
Author Zhao Luyang
In 2016, Chen Tianqi's team proposed "gradient/activation checkpointing" and other technologies related to sub linear memory optimization [1], aiming to reduce the memory occupation caused by intermediate activation in the process of deep learning and training. Checkpointing technology is a kind of sub linear memory optimization. In addition, there are technologies such as CPU offload (CPU offload is widely used in Microsoft Deepspeed framework).
CPU offload switches the temporarily unused GPU memory into the CPU memory for storage and then takes it out when necessary. The main overhead comes from the copy between the CPU and GPU, which will occupy the transmission bandwidth (PCIE bandwidth), which belongs to the exchange of transmission for space. The core of Checkpointing is to trade time for space: implement Inplace operation and Memory sharing optimization through computational graph analysis technology, delete some temporarily unused intermediate activation features in the forward process of each mini batch to reduce memory occupation, and recover them with additional forward calculation when needed in the backward process.
In OneFlow, the implementation of Checkpointing is mainly through static memory reuse. After the life cycle of forward Tensor ends, other tensors can reuse this memory, so as to achieve the effect of memory reuse and memory saving.OneFlow currently supports "gradient/activation checkpointing" to realize sub linear memory optimization, and is very friendly to algorithm developers. The use method is very simple: for the network part to be optimized, wrap it in the scope of "Checkpointing" with a line of code, The system will analyze the network in this scope area and automatically optimize the Checkpointing memory during the training process.
The main contents of this paper are as follows:
-
1. Usage of sub linear memory optimization
-
2. Design of sub linear memory optimization
-
3. Code interpretation
Including: 1 This section will introduce how to start trial sub linear memory optimization in OneFlow; 2. It will introduce how OneFlow Central Asia linear memory optimization is designed and its principle; 3. The specific implementation process will be analyzed from the code.
1
Usage of sublinear memory optimization
The way to enable sub linear memory optimization in OneFlow is as follows:
# Usage:
with flow.experimental.scope.config(checkpointing=True):
# your net work, such as :
# input layernorm
norm1 = layernorm("layernorm_1", h)
# attention
h = h + self.attn(norm1)
# output layernorm
norm2 = layernorm("layernorm_2", h)
# mlp
h = h + self.mlp(norm2)After wrapping with the above code, the network in this scope area will only save one memory of input tensor in the whole forward process. From input to the final output h, the memory of all intermediate features tensor will not be saved. The backward process will recalculate (forward) from input when necessary.
We have conducted a video memory occupancy test of turning on / off checkpointing on multiple networks. Taking GPT-2 as an example, we use the checkpointing = True scope mark to recalculate the part in each Transformer Layer.
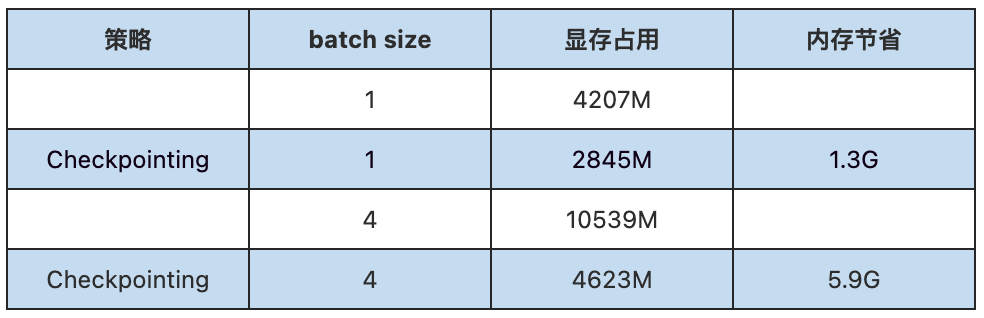
When GPT + - batch size = 4, you can see that the memory consumption will be greatly reduced when GPT + - batch is turned on.
2
Design of sub linear memory optimization
In the series "deep analysis: let you master the system design of OneFlow framework"( Part I,novelette,Part II )>In, we introduced the opnode / opgray abstraction in OneFlow and the Actor, SBP abstraction and other system designs based on it. It is these good system designs and abstractions that make OneFlow perform well in a variety of tasks.
The Job task of OneFlow will carry out a series of pass system optimization processes based on the Job logic diagram (opgray) composed of opnodes during logic diagram compilation. Each pass modifies / rewrites the logic diagram once (adds and deletes the nodes and edges in the logic diagram). These optimizations are very important to the improvement of performance.
The implementation of Activation Checkpointing in OneFlow is also realized by modifying / rewriting the Job logic diagram through a checkpoint pass (see https://github.com/Oneflow-Inc/oneflow/pull/3976 ).
 Main principle
Main principle
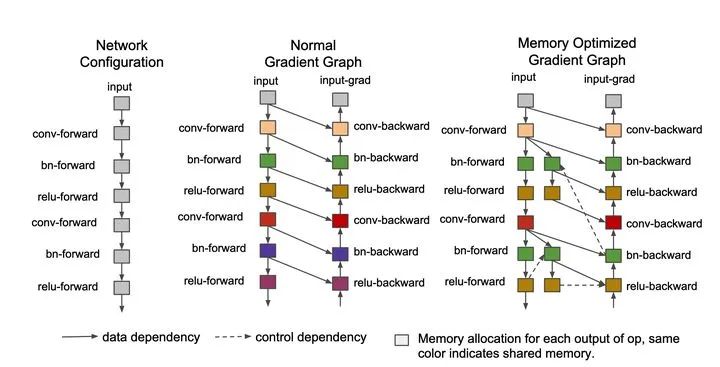
As shown in the figure:
1. The upper part is the logic sub diagram under normal conditions. T1 and T2 are the forward calculation part of the Transformer Layer. The intermediate activation features obtained after each op calculation in the subgraph will continue to occupy memory. When the calculation is in the reverse direction (T1_grad and T2_grad), these intermediate activation will be used for reverse calculation;
2. The lower part is the logic sub diagram after Activation Checkpointing is enabled. It can be seen that a dotted line is added in the middle part to frame the fake subgraph for recalculation. Due to the existence of the fake subgraph, there is no need to save the middle activation when the normal forward subgraph is in the forward direction. When the backward calculation needs to be used, the forward recalculation is temporarily carried out according to the fake subgraph.
In OneFlow, the detailed process of Activation Checkpointing is as follows:
1. Collect all ops under forward pass under the package of the checkpointing scope
2. Collect all subgraphs under ops
3. Traverse the subgraphs and do the following for all subgraphs that need to be backward:
-
Generate a fake subgraph and use it as input to the backward consumer (not the real subgraph)
-
Add the control edge from end op to all source nodes in the make subgraph
-
Add the fake subgraph to the job builder (managed by it)
4. Update all backward consumer ops in job builder
Code implementation:
https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job/checkpointing_config_def.cpp https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job/job_build_and_infer_ctx.cpp#L989 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/checkpointing_pass.cpp
3
Code interpretation
3.1 collect all ops under forward pass
Because the design of activation checkpointing is mainly to save the memory in the forward calculation process, that is, within the scope of checkpointing, release the activation video memory generated by op nodes in the forward calculation process. When backward, redo the forward calculation of this part to obtain the required activation.
Since all our operations are at the logic diagram level and the object of operation is each op node node, we need to mark and filter out all forward op nodes within the scope of checkpointing. This part is mainly implemented through the CollectAllCheckpointingOpsInForwardPass() method:
https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/checkpointing_pass.cpp#L65
void CollectAllCheckpointingOpsInForwardPass(
// Collect all qualified op nodes under forward pass and store them in HashMap
const OpGraph& op_graph, HashMap<std::string, const OpNode*>* checkpointing_op_name2op_node) {
// NOTE(chengcheng):
// ignore batch_norm ops because of recompute bn will repeat the calculation of 'm' and 'v'.
// in the future, we need to support the recomputation version of batch_norm which do NOT
// update forward variables.
HashSet<std::string> ignore_op_type_names = {"normalization", "normalization_add_relu",
"cudnn_fused_normalization_add_relu"};
op_graph.ForEachNode([&](const OpNode* op_node) {
const OperatorConf& op_conf = op_node->op().op_conf();
// Skip without user_conf and ignore_ op_ type_ OP specified by names_ node
if (!op_conf.has_user_conf()) { return; }
if (ignore_op_type_names.find(op_conf.user_conf().op_type_name())
!= ignore_op_type_names.end()) {
return;
}
// For op with checkpointing enabled and marked ForwardPass within the scope_ Node, it is the target node, which is inserted into the HashMap
if (IsForwardPass7CheckpointingScope(Scope4OpNode(op_node))) {
CHECK(checkpointing_op_name2op_node->emplace(op_conf.name(), op_node).second);
}
});
}The method IsForwardPass7CheckpointingScope() is mainly used to filter the qualified OP nodes:
bool IsForwardPassScope(const Scope& scope) {
// In scope, calculation_ pass_ If the name attribute is the node of kForwardPass, it is the target node participating in the forward calculation
return scope.scope_proto().calculation_pass_name() == kForwardPass;
}
bool IsForwardPass7CheckpointingScope(const Scope& scope) {
// True if attribute is node of kForwardPass and scope has enabled checkpointing
return IsForwardPassScope(scope) && scope.Bool("checkpointing");
}IsForwardPass7CheckpointingScope() method judges whether the op node belongs to the node directly participating in the forward calculation through the scope of the node (kForwardPass is included in the scope), and whether "checkpointing" is enabled. If it is satisfied at the same time, it is the target node, which is inserted into hashmap(checkpointing_op_name2op_node).
3.2 collect all subgraphs under ops
After filtering out all op nodes in the checkpointing action area, all subgraphs need to be generated according to these nodes. Some of these subgraphs are independent of backward recalculation and some are target subgraphs required by backward recalculation. Their output is consumed as the input of backward op nodes, These subgraphs are the smallest units of forward recalculation in the design of activation checkpointing.
The code for generating the subgraph is as follows:
// Generate all subgraphs subgraphs according to ops and store them in vector // step 2. get all connected subgraphs in checkpointing ops. std::vector<HashSet<const OpNode*>> checkpointing_subgraphs; GenConnectedCheckpointingSubgraphs(checkpointing_op_name2op_node, &checkpointing_subgraphs);
Among them, subgraphs are generated mainly through the GenConnectedCheckpointingSubgraphs() method:
void GenConnectedCheckpointingSubgraphs(
// Generate Subgraphs subgraphs
const HashMap<std::string, const OpNode*>& checkpointing_op_name2op_node,
std::vector<HashSet<const OpNode*>>* checkpointing_subgraphs) {
HashSet<const OpNode*> visited_nodes;
for (const auto& pair : checkpointing_op_name2op_node) {
const OpNode* node = pair.second;
if (visited_nodes.find(node) != visited_nodes.end()) { continue; }
// new subgraph
checkpointing_subgraphs->push_back(HashSet<const OpNode*>());
CHECK(!checkpointing_subgraphs->empty());
auto& subgraph = checkpointing_subgraphs->back();
CHECK(subgraph.empty());
// bfs search all node in checkpointing ops
CHECK(visited_nodes.insert(node).second);
std::queue<const OpNode*> queued_nodes;
queued_nodes.push(node);
while (!queued_nodes.empty()) {
const OpNode* cur_node = queued_nodes.front();
queued_nodes.pop();
CHECK(subgraph.insert(cur_node).second);
cur_node->ForEachNodeOnInOutEdge([&](const OpNode* next_node) {
const std::string& next_op_name = next_node->op().op_name();
if (checkpointing_op_name2op_node.find(next_op_name) != checkpointing_op_name2op_node.end()
&& cur_node->parallel_desc() == next_node->parallel_desc()
&& visited_nodes.find(next_node) == visited_nodes.end()) {
queued_nodes.push(next_node);
CHECK(visited_nodes.insert(next_node).second);
}
});
}
}
}According to the current node (cur_node), find the next sub graph node (next_node), and use BFS search. The search logic is: cur_ Node as the starting point, traverse the nodes with consumption relationship on its input / input side next_ node; For the op that does not belong to checkpointing & & it has not been accessed as a sub graph node & & parallel mode and cur_ Node consistent node; As the target node (next_node) in the subgraph, insert it into the subgraph queue, mark the node as accessed and place it in visited_nodes Set.
