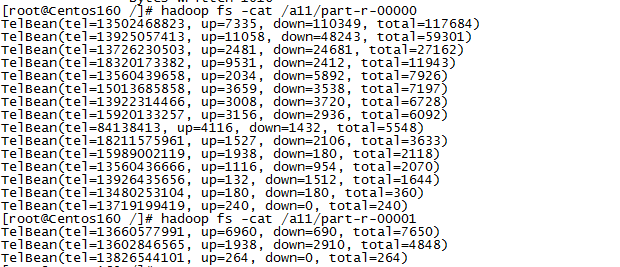
Traffic statistics of MapReduce
means of preparation
- A virtual machine with hadoop installed
- An online traffic data
Open hadoop
start-all.sh
Upload flow.log file
hadoop fs -put /flow.log /
pojo level
import lombok.Data; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //Writable is a class that can be serialized and deserialized @Data public class TelBean implements Writable { private String tel; private Long up; private Long down; private Long total; public TelBean() { } public TelBean(String tel, Long up, Long down) { this.tel = tel; this.up = up; this.down = down; this.total = up + down; } //serialize public void write(DataOutput out) throws IOException { out.writeUTF(tel); out.writeLong(up); out.writeLong(down); out.writeLong(total); } //De serialization public void readFields(DataInput in) throws IOException { this.tel = in.readUTF(); this.up = in.readLong(); this.down = in.readLong(); this.total = in.readLong(); } }
mapper level
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class TCMapper extends Mapper<LongWritable, Text,Text,TelBean> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split("\t");//Each column is tab separated String tel = split[1]; Long up = Long.parseLong(split[split.length - 3]); Long down = Long.parseLong(split[split.length - 2]); TelBean telBean = new TelBean(tel, up, down); context.write(new Text(tel),telBean); } }
reducer level
import com.zhiyou100.pojo.TelBean; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class TCReducer extends Reducer<Text, TelBean,Text,TelBean> { @Override protected void reduce(Text key, Iterable<TelBean> values, Context context) throws IOException, InterruptedException { Long up = 0L; Long down = 0L; for (TelBean telBean:values) { up = up + telBean.getUp(); down = down + telBean.getDown(); } TelBean telBean = new TelBean(key.toString(),up,down); context.write(key,telBean); } }
partition layer
