What is a hash table?
Hash tables, also known as hash tables, are array based. This indirectly brings an advantage: the time complexity of search is O(1), and of course, its insertion time complexity is also O(1). There is also a disadvantage: the expansion cost is high after the array is created.
There is a "mainstream" idea in hash tables: transformation. An important concept is to convert "key" or "keyword" into array subscript. This is done by the hash function.
What is a hash function?
From the above, its function is to convert non int keys / keywords into int values, so that they can be used as array subscripts.
For example, HashMap implements the hash function in this way:
static final int hash(Object key){
int h;
return (key==null)?0:(h=key.hashCode())^(h>>>16); // Increase the hash degree of hash through XOR to reduce conflicts
}
hashCode is used to complete the conversion. Although there are many implementations of hash functions, they should meet these three points:
- The calculated result is a nonnegative integer;
- If key1==key2, then hash(key1)==hash(key2);
- If key1= Key2, then hash (key1)= hash(key2);
- Not all keys / keywords need to be converted to be subscript (index)
- Just like JS, there are similar methods that are only used to detect whether keys can be used as array subscripts: Data type problem in JavaScript array index detection
What is hash conflict?
The hashMap mentioned above -- a data set provided in java. Let's first understand: first, hashMap is essentially a container. In order to achieve the purpose of fast index, it uses the "fast positioning" feature of array structure.
In order to find the inserted value faster in hashMap, the relationship between the inserted value and the array subscript is established: POS (subscript) = key (value)% size (array size).
For example, the length of the array is 10
- Insert 100, with 100% 10 = 0;
- Insert 201, 201% 10 = 1;
- Insert 403, with 403% 10 = 3;
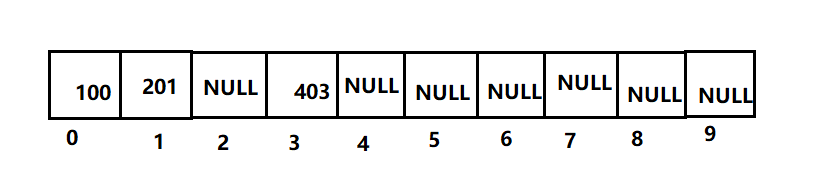
But if it is designed like this, what will happen if I insert another 200 now?
This is one of the disadvantages of arrays: inserting special values is "laborious". Let's simply refer to the array as follows:
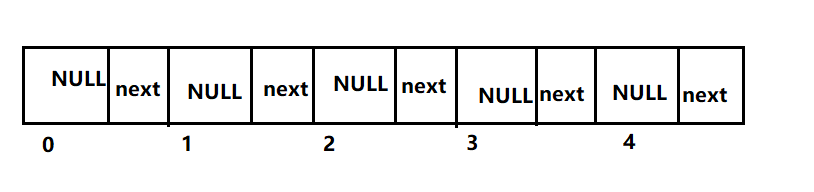
The linked list feature is introduced. A node includes a value and a next pointer.
Now insert the above values, and it becomes like this:
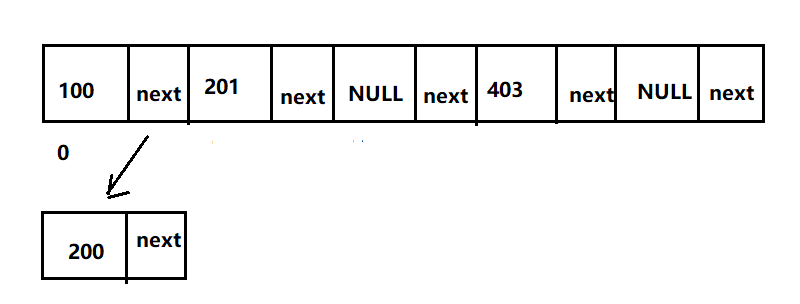
At this time, if the value 300 is inserted, what should I do?
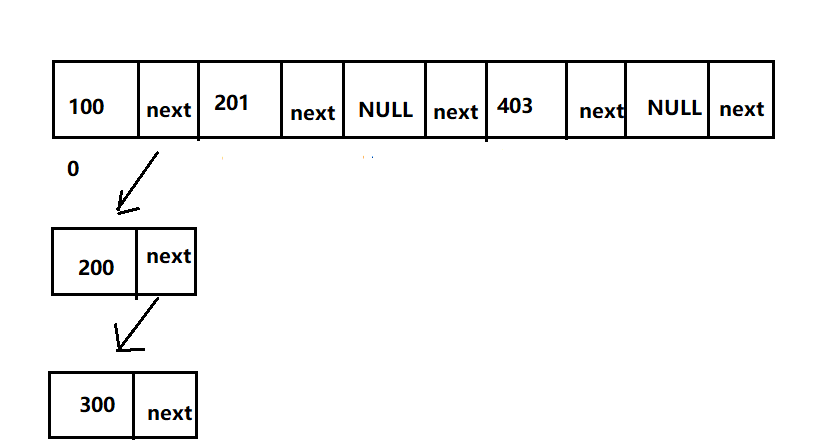
Similar to this (when two or more keys have the same pos and different keys) is actually the "hash conflict" we mentioned, and the method to solve hash conflict in hashMap is the above-mentioned "single linked list"!
But there is another problem: Although using an ordered linked list can reduce the unsuccessful search time (as long as one item is larger than the search value, it means that there is no value we need to find), it can not speed up the successful search. If the conflicting linked list is too long, the disadvantage of traversing from the "head" when searching the linked list will be exposed - for this problem, jdk1 After 8, it was optimized with red black tree!
But let's put aside the red black tree and explain the operation of hash table in the form of single linked list:
/**
* Linked list base class: the linked list method uses an ordered linked list to solve hash conflicts!
*/
public class SortedLinkList {
private Link first;
public SortedLinkList(){
first = null;
}
/**
* Insert linked list
* @param link
*/
public void insert(Link link){
int key = link.getKey();
Link previous = null;
Link current = first;
while (current!=null && key >current.getKey()){
previous = current;
current = current.next;
}
if (previous == null)
first = link;
else
previous.next = link;
link.next = current;
}
/**
* Linked list deletion
* @param key
*/
public void delete(int key){
Link previous = null;
Link current = first;
while (current !=null && key !=current.getKey()){
previous = current;
current = current.next;
}
if (previous == null)
first = first.next;
else
previous.next = current.next;
}
/**
* Linked list lookup
* @param key
* @return
*/
public Link find(int key){
Link current = first;
while (current !=null && current.getKey() <=key){
if (current.getKey() == key){
return current;
}
current = current.next;
}
return null;
}
}
Linked hash table insertion:
public void insert(int data) {
Link link = new Link(data);
int key = link.getKey();
int hashVal = hash(key);
array[hashVal].insert(link);
}
Linked hash table lookup:
public Link find(int key) {
int hashVal = hash(key);
return array[hashVal].find(key);
}
Linked list hash table deletion:
public void delete(int key) {
int hashVal = hash(key);
array[hashVal].delete(key);
}
In addition to the linked list method, there is another method to solve hash conflict: open addressing method.
In the open address method, if the data cannot be directly stored in the array subscript calculated by the hash function, you need to find another location to store it. In the open address method, there are three ways to find other locations, namely
- Linear detection
- Secondary detection
- double hashing