1, Background
By providing general capabilities such as comment publishing, likes, reports and custom comment sorting, vivo comment center helps the front desk business quickly build comment functions and provide comment operation capabilities, avoiding the repeated construction of front desk business and the problem of data island. At present, 10 + services such as vivo short video, vivo browser, negative one screen and vivo mall have been accessed. The traffic size and fluctuation range of these services are different. How to ensure the high availability of each foreground business and avoid the unavailability of other businesses due to the surge of traffic of one business? The comment data of all businesses are stored by the middle office. Their data volume and db pressure are different. As the middle office, how should we isolate the data of each business and ensure the high availability of the whole middle office system?
This article will share with you the solution of vivo comment center, which is mainly processed from two parts: traffic isolation and data isolation.
2, Flow isolation
2.1 traffic grouping
vivo browser business is one hundred million daily activities, and real-time hot news is push ed all over the network. For such important businesses with large number of users and large traffic, we provide separate clusters to provide services for them to avoid being affected by other businesses.
vivo comments center provides external services through Dubbo interface. We logically divide the whole service cluster through Dubbo tag routing. A Dubbo call can intelligently select the service provider of the corresponding tag according to the tag tag carried by the request. As shown in the figure below:
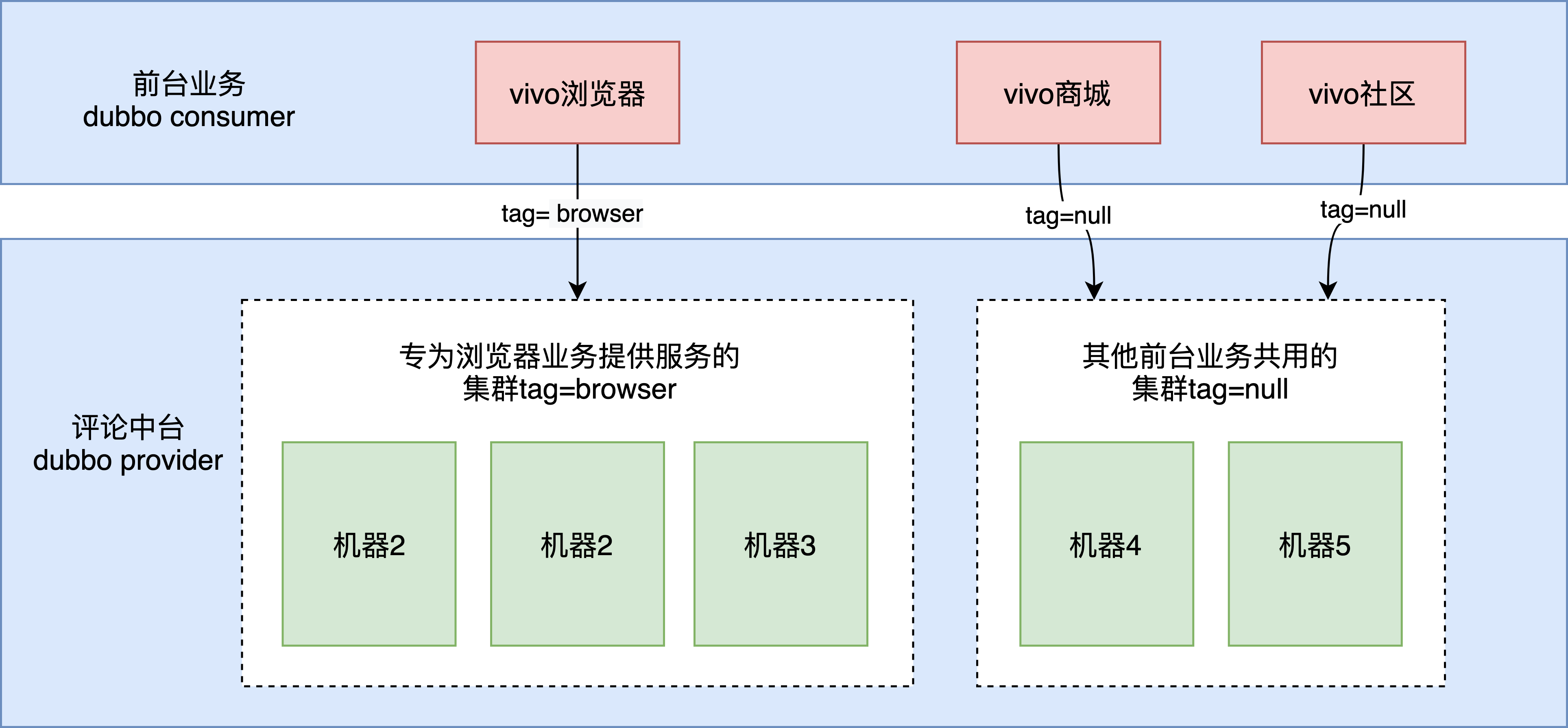
1) provider tagging: at present, there are two ways to complete instance grouping: dynamic rule tagging and static rule tagging. Among them, dynamic rules have higher priority than static rules. When the two rules exist at the same time and conflict, the dynamic rules will prevail. The internal operation and maintenance system of the company well supports dynamic marking by marking the machine with the specified ip (non docker container, machine ip is fixed).

