Train a NER marker from scratch
The Chinese name of NER tagging is named entity recognition. Like part of speech tagging, it is one of the technical foundations of natural language processing. Ner annotation refers to the identification of the name of an object in the real world, such as France, Donald Trump or wechat. Among these words, France is a country, identified as GPE (GEO remediation entity), Donald Trump as PER (person's name), and wechat is a company, so it is identified as ORG (Organization).
Common entity types in the spaCy module are:
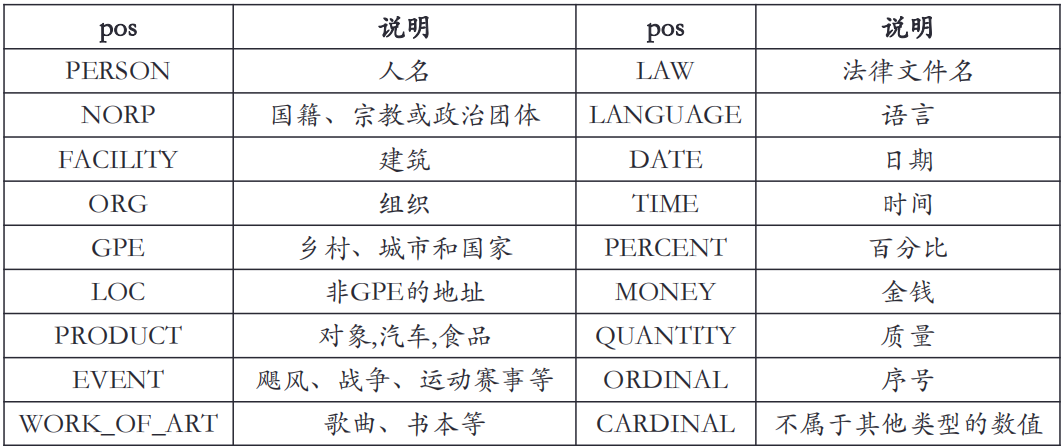
Function of NER label:
1) Obviously, the most important thing is that the entities needed in the text can be recognized through the model.
2) The relationship between entities can be deduced; For example, Rome is the capital of Italy. According to entity recognition, it can be judged that Rome is an Italian city rather than an R & b artist. This work is called entity disambiguation (NED);
The use scenario of NED can eliminate word ambiguity, identify genes and gene products, and analyze writing style in medical research.
Next, start sparcy training NER marker.
Note: This article is implemented using spaCy 3.0 code.
1, Custom model
1. Import the required packages and modules
from __future__ import unicode_literals, print_function import plac import random from pathlib import Path import spacy from spacy.training import Example from spacy.tokens import Doc
2. The basic database and training samples used are imported
The index of entity annotation starts from 0, and 17 is the index of the last character + 1. The index refers to the python index method
# training data
TRAIN_DATA = [
('Who is Shaka Khan?', {
'entities': [(7, 17, 'PERSON')]
}),
('I like London and Berlin.', {
'entities': [(7, 13, 'LOC'), (18, 24, 'LOC')]
})
]
Although the number of training samples in the example is small, it is representative.
2, Training model
1. Optimize the existing model
if model is not None:
nlp = spacy.load(model) # Load existing models
print("Loaded model '%s'" % model)
else:
nlp = spacy.blank('en') # Create a blank model
print("Created blank 'en' model")
2. Create built-in pipe components
Using add_pipeline function creates pipeline
if 'ner' not in nlp.pipe_names:
ner = nlp.create_pipe('ner')
nlp.add_pipe('ner', last=True)
else:
ner = nlp.get_pipe('ner')
3. Add the label of train data
for _, annotations in TRAIN_DATA:
for ent in annotations.get('entities'):
ner.add_label(ent[2])
4. Build model
The training process itself is very simple, NLP The update () method abstracts everything for us, and spaCy handles the actual machine learning and training process.
# Disable all other components in the pipeline so that only the NER annotator is trained / updated
other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'ner']
with nlp.disable_pipes(*other_pipes): # Only the labels we marked will be trained. If not, all labels will be trained,
for itn in range(n_iter):
random.shuffle(TRAIN_DATA) # Each iteration of training data disrupts the sequence
losses = {} # Define loss function
for text, annotations in TRAIN_DATA:
# Organize the data into the data required by the new model
example = Example.from_dict(nlp.make_doc(text), annotations)
print("example:",example)
nlp.update(
[example], # Annotation
drop=0.5,
sgd=optimizer, # Update weight
losses=losses)
print(losses)
5. Model saving
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
Three. Model test
def load_model_test(path,text):
nlp = spacy.load(path)
print("Loading from", path)
doc = nlp(text)
for i in doc.ents:
print(i.text,i.label_)
if __name__ == "__main__":
path = "./model/"
text = "Who is Shaka Khan"
load_model_test(path,text)
The effect of the model is as follows
Loading from ./model/ Shaka Khan PERSON
You can go to Shaka Khan and label it as PERSON, that is, PERSON name.
reference resources
Bagoff Srinivasa desikan Natural language processing and computational linguistics People's Posts and Telecommunications Publishing House