Gain practical experience in crawling a complete HTML website through basic Python tools.
(number of words: 11235, reading time: about 14 minutes)
There are many great books that can help you learn Python, but who has really read these big books? Spoiler: not me anyway.
Many people find teaching books very useful, but I usually don't read a book from beginning to end to learn. I study by doing a project, trying to figure out some content, and then reading another book. So, throw away the book for the time being and let's learn Python together.
Next is a guide to my first Python crawl project. It requires a low level of hypothetical knowledge of Python and HTML. This article aims to explain how to use Python's requests library to access web page content, and use BeatifulSoup4 library and JSON and pandas libraries to parse web page content. I'll give you a brief introduction to the Selenium library, but I won't delve into how to use it -- a topic worthy of my own tutorial. Finally, I want to show you some tips and tricks to reduce the problems encountered in the process of web crawling.
Installation dependency
my GitHub All resources for this guide are available in the repository. If you need help installing Python 3, check the tutorials for Linux, Windows, and Mac.
$ python3 -m venv $ source venv/bin/activate $ pip install requests bs4 pandas
If you like to use JupyterLab , you can use notebook Run all code. There are many ways to install JupyterLab, one of which is:
# from the same virtual environment as above, run: $ pip install jupyterlab
Set goals for website crawl projects
Now that we have installed the dependencies, what do we need to do to crawl the web page?
Let's take a step back and make sure the goal is clear. The following is a list of requirements for successfully completing the web page crawling project:
- The information we collect is worthy of our great efforts to build an effective web crawler.
- The information we download can be collected legally and ethically through the web crawler.
- Have a certain understanding of how to find the target information in HTML code.
- Use the right tools: in this case, you need to use the beautiful soup library and the requests library.
- Know (or be willing to learn) how to parse JSON objects.
- Have sufficient pandas data processing skills.
Note on HTML: html is a "beast" running on the Internet, but what we need to know most is how tags work. A tag is a pair of keywords surrounded by angle brackets (usually appear in pairs, and its content is between two tags). For example, this is a fake label called Pro tip:
<pro-tip> All you need to know about html is how tags work </pro-tip>
We can access the information by calling the tag Pro tip (All you need to know...). This tutorial will further explain how to find and access tags. To learn more about the basics of HTML, check out this article.
What are you looking for in the website crawling project
Some data collection methods are more suitable than other methods. The following are the guidelines for projects that I think are appropriate:
There is no public API available for data (processing). Capturing structured data through the API is much easier (so there is no API) to help clarify the legitimacy and ethics of data collection. Only with a considerable amount of structured data and regular and repeatable format can we prove the rationality of this effort. Web crawling can be painful. Beautiful soup (bs4) makes the operation easier, but it cannot avoid the individual particularity of the website and needs to be customized. The same formatting of the data is not necessary, but it does make things easier. The more "marginal cases" (deviations from norms) exist, the more complex the crawling is.
Disclaimer: I have not participated in legal training; The following is not intended as formal legal advice.
With regard to legitimacy, access to a large amount of valuable information may be exciting, but just because it is possible does not mean that it should be done.
Fortunately, there are some public information that can guide our ethics and web crawling tools. Most websites have robots.txt files associated with the website, indicating which crawling activities are allowed and which are not allowed. It is mainly used to interact with search engines (the ultimate form of web crawler). However, many information on the website is regarded as public information. Therefore, the robots.txt file was considered a set of recommendations rather than a legally binding document. The robots.txt file does not cover topics such as ethical data collection and use.
Before you start crawling items, ask yourself the following questions:
- Am I crawling for copyrighted materials?
- Will my crawling activities endanger my privacy?
- Did I send a large number of requests that might overload or damage the server?
- Will crawling reveal the intellectual property I don't own?
- Are there any terms of service regulating the use of the website, and have I followed these terms?
- Will my crawling activities reduce the value of raw data? (for example, do I intend to repackage data as is, or perhaps extract website traffic from the original source)?