3.3 traversal subgraphs
After the above process, the subgraph vector() is generated. We need to traverse it, filter out subgraphs related to activation checkpointing, and do the following:
-
Generate a fake subgraph and use it as input to the backward consumer (not the real subgraph)
-
Add the control edge from end op to all source nodes in the make subgraph
-
Add the fake subgraph to the job builder (managed by it)
The traversal of subgraphs mainly includes:
https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/checkpointing_pass.cpp#L148-L290
Filtering subgraphs independent of activation checkpointing
At the beginning of the [for (Auto & Subgraph: checkpointing_subgraphs) {}] () traversal loop, subgragh s that do not meet the activation checkpointing conditions will be skipped
for (auto& subgraph : checkpointing_subgraphs) {
// step 3.1 ignore this subgraph if there is no direct edge to backward pass op.
HashSet<const OpNode*> bw_consumers;
for (const OpNode* node : subgraph) {
node->ForEachNodeOnOutEdge([&](const OpNode* out_node) {
if (!IsForwardPassScope(Scope4OpNode(out_node))) {
bw_consumers.insert(out_node);
CHECK(subgraph.find(out_node) == subgraph.end());
}
});
}
if (bw_consumers.empty()) { continue; }The specific condition is to traverse all node nodes in the subgraph and judge all out edges of node nodes_ Whether the edges are connected to the backward consumer op. if all nodes in the subgraph are not connected to the backward consumer, skip the subgraph (indicating that the subgraph is only related to forward but not to backward, that is, it is not the target subgraph optimized by activation checkpointing.
Generate a fake subgraph and use it as input to the backward consumer (not the real subgraph)
After filtering out invalid subgraphs, for the target subgraph directly related to activation checkpointing, we need to generate a fake subgraph, in which each node is composed of a fake op.
Fake subgraphs, the smallest unit of recalculation, are used to replace the original real subgraphs and replace these real subgraphs later for consumption by backward op nodes. By changing the scope attribute of the fake op in the fake subgraph from kForwardPass to kBackwardPass, when the calculation reaches the fake OP, the forward calculation is rerun to generate the activation data required by the backward.
The main code for generating the fake subgraph is L168-L222
https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/checkpointing_pass.cpp#L168-L222
After generating the fake subgraph, set it as the input of backward consumers. The main codes are as follows:
const OpNode* first_bw_consumer = nullptr;
int32_t first_bw_order = std::numeric_limits<int32_t>::max();
// Change the input of the backward consumer to the make subgraph op (not the real subgraph)
// step 3.3 change bw consumers input from subgraph to fake subgraph
for (const OpNode* node : bw_consumers) {
std::string bw_consumer_name = node->op().op_name();
OperatorConf bw_consumer_op_conf;
// NOTE(chengcheng):
// reuse bw conumer op conf if it has been existed in map.
