reference resources
Detailed explanation of Tomcat (5) -- Connector analysis This article explains the behavior of connectors under BIO and NIO
Pre knowledge
This article will be based on BIO, http1 1 to read the source code. You need to know that the Acceptor thread of the Connector receives a new connection (socket) and will create a SocketProcessor to process subsequent requests. If not, read:
- A request analysis of Tomcat 7 (I) generation of processing thread
- A request analysis of Tomcat 7 (II) converting Socket into internal request object
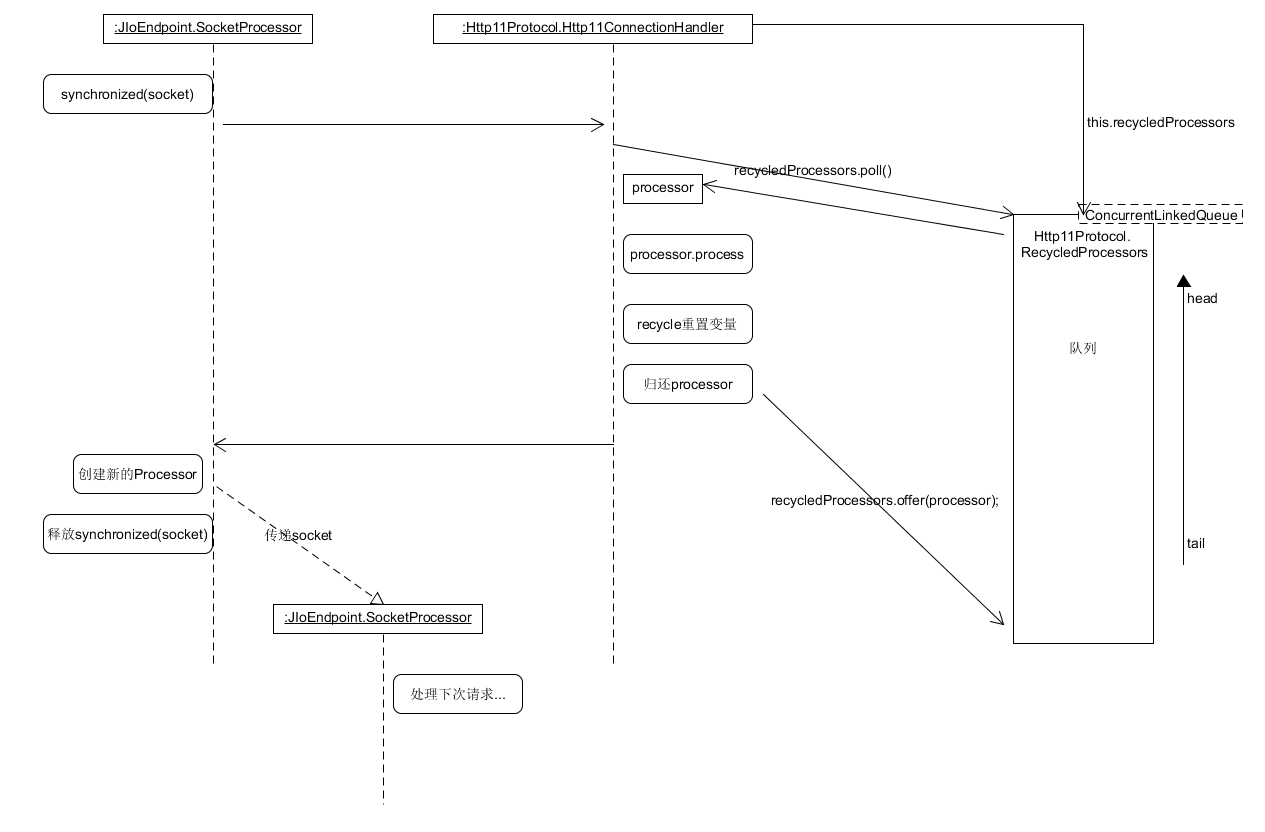
This article will explain how the SocketProcessor handles subsequent requests after receiving a new connection, as well as the reuse of "Processor" and "Request". The diagram is as follows:

JIoEndpoint.SocketProcessor
After obtaining a new connection, the SocketProcessor is used to process a request. Let's remember a concept first:
- A SocketProcessor is used to process a request. After this request, the SocketProcessor thread dies. The next request is processed by another SocketProcessor thread.