2) When requesting the foreground service, specify the following label:;
The front desk specifies the routing label of the middle desk
RpcContext.getContext().setAttachment(Constants.REQUEST_TAG_KEY,"browser");
The scope of the request tag is every invocation. You only need to set the tag before calling the comment center service. The foreground service calling the provider of other services is not affected by the routing tag.
2.2 multi tenant current limiting
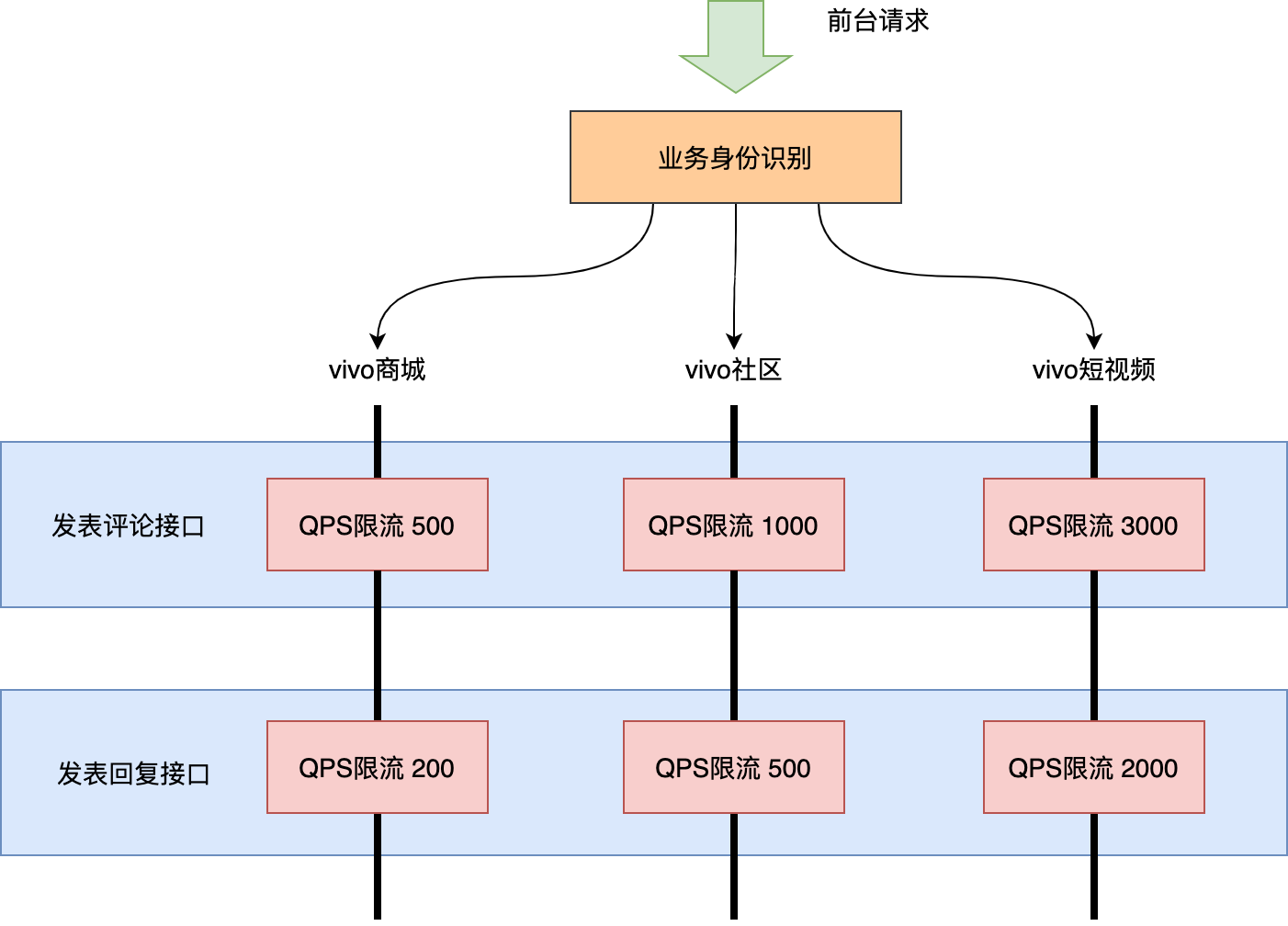
Large traffic services are isolated through separate clusters. However, the cost of deploying clusters independently is high, and it is impossible to deploy a set of clusters independently for each foreground business. In most cases, multiple services still need to share a set of clusters. How to deal with sudden traffic when services sharing clusters encounter? Yes, current limit! However, at present, many current limiting methods limit the overall QPS of the interface in a one size fits all manner. In this way, the traffic surge of a certain foreground business will lead to the flow restriction of all foreground business requests.
This requires the introduction of multi tenant flow restriction (a tenant here can be understood as a foreground business), and supports the flow restriction processing of different tenants of the same interface. The effect is shown in the figure below:
Implementation process:
We use sentinel's hotspot parameter current limiting feature, and use the service ID code as the hotspot parameter to configure different flow control sizes for each service.
So what is the hotspot parameter? First of all, let's talk about what hot spots are. Hot spots are frequently accessed data. Many times, we want to count the Top n data with the highest access frequency in a hot data and restrict its access. For example:
-
Commodity ID is a parameter that counts and limits the most frequently purchased commodity ID in a period of time.
-
User ID is a parameter that limits the user ID that is accessed frequently over a period of time.
Hotspot parameter current limiting will count the hotspot parameters in the incoming parameters, and limit the current of resource calls containing hotspot parameters according to the configured current limiting threshold and mode. Hotspot parameter current limiting can be regarded as a special flow control, which is only effective for resource calls containing hotspot parameters. Sentinel uses LRU strategy to count the most frequently accessed hot spot parameters recently, and combines token bucket algorithm to carry out parameter level flow control. The following figure shows an example of a comment scenario:
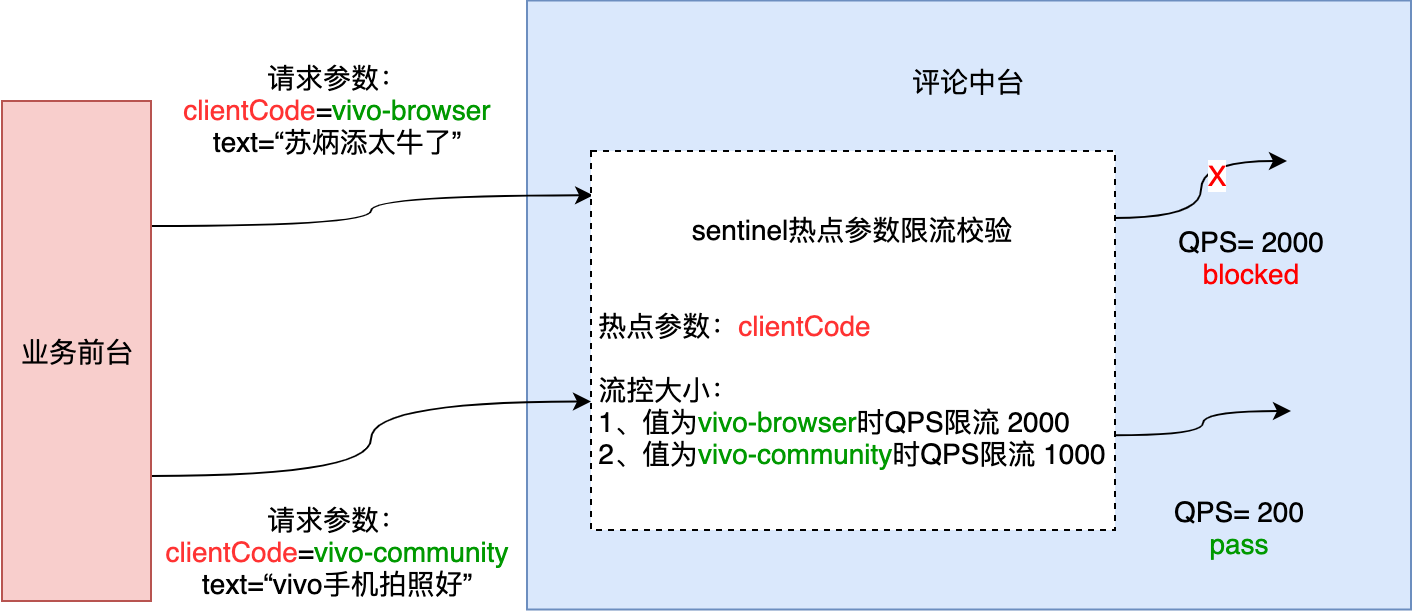
Using Sentinel for resource protection is mainly divided into several steps: defining resources, defining rules, and rule validation.
1) Define resources:
It can be understood here as the API interface path of each middle platform.
2) Define rules:
Sentienl supports many rules, such as QPS flow control, adaptive current limiting, hotspot parameter current limiting, cluster current limiting, etc. Here we use single machine hotspot parameter current limiting.