When I climb a website, please make sure I can answer "no" to all these questions.
For an in-depth understanding of these legal issues, please refer to the legality and morality of Web crawling written by Krotov and Silva and Sellars's two decades of Web crawling and computer fraud and abuse act published in 2018.
Now start crawling the website
After the above evaluation, I came up with a project. My goal is to crawl the addresses of all Family Dollar stores in Idaho. These stores are very large in rural areas, so I'd like to know how many such stores there are.
The starting point is the location page of Family Dollar
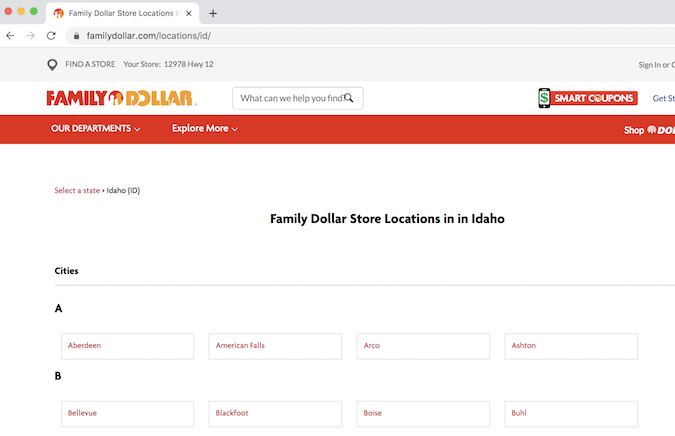
Idaho Family Dollar Location page
First, let's load the prerequisites in the Python virtual environment. The code here will be added to a Python file (scraper.py if you want a name) or run in the cell of JupyterLab.
import requests # for making standard html requests from bs4 import BeautifulSoup # magical tool for parsing html data import json # for parsing data from pandas import DataFrame as df # premier library for data organization
Next, we request data from the target URL.
page = requests.get("https://locations.familydollar.com/id/")
soup = BeautifulSoup(page.text, 'html.parser')
BeautifulSoup Converts HTML or XML content into complex tree objects. These are several common object types that we will use.
- Beautiful soup -- parsed content
- Tag -- standard HTML tag, which is the main type of bs4 element you will encounter
- NavigableString -- text string within the label
- Comment -- a special type of NavigableString
When we look requests.get() There are more issues to consider when exporting. I only use page.text() to convert the requested page to readable content, but there are other output types:
- page.text() text (most common)
- page.content() output byte by byte
- page.json() JSON object
- page.raw() raw socket response (not useful to you)
I only operate on pure English websites that use Latin letters. The default encoding settings in requests can solve this problem well. However, in addition to pure English websites, there is a larger Internet world. To ensure that requests correctly parse the content, you can set the encoding of the text:
page = requests.get(URL) page.encoding = 'ISO-885901' soup = BeautifulSoup(page.text, 'html.parser')
Study carefully BeautifulSoup Label, we see:
- The bs4 element tag captures an HTML tag.
- It has names and attributes that can be accessed like a dictionary: tag['someAttribute '].
- If the label has multiple attributes with the same name, only the first instance is accessed.
- Sub tags can be accessed through tag.contents.
- All tag descendants can be accessed through tag.contents.
- You can always use the following string: re.compile("your_string") to access all the contents of a string instead of browsing the HTML tree.
Determine how to extract the corresponding content
Warning: this process can be frustrating.
The extraction in the process of website crawling may be a daunting process full of misunderstandings. I think the best way to solve this problem is to start with a representative example and then extend it (this principle is applicable to any programming task). It is important to view the HTML source code of the page. There are many ways to do this.
You can use Python to view the entire source code of the page in the terminal (not recommended). Running this code is at your own risk:
print(soup.prettify())
Although the entire source code of the printed page may be applicable to the toy examples shown in some tutorials, most modern websites have a lot of content on the page. Even 404 pages may be full of code such as headers and footers.
