Tide information analysis
(1) Climb cninfo Vanke A website to download pdf
(2) Filter specified fields from pdf
(3) Visual analysis using python
preface
Bloggers need to crawl the pdf of the annual report of the specified company in the tide information, download it, filter the specified fields of the pdf, and then conduct visual analysis
In view of the budget problem, several basic charts are used for visual analysis, such as scatter chart
Line chart and histogram
1, First, analyze the tide information web page
The struggle between crawler and anti crawler is all the time. I met two people when I did the anti crawler mechanism of this web page
1. The url of the web page does not change when turning the page
Observe that the url of these two images has not changed
Through this analysis, we can use two methods. One is to obtain the web page source code by using the post request
The second is to use python's selenium library for analysis
2. Every time the web page is refreshed, the data will not be refreshed immediately
Today, bloggers use the second method. If there are too many methods, they won't explain them one by one
(1) . functional preparation
1. Import and storage
The code is as follows (example):
import re import time import requests from selenium import webdriver from selenium.webdriver.common.by import By
If selenium is used, you need to install the driver of the corresponding browser on your computer. In addition to the library provided by the system, you need to use pip install to install it
2. The code is as follows:
The code is as follows (example):
list = []
def page_turn():
url = 'http://www.cninfo.com.cn/new/disclosure/stock?orgId=gssz0000002&stockCode=000002#latestAnnouncement'
browser.get(url)
time.sleep(1)
browser.find_element(By.XPATH,'//*[@id="main"]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[1]/form/div[2]/div/span/button').click()
browser.find_element(By.CLASS_NAME, 'cate-checkbox-txt').click()
browser.find_element(By.XPATH,'//*[@id="main"]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[4]/div/div/button[2]').click()
time.sleep(1)
data = browser.page_source
print("Perform page turning operation")
return data
# if page_next =
def search(data):
# Get web page source code
# Get page title
p_title = '<span class="r-title">(.*?)</span>'
title = re.findall(p_title, data)
# Get web address
p_href = '<div class="cell"><a target="_blank" href="(.*?)" data-id='
href = re.findall(p_href, data)
for index in range(len(href)):
# URL cleanup
href[index] = 'http://www.cninfo.com.cn' + href[index]