Hot spot parameter current limiting configuration
{
"resource": "com.vivo.internet.comment.facade.comment.CommentFacade:comment(com.vivo.internet.comment.facade.comment.dto.CommentRequestDto)", // Interface requiring current limiting
"grade": 1, // QPS current limiting mode
"count": 3000, // Interface default current limit size 3000
"clusterMode": false, // standalone mode
"paramFieldName": "clientCode", // Specify the hotspot parameter name, that is, the business party code field. Here we have optimized the sentinel component and added the configuration attribute to specify the attribute name of the parameter object as the hotspot parameter key
"paramFlowItemList": [ // Hot spot parameter current limiting rules
{
"object": "vivo-community", // When clientCode is this value, the current limiting rule is matched
"count": 1000, // The current limiting size is 1000
"classType": "java.lang.String"
},
{
"object": "vivo-shop", // When clientCode is this value, the current limiting rule is matched
"count": 2000, // The current limiting size is 2000
"classType": "java.lang.String"
}
]
}
3) Rule validation processing:
When the current limiting rule is triggered, sentinel will throw a ParamFlowException exception. It is not elegant to directly throw the exception to the foreground business for processing. Sentinel provides us with a unified exception callback processing entry DubboAdapterGlobalConfig, which supports us to convert exceptions into business custom results.
User defined current limiting return result;
DubboAdapterGlobalConfig.setProviderFallback((invoker, invocation, ex) -> AsyncRpcResult.newDefaultAsyncResult(FacadeResultUtils.returnWithFail(FacadeResultEnum.USER_FLOW_LIMIT), invocation));
What additional optimizations have we made:
1) The company's internal current limiting console does not support hot spot parameter current limiting configuration, so we have added a new current limiting configuration controller to support dynamic distribution of current limiting configuration through the configuration center. The overall process is as follows:
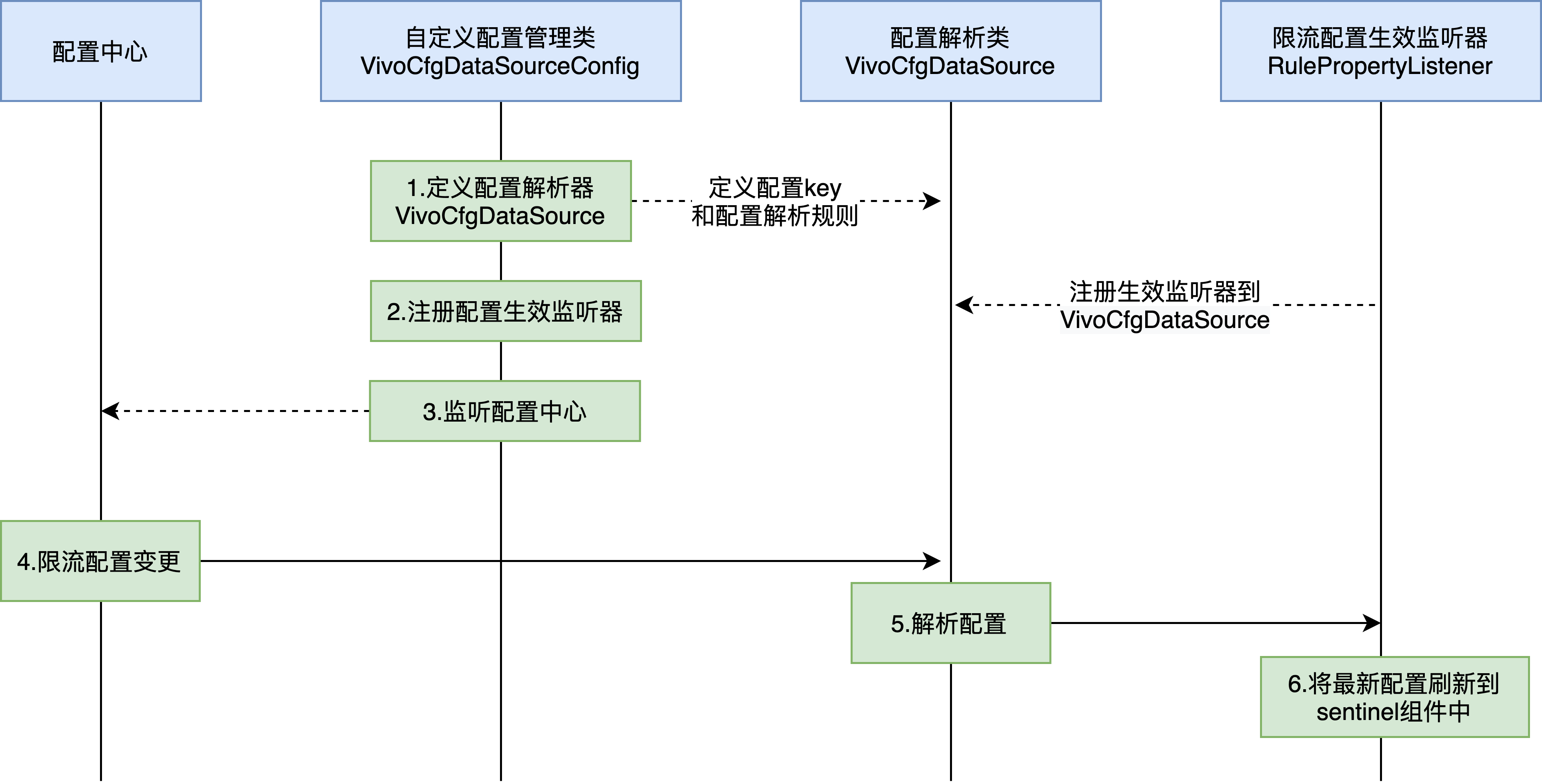
Dynamic distribution of current limiting configuration;
public class VivoCfgDataSourceConfig implements InitializingBean {
private static final String PARAM_FLOW_RULE_PREFIX = "sentinel.param.flow.rule";
@Override
public void afterPropertiesSet() {
// Custom configuration resolution object
VivoCfgDataSource<List<ParamFlowRule>> paramFlowRuleVivoDataSource = new VivoCfgDataSource<>(PARAM_FLOW_RULE_PREFIX, sources -> sources.stream().map(source -> JSON.parseObject(source, ParamFlowRule.class)).collect(Collectors.toList()));
// Register configuration validation listener
ParamFlowRuleManager.register2Property(paramFlowRuleVivoDataSource.getProperty());
// Initialize current limiting configuration
paramFlowRuleVivoDataSource.init();
// Monitoring configuration center
VivoConfigManager.addListener(((item, type) -> {
if (item.getName().startsWith(PARAM_FLOW_RULE_PREFIX)) {
paramFlowRuleVivoDataSource.updateValue(item, type);
}
}));
}
}
2) The native sentinel specifies the current limiting hotspot parameters in two ways:
-
The first is to specify the nth parameter of the interface method;
-
The second method is to inherit the ParamFlowArgument from the method parameter and implement the ParamFlowKey method. The return value of this method is the value value of the hotspot parameter.