In general, it is easiest to browse the source code through "view page source code" in your favorite browser (right-click and select "view page source code"). This is the most reliable way to find the target content (I'll explain why later).

Family Dollar Page source code
In this case, I need to find my target content - address, city, state and zip code - in this huge ocean of HTML. Usually, a simple search of the page source (ctrl+F) will get the location of the target location. Once I actually see an example of the target content (the address of at least one store), I find the attributes or tags that distinguish the content from other content.
First, I need to collect the web sites of different cities in the Family Dollar store in Idaho, and visit these websites to obtain address information. These URLs seem to be included in the href tag. That is great! I'll try to use find_ Search with the all command:
dollar_tree_list = soup.find_all('href')
dollar_tree_list
Searching for href won't produce any results, damn it. This may fail because href is nested in the itemlist class. For the next attempt, search for item_list. Since class is a reserved word in Python, class is used_ As an alternative. soup.find_all() was originally the Swiss Army knife of the bs4 function.
dollar_tree_list = soup.find_all(class_ = 'itemlist') for i in dollar_tree_list[:2]: print(i)
Interestingly, I found that searching for a specific class is generally a successful method. By finding out the type and length of the object, we can learn more about the object.
type(dollar_tree_list) len(dollar_tree_list)
You can use. contents to extract content from the beautifulsup result set. This is also a good time to create a single representative example.
example = dollar_tree_list[2] # a representative example example_content = example.contents print(example_content)
Use. attr to find the attributes that exist in the content of the object. Note:. contents usually returns an exact list of items, so the first step is to index the item using square brackets.
example_content = example.contents[0] example_content.attrs
Now, I can see that href is an attribute that can be extracted like a dictionary item:
example_href = example_content['href'] print(example_href)
Integrated website capture tool
All these explorations provide us with a way forward. This is a clean-up version of the above logic.
city_hrefs = [] # initialise empty list for i in dollar_tree_list: cont = i.contents[0] href = cont['href'] city_hrefs.append(href) # check to be sure all went well for i in city_hrefs[:2]: print(i)
The output is a list about capturing the URL of the Idaho Family Dollar store.
In other words, I still haven't got the address information! Now, you need to grab the URL of each city to get this information. Therefore, we use a representative example to restart the process.
page2 = requests.get(city_hrefs[2]) # again establish a representative example soup2 = BeautifulSoup(page2.text, 'html.parser')
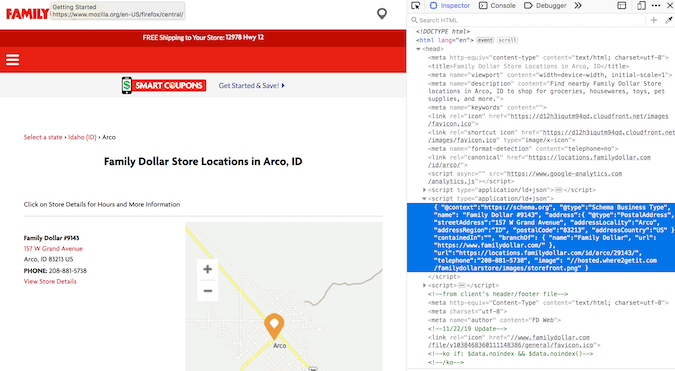
Family Dollar Maps and codes
The address information is nested in type="application/ld+json". After a lot of geographical location crawling, I began to realize that this is a general structure for storing address information. Fortunately, soup.find_all() turns on search using type.
arco = soup2.find_all(type="application/ld+json") print(arco[1])
The address information is in the second list member! i see!
Use. contents to extract (from the second list item) content (this is the appropriate default action after filtering). Similarly, since the output content is a list, I index the list item:
arco_contents = arco[1].contents[0] arco_contents
Oh, it looks good. The format provided here is consistent with the json format (and the name of the type does contain "json"). json objects behave like dictionaries with nested dictionaries. Once you're familiar with using it to work, it's actually a good format (of course, it's easier to program than a long string of regular expression commands). Although it looks like a json object structurally, it is still a bs4 object and needs to be programmatically converted to a json object to access it:
arco_json = json.loads(arco_contents)
type(arco_json) print(arco_json)
In this content, there is a called address key, which requires the address information to be in a relatively small nested dictionary. It can be retrieved as follows:
arco_address = arco_json['address'] arco_address
OK, please pay attention. Now I can traverse the list of Idaho URL s:
locs_dict = [] # initialise empty list for link in city_hrefs: locpage = requests.get(link) # request page info locsoup = BeautifulSoup(locpage.text, 'html.parser') # parse the page's content locinfo = locsoup.find_all(type="application/ld+json") # extract specific element loccont = locinfo[1].contents[0] # get contents from the bs4 element set locjson = json.loads(loccont) # convert to json locaddr = locjson['address'] # get address locs_dict.append(locaddr) # add address to list
Use Pandas to organize our website and capture results
We load a lot of data in the dictionary, but there are some additional useless items that make reusing data more complex than needed. To perform the final data organization, we need to convert it to the Pandas data framework, delete the unnecessary columns @ type and country, and check the first five rows to ensure that everything is normal.
locs_df = df.from_records(locs_dict) locs_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True) locs_df.head(n = 5)
Make sure to save the results!!
df.to_csv(locs_df, "family_dollar_ID_locations.csv", sep = ",", index = False)
We did it! All Idaho Family Dollar stores have a comma separated list. How exciting.
Selenium and data capture
Selenium is a common tool for automatic interaction with web pages. To explain why it is sometimes necessary, let's take a look at an example of using the Walgreens website. The check element provides the code for what the browser displays:
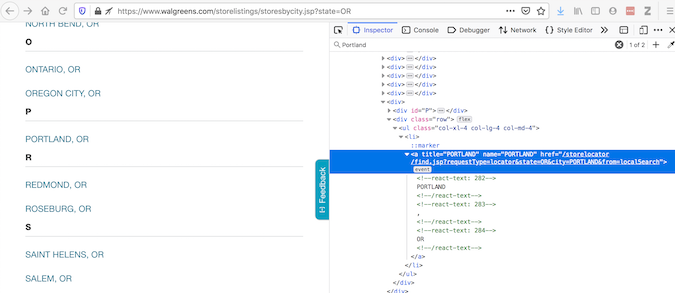
Although "view page source code" provides code on what requests will get:
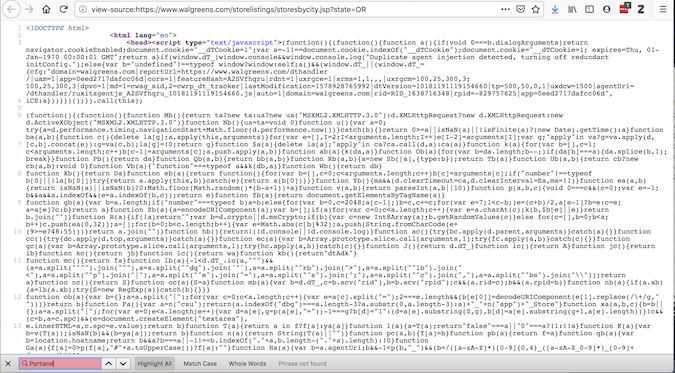
If the two are inconsistent, there are some plug-ins that can modify the source code -- therefore, you should access the page after it is loaded into the browser. requests can't do this, but Selenium can.