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; //Parameters: these two parameters are the parameters output by reducer public class MyPartition extends Partitioner<Text, TelBean> { @Override public int getPartition(Text text, TelBean telBean, int numPartitions) { String tel = text.toString(); if(tel.startsWith("138")||tel.startsWith("136")){ return 1; }else{ return 0; } } }
job level
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TCJob { public static void main(String[] args) throws Exception { Configuration conf=new Configuration(); Job job=Job.getInstance(conf); //2. Specify the class used by the job job.setJarByClass(TCJob.class); //3. Set the mapper's class and properties job.setMapperClass(TCMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TelBean.class); //4. Set the class and property of reducer job.setReducerClass(TCReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(TelBean.class); //Set partition job.setPartitionerClass(MyPartition.class); job.setNumReduceTasks(2); //5. Set dynamic transfer parameters of input file when calling FileInputFormat.setInputPaths(job, new Path(args[0])); //6. Set output directory FileOutputFormat.setOutputPath(job, new Path(args[1])); //7. Submit task job.waitForCompletion(true); } }
Package it into jar package and upload it to the server
hadoop jar hdfs1-1.0-SNAPSHOT.jar com.zhiyou100.job.TCJob /flow.log /a3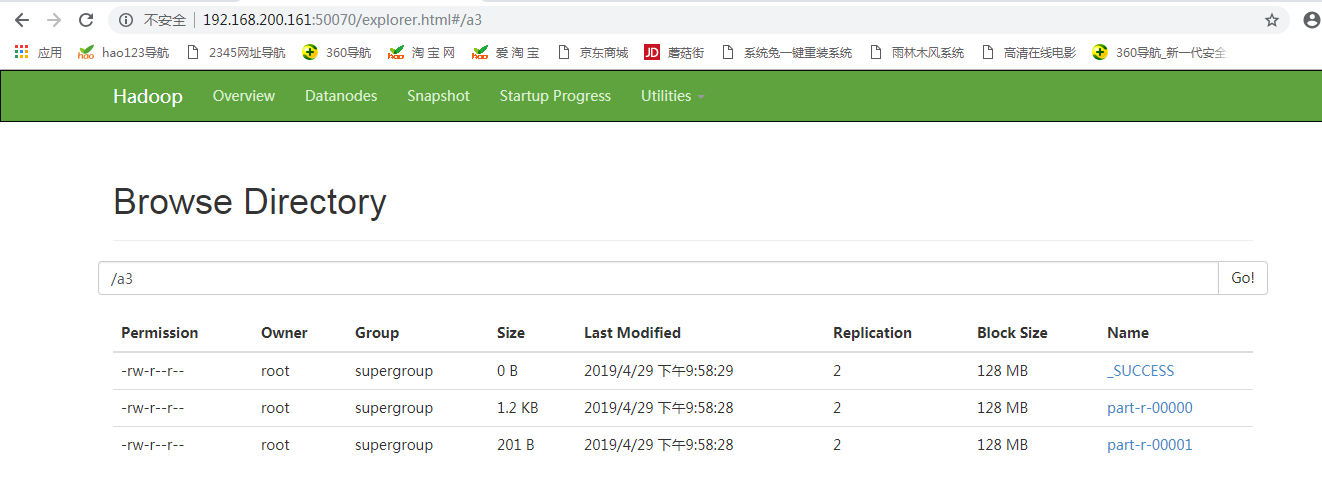
Check the contents of two documents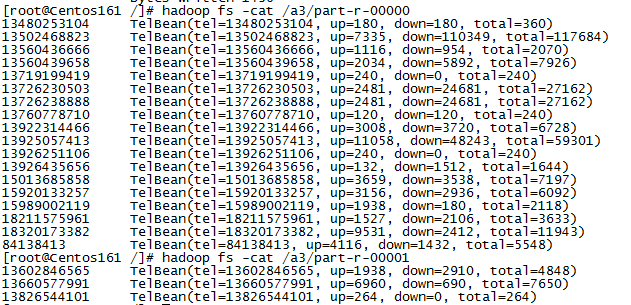
summary
mapper layer: it is responsible for cleaning the incoming data and converting it to the format of key value pairs that we need to process
reducer layer: responsible for data processing
job layer: responsible for controlling the execution sequence of the whole project code
Note: both sorting and partitioning operate on key
Sort by total flow
First, query the total uplink, downlink and total traffic without partition, and then sort the generated results
pojo level
Revised as follows
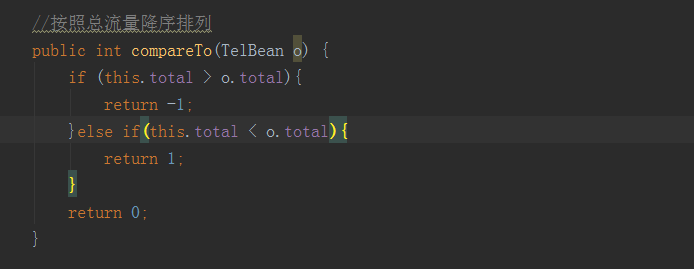
mapper level
Revised as follows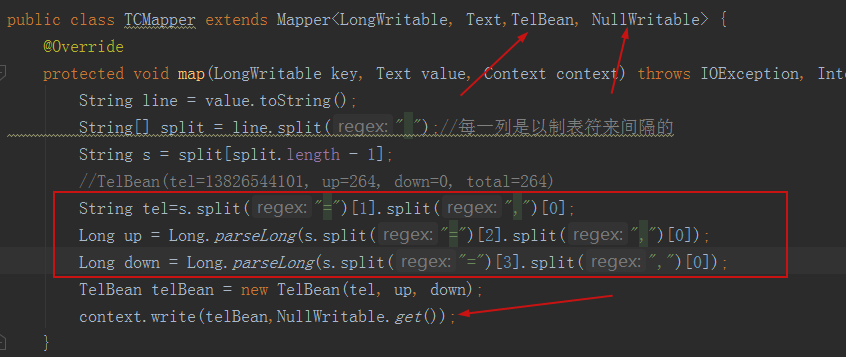
reducer level

Zoning layer
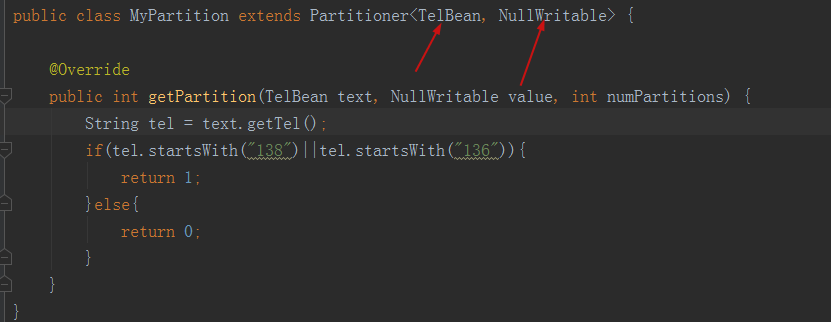
job level
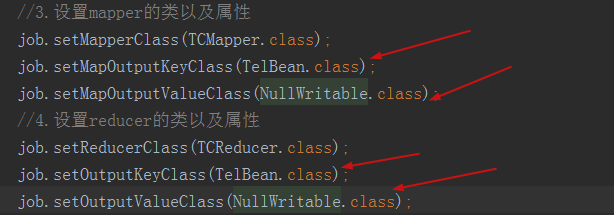
Operation result: