Use of Torchvison-dataset
Here are some of the ways in which database datasets are used in Torchvision.
First we can see many datasets in Torchvision in the Pytorch Watch:
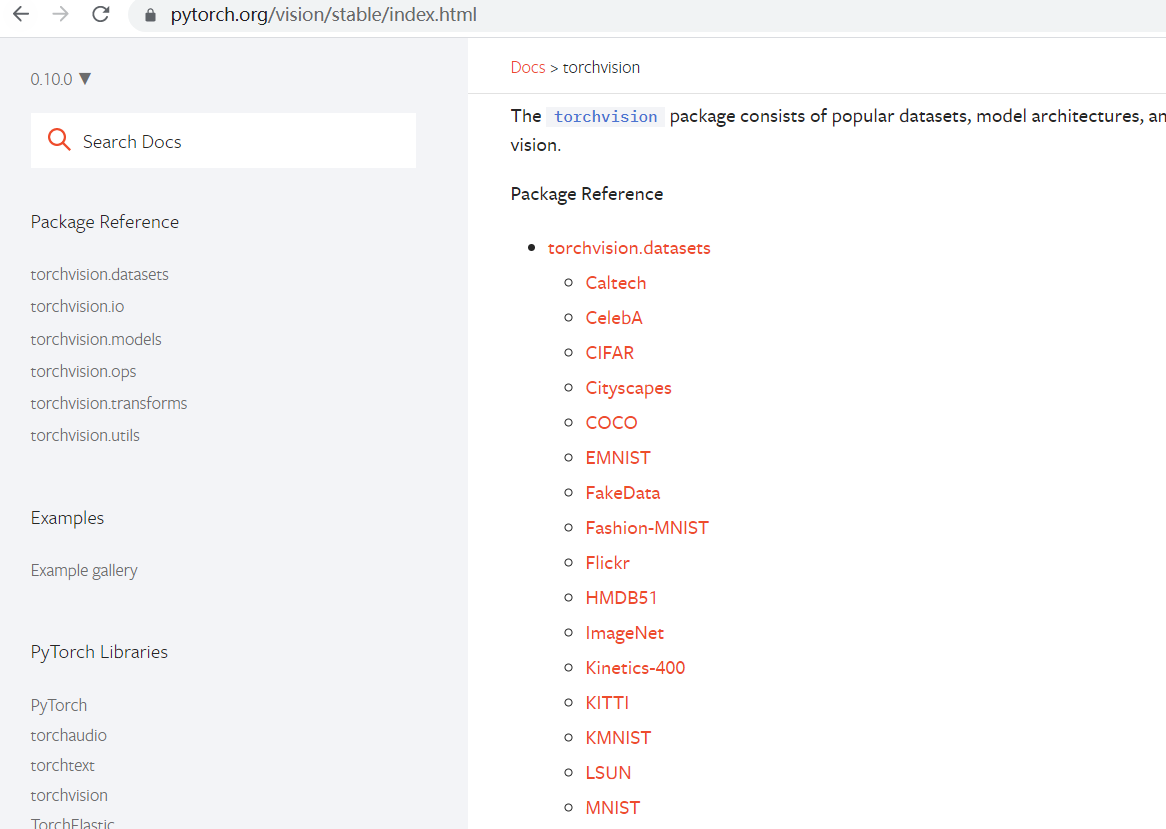
With CIFAR as an example, you can learn more about the dataset when you point in:

The settings and functions of some parameters when calling the database are described here.
Use of Dataset:
First, we need to import the torchvision library, provide the library for subsequent calls to the database, and import the SummaryWriter library, using the tersorboard visualization process:
import torchvision from torch.utils.tensorboard import SummaryWriter
We define train_set is used to call the CIFAR10 dataset:
torchvision.datasets.CIFAR10()
train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
(1) The directory location where root=''saves the dataset
(2) The train is True to represent the dataset for training, otherwise it is used for the test set
(3) Transform can define its own operation content (refer to the official document: transform (callable, optional) - A function/transform that takes in an PIL image and returns a transformed version. E.g., transforms.RandomCrop) for the purpose of converting PIL image data into tensor-type function operations.
(4) True download means automatic download if the dataset does not exist; Do not download if dataset exists
Display the first 10 samples in the dataset on the tersorboard using a for loop:
writer = SummaryWriter("p10")
for i in range(10):
img,target=train_set[i]
writer.add_image('dataset',img,i)
The results shown on tensorboard are:

Full implementation code:
import torchvision
from torch.utils.tensorboard import SummaryWriter
#Define dataset_transform, complete converting the PIL file to a tensor-type compose()
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target=train_set[i]
writer.add_image('dataset',img,i)
writer.close()
Use of Data Loader
First import the module:
import torchvision #Prepared Test Set from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter
Using the CIFAR dataset above:
test_data = torchvision.datasets.CIFAR10(root='./dataset_learn',train=False,transform=torchvision.transforms.ToTensor())
Using the DataLoader() function:
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
The parameters here mean:
Dataset: Target dataset used
(2) batch_size: refers to how many samples are loaded per batch
(3) shuffle: True means that the data is shuffled during each epoch
(4) num_works:Represents how many subprocesses yong uses to load data during loading
drop_last: When set to Ture, if the last remaining number of samples is less than batch_ When size is not large enough to be grouped, the remaining number of samples is discarded
Use a for loop to follow batch_size=64 is grouped and displayed on tensorboard:
writer = SummaryWriter('dataloader')
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images('epoch:{}'.format(epoch),imgs,step)
step=step+1
writer.close()
Result Display 👇:

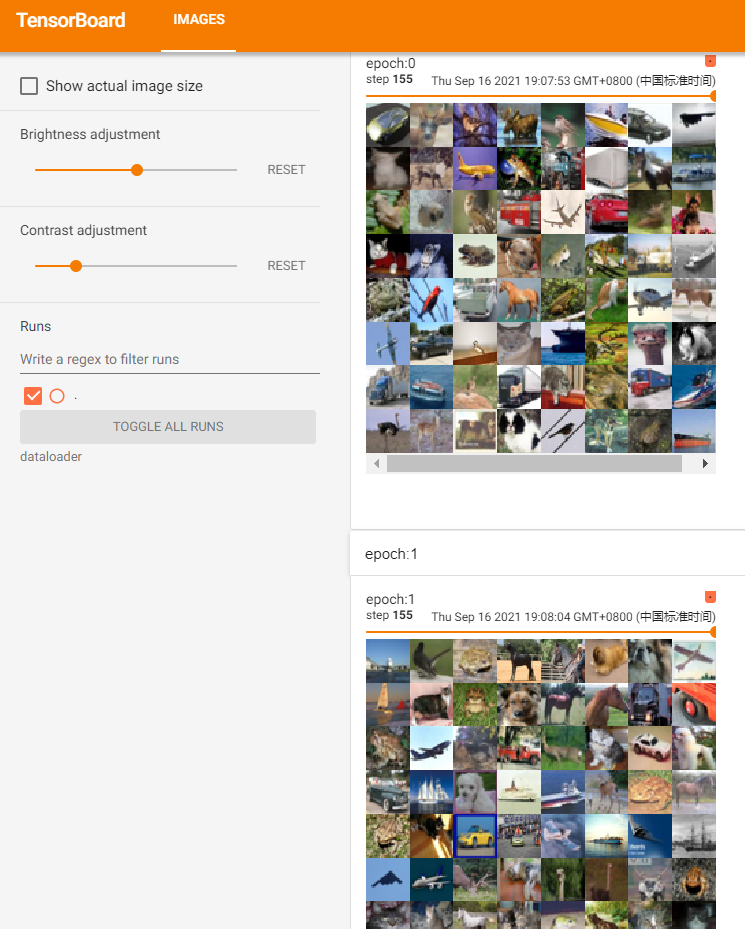
We compare the effects of the shuffle parameter:
At this point we will shuffle=True, which means that each new epoch, that is, each new training, will disrupt the order of the original dataset. We can see that the sample order of epoch0 and epoch1 under the same step has changed:
We understand drop_by contrast Role of last parameter:
drop_last: When set to Ture, if the last remaining number of samples is less than batch_ When size is not large enough to be grouped, the remaining number of samples is discarded.
When we set the parameter False, the number of sample pictures at step 156 iteration was not enough batch_size 64, so only two rows and sixteen samples are shown 👇:

When we drop_ When last parameter is set to True, run again and we find that the last step does not satisfy batch_size size pictures are discarded, so there are only 155 steps 👇:

Full implementation code:
import torchvision
#Prepared Test Set
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root='./dataset_learn',train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
'''drop_last Set to Ture If the last remaining number of samples is less than 64 and not enough to be grouped into groups, the remaining number of samples will be discarded '''
'''shuffle Set to Ture Each selected sample will be disrupted '''
writer = SummaryWriter('dataloader')
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images('epoch:{}'.format(epoch),imgs,step)
step=step+1
writer.close()
Summary:
Core statement of the Dataset database call (parameter explanation above):
import torchvision train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
Core statement of the Dataloader database call (parameter explanation above):
import torchvision from torch.utils.data import DataLoader test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)