Selenium needs a Web driver to retrieve content. In fact, it opens a Web browser and collects the content of this page. Selenium is powerful - it can interact with loaded content in many ways (please read the documentation). After using selenium to obtain data, continue to use BeautifulSoup as before:
url = "https://www.walgreens.com/storelistings/storesbycity.jsp?requestType=locator&state=ID" driver = webdriver.Firefox(executable_path = 'mypath/geckodriver.exe') driver.get(url) soup_ID = BeautifulSoup(driver.page_source, 'html.parser') store_link_soup = soup_ID.find_all(class_ = 'col-xl-4 col-lg-4 col-md-4')
In the case of Family Dollar, I don't need Selenium, but when the content presented is different from the source code, I do keep Selenium.
Summary
In short, when using website crawling to accomplish meaningful tasks:
- Be patient
- Consult manuals (they are very helpful)
If you are curious about the answer:
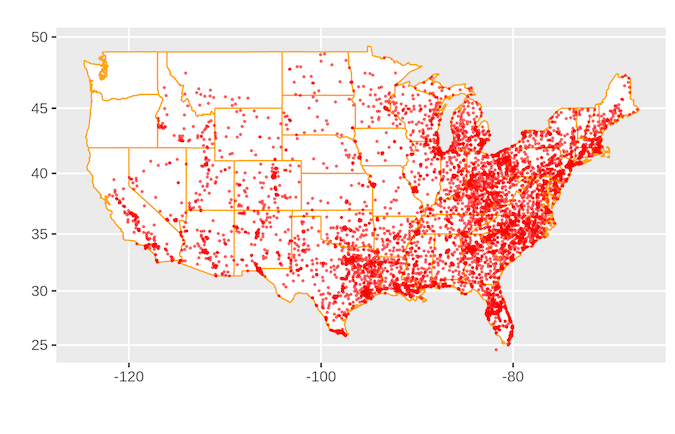
Family Dollar location map
There are many Family Dollar stores in the United States.
The complete source code is:
import requests
from bs4 import BeautifulSoup
import json
from pandas import DataFrame as df
page = requests.get("https://www.familydollar.com/locations/")
soup = BeautifulSoup(page.text, 'html.parser')
# find all state links
state_list = soup.find_all(class_ = 'itemlist')
state_links = []
for i in state_list:
cont = i.contents[0]
attr = cont.attrs
hrefs = attr['href']
state_links.append(hrefs)
# find all city links
city_links = []
for link in state_links:
page = requests.get(link)
soup = BeautifulSoup(page.text, 'html.parser')
familydollar_list = soup.find_all(class_ = 'itemlist')
for store in familydollar_list:
cont = store.contents[0]
attr = cont.attrs
city_hrefs = attr['href']
city_links.append(city_hrefs)
# to get individual store links
store_links = []
for link in city_links:
locpage = requests.get(link)
locsoup = BeautifulSoup(locpage.text, 'html.parser')
locinfo = locsoup.find_all(type="application/ld+json")
for i in locinfo:
loccont = i.contents[0]
locjson = json.loads(loccont)
try:
store_url = locjson['url']
store_links.append(store_url)
except:
pass
# get address and geolocation information
stores = []
for store in store_links:
storepage = requests.get(store)
storesoup = BeautifulSoup(storepage.text, 'html.parser')
storeinfo = storesoup.find_all(type="application/ld+json")
for i in storeinfo:
storecont = i.contents[0]
storejson = json.loads(storecont)
try:
store_addr = storejson['address']
store_addr.update(storejson['geo'])
stores.append(store_addr)
except:
pass
# final data parsing
stores_df = df.from_records(stores)
stores_df.drop(['@type', 'addressCountry'], axis = 1, inplace = True)
stores_df['Store'] = "Family Dollar"
df.to_csv(stores_df, "family_dollar_locations.csv", sep = ",", index = False)
① More than 2000 Python e-books (both mainstream and classic books should be available)
② Python standard library materials (the most complete Chinese version)
③ Project source code (forty or fifty interesting and classic hand training projects and source code)
④ Videos on basic introduction to Python, crawler, web development and big data analysis (suitable for Xiaobai)
⑤ Python learning roadmap (bid farewell to non stream learning)
python super full database installation package learning route project source code free sharing