These two methods are not flexible. The first method does not support specifying object attributes; The second method requires us to modify the code. If an interface parameter does not inherit ParamFlowArgument after going online and wants to configure hotspot parameter current limiting, it can only be solved by changing the code version. Therefore, we have optimized the current limiting source code of the hotspot parameter of sentinel component, added "a property of the specified parameter object" as the hotspot parameter, and supported object level nesting. Small code changes greatly facilitate the configuration of hotspot parameters.
Hot spot parameter verification logic after transformation;
public static boolean passCheck(ResourceWrapper resourceWrapper, /*@Valid*/ ParamFlowRule rule, /*@Valid*/ int count,
Object... args) {
// Ignore partial code
// Get parameter value. If value is null, then pass.
Object value = args[paramIdx];
if (value == null) {
return true;
}
// Assign value with the result of paramFlowKey method
if (value instanceof ParamFlowArgument) {
value = ((ParamFlowArgument) value).paramFlowKey();
}else{
// Obtain the hotspot parameter value according to the hotspot parameter specified by classFieldName
if (StringUtil.isNotBlank(rule.getClassFieldName())){
// Gets the value of the classFieldName property in the reflection parameter object
value = getParamFieldValue(value, rule.getClassFieldName());
}
}
// Ignore partial code
}
3, MongoDB data isolation
Why data isolation? There are two reasons for this. First, the middle desk stores the data of different businesses at the front desk. During data query, the business data cannot affect each other, and the data of business B cannot be queried from business A. Second point: the data magnitude of each business is different and the pressure on db operation is different. For example, in traffic isolation, we provide A separate set of service clusters for browser business, so the db used by browser business also needs to be configured separately, so as to be completely isolated from the service pressure of other businesses.
In vivo comments, mongodb is used as the storage medium (for details of database selection and mongodb application, interested students can see our previous introduction< MongoDB's practice in comment Center >), in order to isolate the data of different business parties, the comment center provides two data isolation schemes: physical isolation and logical isolation.
3.1 physical isolation
The data of different business parties are stored in different database clusters, which requires our system to support multiple data sources of MongoDB. The implementation process is as follows:
1) Find the right entry point
By analyzing the source code of the execution process of spring data mongodb, it is found that before executing all statements, we will do an action of getDB() to obtain the database connection instance, as follows.
Spring data mongodb operation source code;
private <T> T executeFindOneInternal(CollectionCallback<DBObject> collectionCallback,
DbObjectCallback<T> objectCallback, String collectionName) {
try {
//Key code getDb()
T result = objectCallback
.doWith(collectionCallback.doInCollection(getAndPrepareCollection(getDb(), collectionName)));
return result;
} catch (RuntimeException e) {
throw potentiallyConvertRuntimeException(e, exceptionTranslator);
}
}
getDB() will execute org springframework. data. MongoDB. The getDB() method of MongoDbFactory interface is implemented by SimpleMongoDbFactory of MongoDbFactory by default. Seeing here, we can naturally think of using "proxy mode", replacing SimpleMongoDbFactory with SimpleMongoDbFactory proxy object, and creating a SimpleMongoDbFactory instance for each MongoDB set within the proxy object.