href[index] = re.sub('amp;', '', href[index])
# pdf file download
res = requests.get(url=href[index])
path = "Inquiry letter//" + title[index] + ".pdf"
# print(path)
print(href[index])
list.append(href[index])
try:
for i in list:
browser.get(i)
browser.find_element(By.XPATH,'//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button').click()
print("The first" + str(index + 1) + "File No. crawls successfully!")
except:
print("no pdf edition")
def main():
url = 'http://www.cninfo.com.cn/new/disclosure/stock?orgId=gssz0000002&stockCode=000002#latestAnnouncement'
browser.get(url)
time.sleep(1)
browser.find_element(By.XPATH,'//*[@id="main"]/div[3]/div/div[2]/div/div/div[2]/div[1]/div[1]/form/div[2]/div/span/button').click()
browser.find_element(By.CLASS_NAME,'cate-checkbox-txt').click()
time.sleep(1)
data = browser.page_source
return data
if __name__ == "__main__":
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
#Set download path
prefs = {'profile.default_content_settings.popups': 0 ,'download.default_directory':r'c:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf'}
chrome_options.add_experimental_option('prefs',prefs)
browser = webdriver.Chrome(options=chrome_options)
main()
search(main())
page_turn()
search(page_turn())
Here, we use selenium for pdf download
2, Filter the specified field and write it into csv
Import and warehousing
import pdfplumber import os import csv
The code is as follows
import pdfplumber
import os
import csv
def parase_pdf(table_keyword,inside_keyword,outside_keyword):
#global variable
global pdffile_list
global parase_out_writer
global parase_out
global OUT_DIR
global file_names
while True:
#rLock2.acquire()
if len(file_names):
print('--------{}---------'.format(len(file_names)))
file_name=file_names[0]
file_names.remove(file_name)
if file_name.endswith('.PDF') or file_name.endswith('.pdf'):
path =os.path.join(OUT_DIR,file_name)
print('get pdf address')
try:
pdf = pdfplumber.open(path,password='')
except:
print("*************open pdf error*******************")
print("*************open pdf*******************")
find_table=0
find_pre_table=0
find_keyword=0
find_keyword_outside=0
name_find=[]
value_find=[]
page_find=[]
#for page in pdf.pages:
#print(page.extract_text())
begin_index=int(len(pdf.pages)/2)
for i in range(begin_index,len(pdf.pages)):
if find_table:
find_pre_table=1
else:
find_pre_table=0
find_table=0
page=pdf.pages[i]
#print(page.extract_text())
data=page.extract_text()
if len(table_keyword):
for keyword in table_keyword:
if keyword in data:
find_table=1
else:
find_table=0
break
else:
find_table=1
if find_table or find_pre_table:
data_list=data.strip().split()
for j in range(len(data_list)):
if len(inside_keyword):
for keyword in inside_keyword:
if keyword in data_list[j]:
find_keyword=1
else:
find_keyword=1
if find_keyword:
find_keyword=0
print('run here')
if len(outside_keyword):
for keyword in outside_keyword:
if keyword not in data_list[j]:
find_keyword_outside=1
else:
find_keyword_outside=0
break
else:
find_keyword_outside=1
if find_keyword_outside:
find_keyword_outside=0
try:
temp_value=data_list[j+1]
temp_value=temp_value.replace(',','')
temp_value=float(temp_value)
name_find.append(data_list[j])
value_find.append(temp_value)
page_find.append(i)
try:
parase_out_writer.writerows([[file_name,data_list[j],str(temp_value),data_list[j+1],str(i)]])
except:
pass
parase_out.flush()
print("*****find******{} value is {} and {}".format(data_list[j],data_list[j+1],temp_value))
print("*************find in page {}*******************".format(i))
print("*************find in {}*******************".format(path))
break # only find one result
except:
continue
pdf.close()
# os.remove(path) # pdf. Delete the file after close, otherwise there are too many files
print('****time to processing PDF file is ')
else:
path =os.path.join(OUT_DIR,file_name)
# os.remove(path)
return name_find,value_find,page_find # Be sure not to return put to while Inside, meet return It will end immediately #str(time.strftime('%Y-%m-%d'))
OUT_DIR = r'Notice pdf'
table_keyword=['Income statement']
inside_keyword=['business income']
outside_keyword=['received']
# , 'operating profit', 'asset liability ratio'
file_names=os.listdir(OUT_DIR)
parase_out_file_path=OUT_DIR+'/parase_out_file2.csv'
parase_out=open(parase_out_file_path, 'w', newline='', encoding='utf-8')
parase_out_writer = csv.writer(parase_out)
parase_pdf(table_keyword,inside_keyword,outside_keyword)
import pdfplumber
import os
import csv
inside_keyword = 'Asset liability ratio'
def parase_pdf(inside_keyword):
global pdffile_list
global parase_out_writer
global parase_out
global OUT_DIR
global file_names
while True:
# rLock2.acquire()
if len(file_names):
print('--------{}---------'.format(len(file_names)))
file_name = file_names[0]
file_names.remove(file_name)
if file_name.endswith('.PDF') or file_name.endswith('.pdf'):
path = os.path.join(OUT_DIR, file_name)
print('get pdf address')
try:
pdf = pdfplumber.open(path,password='')
except:
print("*************open pdf error*******************")