if (total_bw_consumers_op_name2conf.find(bw_consumer_name)
!= total_bw_consumers_op_name2conf.end()) {
bw_consumer_op_conf = total_bw_consumers_op_name2conf.at(bw_consumer_name);
} else {
bw_consumer_op_conf = node->op().op_conf();
}
CHECK_EQ(bw_consumer_name, bw_consumer_op_conf.name());
auto* user_conf = bw_consumer_op_conf.mutable_user_conf();
// Modify the blob name entered by backward op related to subgrade
// change input lbns if in subgraph
for (auto& pair : *(user_conf->mutable_input())) {
auto& list_s = pair.second;
for (int i = 0; i < list_s.s_size(); ++i) {
std::string old_lbn = list_s.s(i);
LogicalBlobId old_lbi = GenLogicalBlobId(old_lbn);
std::string old_input_op_name = old_lbi.op_name();
if (subgraph_op_name2op_node.find(old_input_op_name) != subgraph_op_name2op_node.end()) {
list_s.set_s(i, kCheckpointingFakeOpNamePrefix + old_lbn);
}
}
}
// NOTE(chengcheng):
// emplace maybe repeated, so do not check the return value
total_bw_consumers_op_name2conf.emplace(bw_consumer_name, bw_consumer_op_conf);
CHECK(op_node2order.find(node) != op_node2order.end());
int32_t this_order = op_node2order.at(node);
if (this_order < first_bw_order) {
first_bw_consumer = node;
first_bw_order = this_order;
}
}Add control edges for all source node - end node s in the make subgraph
The purpose of this step is to add a control edge to all nodes (source nodes) connected to the backward op in the subgraph. The addition of control edge is to artificially control the timing of execution between nodes. The control edge ensures that the calculation of fake subgraph occurs as late as possible, so as to shorten the life cycle and ensure the efficiency of memory reuse.
Add codes related to control edges in L267-L284:
https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/checkpointing_pass.cpp#L267-L284
// step 3.4 add control edge from End Op to all source node in fake subgraph
CHECK(first_bw_consumer != nullptr);
std::string end_op_name = kCheckpointingBadOpName;
int32_t end_order = -1;
first_bw_consumer->ForEachNodeOnInEdge([&](const OpNode* end_node) {
CHECK(op_node2order.find(end_node) != op_node2order.end());
int32_t this_order = op_node2order.at(end_node);
if (this_order > end_order) {
end_order = this_order;
end_op_name = end_node->op().op_name();
}
});
CHECK_NE(end_order, -1);
CHECK_NE(end_op_name, kCheckpointingBadOpName);
CHECK_LT(end_order, first_bw_order);
for (const auto& source_op_name : source_node_in_fake_subgraph) {
fake_op_name2conf.at(source_op_name).add_ctrl_in_op_name(end_op_name);
}Add the fake subgraph to the job build (managed by it)
The generation of fake subgraphs and the addition of control edges have actually changed the original job logic diagram. After the change, these newly generated fake op nodes in the fake subgraphs need to be added to the job builder management, and the rewriting of the logic diagram is officially completed.
The main codes are as follows:
// Add the ops contained in the fake subgraph to the job_builder Management (Figure rewritten)
// step 3.5 add fake subgraph ops to job builder
std::vector<OperatorConf> fake_op_confs;
for (auto& pair : fake_op_name2conf) { fake_op_confs.push_back(pair.second); }
job_builder->AddOps(parallel_conf, fake_op_confs);3.4 update all backward consumer ops
Finally, because make OP nodes updates the input and output attributes of backward op nodes, it is necessary to synchronize the updated backward op nodes to the job_builder Management:
// Update all backward ops in job builder
// step 4. update bw consumers in job builder only once
std::vector<OperatorConf> total_bw_consumer_op_confs;
for (auto& pair : total_bw_consumers_op_name2conf) {
total_bw_consumer_op_confs.push_back(pair.second);
}
job_builder->MutOpsOnlyOnce(total_bw_consumer_op_confs);
return Maybe<void>::Ok();So far, the rewriting of the whole job logic diagram has been completed through the insertion of these fake subgraphs and the change of input and output edges. The rewritten logic diagram automatically supports activation checkpointing when it is executed.
OneFlow has recently reappeared GPT-3 related work , which uses the technology of activation checkpointing. The code is open source in ONEFLOW benchmark. Welcome to download and try it in GitHub:
https://github.com/Oneflow-Inc/OneFlow-Benchmark/tree/master/LanguageModeling/GPT
Note: the title picture is from insspirito, pixabay
reference
[1] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training Deep Nets with Sublinear Memory Cost. arXiv preprint arXiv:1604.06174, 2016.
Recent articles