When executing db operation, execute getDb() operation of proxy object, which only needs to do two things;
-
Find the SimpleMongoDbFactory object of the corresponding cluster
-
Execute simplemongodbfactory Getdb() operation.
The class diagram is as follows.
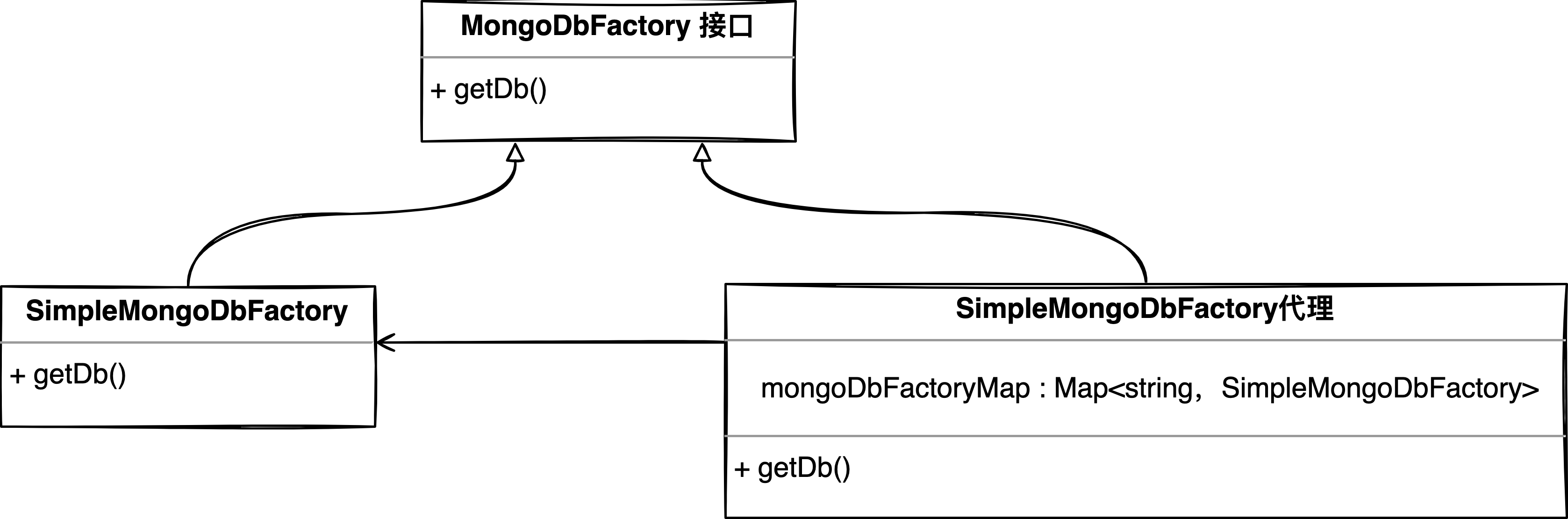
The overall implementation process is as follows:
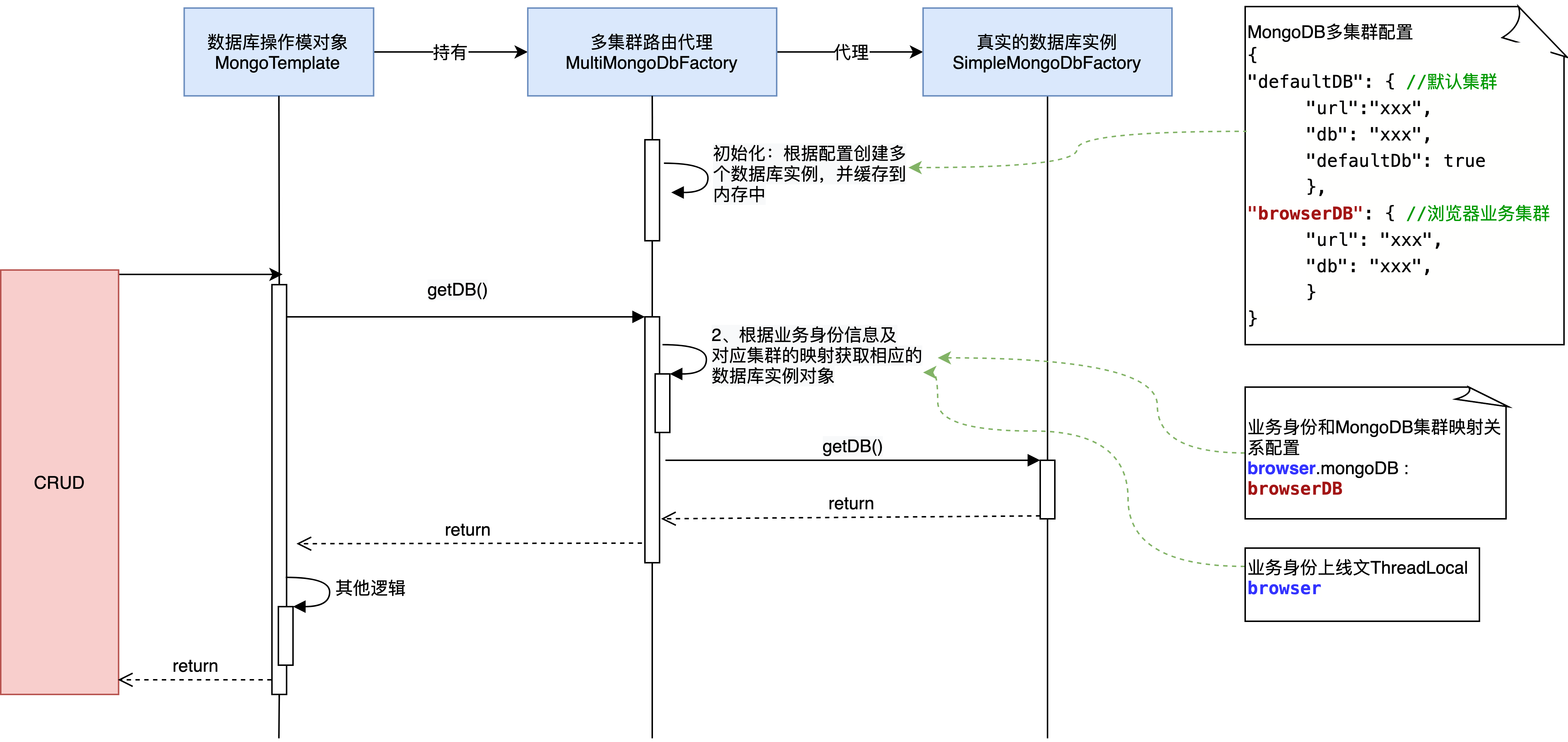
3.1.2 core code implementation
Obtain and set the service context to Dubbo;
private boolean setCustomerCode(Object argument) {
// Obtain business identity information from string type parameters
if (argument instanceof String) {
if (!Pattern.matches("client.*", (String) argument)) {
return false;
}
// Set business identity information into context
CustomerThreadLocalUtil.setCustomerCode((String) argument);
return true;
} else {
// Get parameter object from list type
if (argument instanceof List) {
List<?> listArg = (List<?>) argument;
if (CollectionUtils.isEmpty(listArg)) {
return false;
}
argument = ((List<?>) argument).get(0);
}
// Obtain business identity information from object object
try {
Method method = argument.getClass().getMethod(GET_CLIENT_CODE_METHOD);
Object object = method.invoke(argument);
// Verify whether the business identity is legal
ClientParamCheckService clientParamCheckService = ApplicationUtil.getBean(ClientParamCheckService.class);
clientParamCheckService.checkClientValid(String.valueOf(object));
// Set business identity information into context
CustomerThreadLocalUtil.setCustomerCode((String) object);
return true;
} catch (NoSuchMethodException | IllegalAccessException | InvocationTargetException e) {
log.debug("Reflection acquisition clientCode Failed, input parameters are:{}", argument.getClass().getName(), e);
return false;
}
}
}
Routing agent class of MongoDB cluster;
public class MultiMongoDbFactory extends SimpleMongoDbFactory {