print("*************open pdf*******************")
for page in pdf.pages:
data = page.extract_text()
if inside_keyword in page.extract_text():
# print(page.extract_text())
data_list = data.strip().split()
for j in range(len(data_list)):
if inside_keyword in data_list[j]:
# print(data_list)
print('extract'+f'{inside_keyword}'+'in')
if len(data_list[j])<7:
print(data_list[j],data_list[j+1])
# print(len(data_list[j]))
try:
parase_out_writer.writerows([[file_name, data_list[j],data_list[j + 1]]])
except:
pass
parase_out.flush()
# print(dict(data_list))
OUT_DIR = r'Notice pdf'
file_names=os.listdir(OUT_DIR)
parase_out_file_path=OUT_DIR+'/parase_out_file5.csv'
parase_out=open(parase_out_file_path, 'w', newline='', encoding='utf-8')
parase_out_writer = csv.writer(parase_out)
parase_pdf(inside_keyword)
summary
Tip: here is a summary of pdf content extraction:
Because the asset liability ratio mainly extracted by Bo is a percentage, which is different from the operating revenue and operating profit, after the two are extracted separately, if they need to be applied, change the path to your own file path
3, Visual analysis of data in csv
(1)
The data we extracted from pdf is still irregular. What should we do at this time
You have to clean and organize the data
Direct code
First step
import pandas as pd import re df = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv'),header=None,names=['id','earning','number1','number2']Add header
Step 2
df['year'] = df['name'].apply(lambda x: re.findall(r'\d{4}',x)[0])#New year column
df.to_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv',index=False)
df
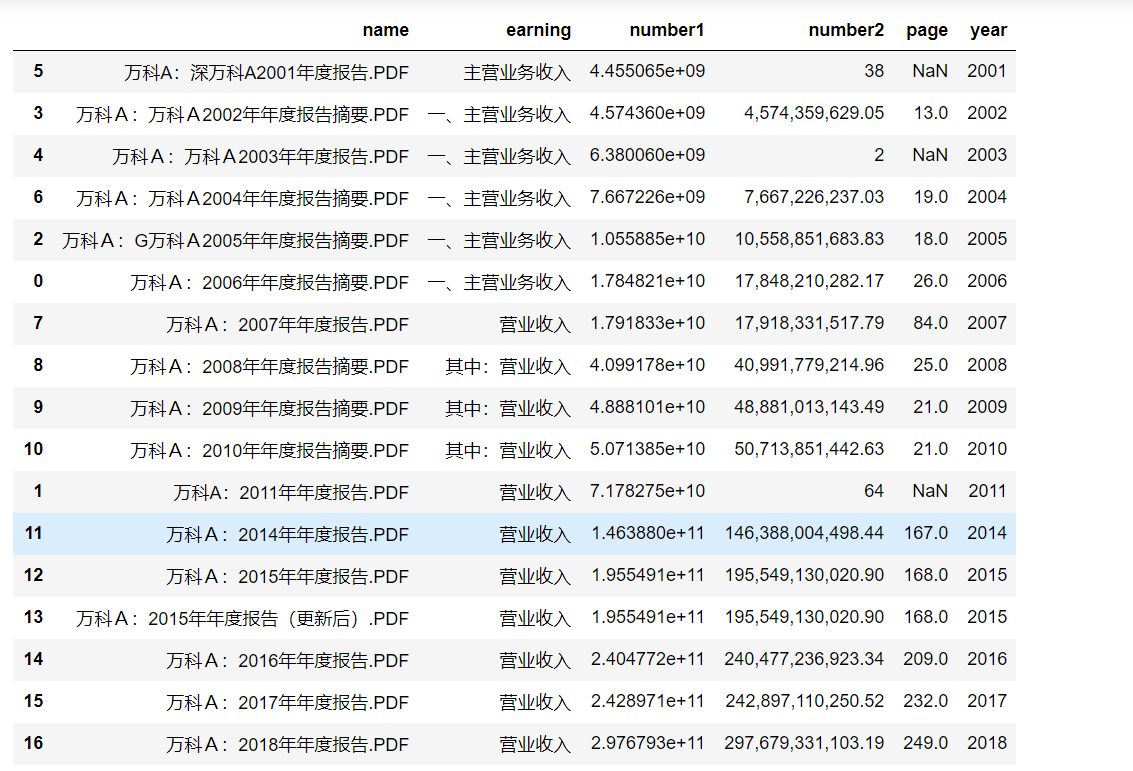
Does this look much more comfortable? Bloggers visually check one for obsessive-compulsive disorder
df = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv')
# df.to_csv(r'C:\Users252\PycharmProjects\pythonProject \ cninfo \ announcement pdf\parase_out_file2.csv',index=False)
df.sort_values("year",ascending=True,inplace=True)#Sort by year
df.to_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv',index=False)
df1 = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file3.csv')
df1.sort_values("year",ascending=True,inplace=True)#Sort by year
df1.to_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file3.csv',index=False)
df1
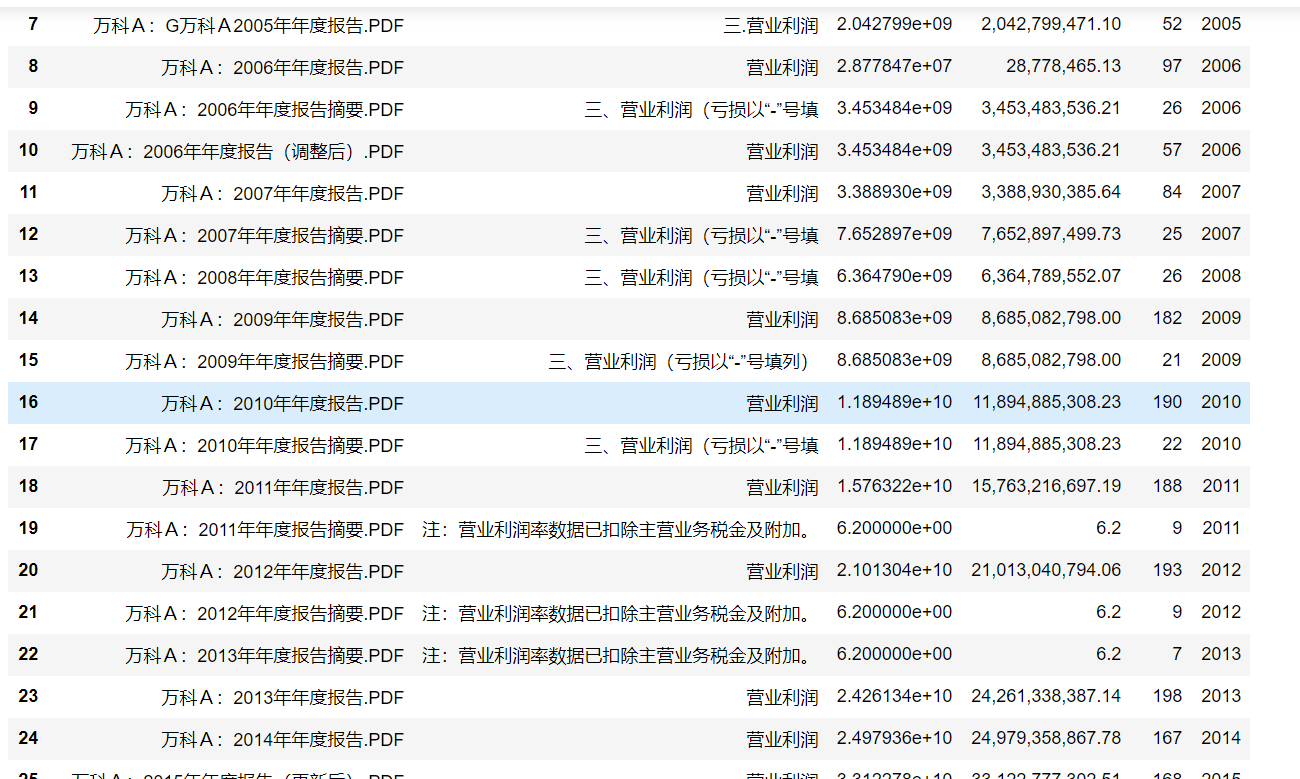
df3 = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file4.csv')
# df3.to_csv(r'C:\Users252\PycharmProjects\pythonProject \ cninfo \ announcement pdf\parase_out_file4.csv',index=False) save
df3['year'] = df3['name'].apply(lambda x: re.findall(r'\d{4}',x)[-1])#Extraction year
