(filename,mode) as reader,open(filename1,mode1) as writer: writer.write(reader.read())
5,contextlib.closing()
The file class directly supports the context manager API, but some objects that represent open handles do not, such as urllib Object returned by urlopen(). There are also legacy classes that use the close() method without supporting the context manager API. To ensure that the handle is closed, you need to use closing() to create a context manager for it (calling the close method of the class).
X. custom thread pool
Simple version:
import queue
import threading
import time
class ThreadPool(object):
def __init__(self, max_num=20):
self.queue = queue.Queue(max_num)
for i in range(max_num):
self.queue.put(threading.Thread)
def get_thread(self):
return self.queue.get()
def add_thread(self):
self.queue.put(threading.Thread)
'''
pool = ThreadPool(10)
def func(arg, p):
print(arg)
time.sleep(1)
p.add_thread()
for i in range(30):
Pool = pool.get_thread()
t = Pool(target=func, args=(i, pool))
t.start()
'''
Complex version:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import queue
import threading
import contextlib
import time
StopEvent = object()
class ThreadPool(object):
def __init__(self, max_num, max_task_num = None):
if max_task_num:
self.q = queue.Queue(max_task_num)
else:
self.q = queue.Queue()
self.max_num = max_num
self.cancel = False
self.terminal = False
self.generate_list = []
self.free_list = []
def run(self, func, args, callback=None):
"""
The thread pool performs a task
:param func: Task function
:param args: Required parameters of task function
:param callback: The callback function to be executed after the task fails or succeeds. The callback function has two parameters: 1. The execution status of the task function; 2. Return value of task function (default is None,(i.e. do not execute callback function)
:return: Returns if the thread pool has terminated True otherwise None
"""
if self.cancel:
return
if len(self.free_list) == 0 and len(self.generate_list) < self.max_num:
self.generate_thread()
w = (func, args, callback,)#Main thread
self.q.put(w)#Main thread
def generate_thread(self):
"""
Create a thread
"""
t = threading.Thread(target=self.call)
t.start()
def call(self):
"""
Loop to get the task function and execute the task function
"""
current_thread = threading.currentThread()
self.generate_list.append(current_thread)
event = self.q.get()#if q is empty, block it until a task comes in and takes it out
while event != StopEvent:
func, arguments, callback = event
try:
result = func(*arguments)
success = True
except Exception as e:
success = False
result = None
if callback is not None:
try:
callback(success, result)
except Exception as e:
pass
with self.worker_state(self.free_list, current_thread):
if self.terminal:
event = StopEvent
else:
event = self.q.get()#key: the thread continues to wait for a new task here. When the task comes, continue to execute
#Temporarily put the thread object into free_list.
else:
self.generate_list.remove(current_thread)
def close(self):
"""
After performing all tasks, all threads stop
"""
self.cancel = True
full_size = len(self.generate_list)
while full_size:
self.q.put(StopEvent)
full_size -= 1
def terminate(self):
"""
Terminate the thread whether there are tasks or not
"""
self.terminal = True
while self.generate_list:
self.q.put(StopEvent)
self.q.queue.clear()
@contextlib.contextmanager
def worker_state(self, free_list, worker_thread):
"""
Used to record the number of waiting threads in a thread
"""
free_list.append(worker_thread)#Judge when a new task comes
# if len(self.free_list) == 0 and len(self.generate_list) < self.max_num
# The task has to create a new thread to process; If len(self.free_list)= 0: blocked existence free_ Thread processing in list (event = self.q.get())
try:
yield
finally:
free_list.remove(worker_thread)
# How to use
pool = ThreadPool(5)
def callback(status, result):
# status, execute action status
# result, execute action return value
pass
def action(i):
time.sleep(1)
print(i)
for i in range(30):
ret = pool.run(action, (i,), callback)
time.sleep(2)
print(len(pool.generate_list), len(pool.free_list))
print(len(pool.generate_list), len(pool.free_list))
# pool.close()
# pool.terminate()
Extension:
import contextlib
import socket
@contextlib.contextmanager
def context_socket(host,port):
sk=socket.socket()
sk.bind((host,port))
sk.listen(5)
try:
yield sk
finally:sk.close()
with context_socket('127.0.0.1',8888) as socket:
print(socket)