// Database instance cache of different clusters: key is the configuration name of MongoDB cluster, and value is the MongoDB cluster instance of the corresponding business
private final Map<String, SimpleMongoDbFactory> mongoDbFactoryMap = new ConcurrentHashMap<>();
// Add the created MongoDB cluster instance
public void addDb(String dbKey, SimpleMongoDbFactory mongoDbFactory) {
mongoDbFactoryMap.put(dbKey, mongoDbFactory);
}
@Override
public DB getDb() throws DataAccessException {
// Get foreground business code from context
String customerCode = CustomerThreadLocalUtil.getCustomerCode();
// Get the MongoDB configuration name corresponding to the service
String dbKey = VivoConfigManager.get(ConfigKeyConstants.USER_DB_KEY_PREFIX + customerCode);
// Get the corresponding SimpleMongoDbFactory instance from the connection cache
if (dbKey != null && mongoDbFactoryMap.get(dbKey) != null) {
// Execute simplemongodbfactory Getdb() operation
return mongoDbFactoryMap.get(dbKey).getDb();
}
return super.getDb();
}
}
Customize MongoDB operation template;
@Bean
public MongoTemplate createIgnoreClass() {
// Generate MultiMongoDbFactory proxy
MultiMongoDbFactory multiMongoDbFactory = multiMongoDbFactory();
if (multiMongoDbFactory == null) {
return null;
}
MappingMongoConverter converter = new MappingMongoConverter(new DefaultDbRefResolver(multiMongoDbFactory), new MongoMappingContext());
converter.setTypeMapper(new DefaultMongoTypeMapper(null));
// Generate MongoDB operation template using multiMongoDbFactory agent
return new MongoTemplate(multiMongoDbFactory, converter);
}
3.2 logical isolation
Physical isolation is the most thorough data isolation, but it is impossible for us to build an independent MongoDB cluster for every business. When multiple businesses share a database, the logical isolation of data is required.