- Before the death of the previous SocketProcessor, a new SocketProcessor will be created to empty the memory related to the Request parameters (in fact, reset and empty all Request parameters instead of freeing memory) and connect, and submit the connection to the new SocketProcessor.
Let's take a look at socketprocessor run:
@Override
public void run() {
synchronized (socket) {
try {
SocketState state = SocketState.OPEN;
...
if ((state != SocketState.CLOSED)) {
if (status == null) {
state = handler.process(socket, SocketStatus.OPEN_READ);
} else {
state = handler.process(socket,status);
}
}
...
} finally {
if (launch) {
try {
getExecutor().execute(new SocketProcessor(socket, SocketStatus.OPEN_READ));
}
...
}
}
}
socket = null;
// Finish up this request
}
}The work done can be summarized as follows:
- handler.process lets the handler (here Http11Protocol.Http11ConnectionHandler) handle specific transactions
- getExecutor().execute(...) Create a new SocketProcessor and give it to the thread pool.
- Leave the synchronized code block and end the life cycle.
(synchronized is used to synchronize sockets. After all, it will be handed over between the old and new socketprocessors.)
Then we'll analyze the handler Process behavior.
Http11Protocol.Http11ConnectionHandler
The process method is inherited from AbstractProtocol. Let's analyze:
public SocketState process(SocketWrapper<S> wrapper,
SocketStatus status) {
...
S socket = wrapper.getSocket();
...
try {
if (processor == null) {
processor = recycledProcessors.poll();
}
if (processor == null) {
processor = createProcessor();
}
SocketState state = SocketState.CLOSED;
do {
...
else if (state == SocketState.ASYNC_END) {
state = processor.asyncDispatch(status);
getProtocol().endpoint.removeWaitingRequest(wrapper);
if (state == SocketState.OPEN) {
state = processor.process(wrapper);
}
}
...
else {
state = processor.process(wrapper);
}
} while (...);
if (state == SocketState.LONG) {
...
} else if (state == SocketState.OPEN) {
// In keep-alive but between requests. OK to recycle
// processor. Continue to poll for the next request.
connections.remove(socket);
release(wrapper, processor, false, true);
}
...
return state;
}
catch (Throwable e) {
...
}
...
}Let me first explain the purpose of several variables / functions to explain: recycledProcessors is a concurrent queue whose elements are used to process subsequent requests. Through recycledProcessors poll(); Take out a processor (if not, call createProcessor() to create one) and call processor Process processes the following requests, and finally calls release(wrapper, processor, false, true); Reset and empty all variables in it (instead of freeing memory. This is to avoid repeated memory requests).
About release(wrapper, processor, false, true); I'll explain this further. Let's take a look at http11protocol Http11ConnectionHandler. release:
public void release(SocketWrapper<Socket> socket,
Processor<Socket> processor, boolean isSocketClosing,
boolean addToPoller) {
processor.recycle(isSocketClosing); // Reset empty variable
recycledProcessors.offer(processor); // Return to recycledProcessors for next use
}I annotated the function of the two-line function call. Let's look at the implementation of recycle. The processor type is Http11Processor, but recycle is implemented in the parent class AbstractHttp11Processor: Its function is roughly as follows:
@Override
public final void recycle(boolean isSocketClosing) {
getAdapter().checkRecycled(request, response);
if (.. != null) {
getXXX().recycle();
}
... = null
.. = -1;
.. = false;
resetErrorState();
recycleInternal(); // empty
}
@Override
protected void recycleInternal() {
// Recycle
this.socketWrapper = null;
// Recycle ssl info
sslSupport = null;
}By calling recycle(), setting it to - 1 or false, a bunch of variables are reset to the initial state, but the memory involving the array is not released. If you are still not sure about the behavior of recycle(), you can track it yourself. There is no need to spend too much time here.
I always translate recycle as "reset clear", not "recycle", because "recycle" may mislead readers into thinking that memory has been recycled and released. In fact, in order to avoid repeatedly applying for memory, most variable and array memory are not released.
Let's get getinputbuffer() recycle(); Take a look at the source code abstractinputbuffer recycle:
public void recycle() {
// Recycle Request object
request.recycle();
...
}This involves the reset of request. It indicates that the request will be recycled
Picture summary
summary
The civilization identified the following points:
- After the socket is established, it will be passed between socketprocessors. Here, the function of SocketProcessor is "worker"
- In BIO, each request is processed by one thread. After a request is processed, all variables are reset and handed over to the next thread for scheduling.
- Request and http11processor (the function is "processor") are recycled.