df3.sort_values("year",ascending=True,inplace=True)#Sort by year
df3.to_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file4.csv',index=False)
df3
df3.drop_duplicates('data',keep='first',inplace=True)
df3.to_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file4.csv',index=False)
df3 #This principle applies to all three tables
Although these data are not much, they feel a little messy. They need to be sorted and redone, and rows and columns need to be added
(2)
In the second step, we need to start drawing the chart
Introduce the library we need
import matplotlib import pandas as pd import matplotlib.pyplot as plt from matplotlib.pyplot import MultipleLocator
Because every data is a principle, bloggers will not give examples one by one
Drawing of line chart
df = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv') plt.figure(figsize=(16,6)) ax=plt.gca() x_major_locator=MultipleLocator(1)#Set interval ax.xaxis.set_major_locator(x_major_locator) plt.plot(df['year'],df['number1'],color='#A0522D',marker='o',label = "operating revenue", linewidth=2,linestyle = "--")
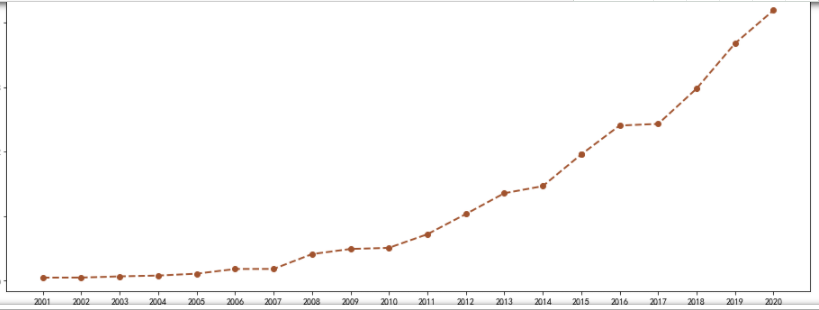
Drawing of scatter diagram
Introduce the library we need
import matplotlib import pandas as pd import matplotlib.pyplot as plt from matplotlib.pyplot import MultipleLocator
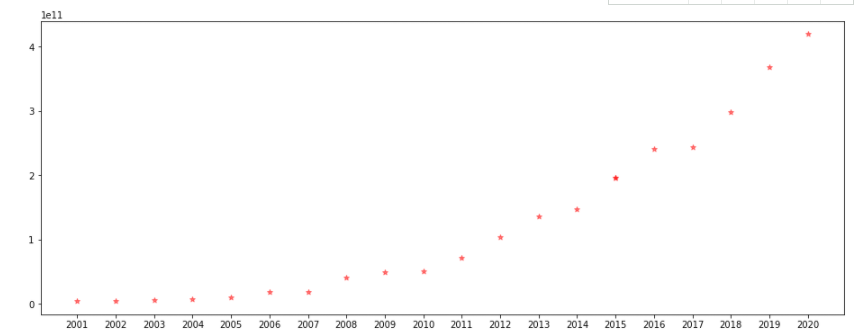
df = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv') plt.figure(figsize=(16,6)) x=df['year'] y=df['number1'] ax=plt.gca() x_major_locator=MultipleLocator(1) ax.xaxis.set_major_locator(x_major_locator) plt.scatter(x,y,alpha=0.5,marker='*',c='r',label="Pentagonal")
design sketch
Drawing of histogram
Import and warehousing
import pandas as pd import matplotlib.pyplot as plt from numpy import arange from matplotlib.font_manager import FontProperties
plt.style.use('fivethirtyeight')
df = pd.read_csv(r'C:\Users\13252\PycharmProjects\pythonProject\Tide information\Notice pdf\parase_out_file2.csv')
# df
date = df['year']
data=df['number1']
plt.bar(date,data,width=0.5,alpha=0.5)
plt.title("Main business income and operating income",fontproperties=font_set)
Drawing of histogram
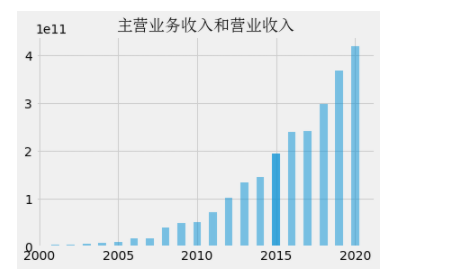
summary
For each chart, I only wrote a chart drawn with csv data, and the rest just need to draw a gourd according to the gourd
Some parts of Mengxin's code may not be marked or written. I hope you can point out more
If you have any questions, you can talk to me in private. You are welcome to make more corrections