Logical isolation is generally divided into two types:
-
One is table isolation: the data of different business parties are stored in different tables in the same database, and different business operations have different data tables.
-
One is row isolation: the data of different business parties are stored in the same table with redundant business party codes. When reading data, the purpose of isolating data is realized through business code filtering conditions.
Considering the implementation cost and commenting on business scenarios, we chose table isolation. The implementation process is as follows:
1) Initialize data table
Every time there is a new business connection, we will assign a unique identity code to the business. We directly use the identity code as the suffix of the business table name and initialize the table, such as mall comment_info_community comment vs hop_ info_ community.
2) Automatic look-up table
Directly use the spring data mongodb @ document annotation to support Spel's ability, combined with our business identity information context, to realize automatic table lookup.
Automatic look-up table
@Document(collection = "comment_info_#{T(com.vivo.internet.comment.common.utils.CustomerThreadLocalUtil).getCustomerCode()}")
public class Comment {
// Table fields ignored
}
The overall effect of the combination of the two isolation methods:
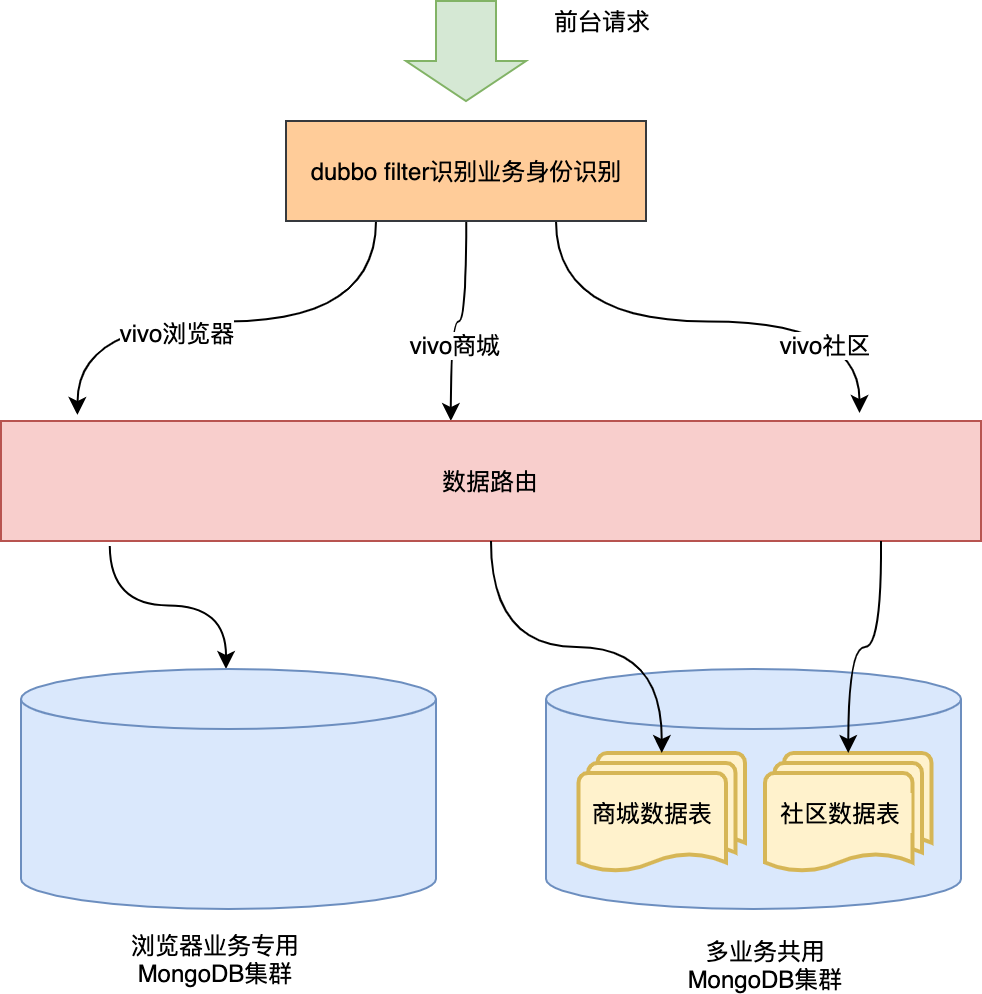
4, Finally
Through the above practices, we have well supported different levels of foreground business, achieved no invasion of business code, and better decoupled the complexity between technology and business. In addition, we have isolated the Redis cluster and ES cluster used in the project from different businesses. The general idea is similar to the isolation of MongoDB. They are all used as one-tier agents, which will not be introduced here.
Author: vivo official website mall development team - Sun Daoming