Training a part of speech tagging model from scratch
The full name of part of speech tagging is part of speech tagging. As the name suggests, part of speech tagging is for the words in the input text
The process of marking the corresponding part of speech.
spaCy part of speech tagging model is a statistical model, which is different from the rule-based checking process of checking whether a word belongs to a stop word. The characteristic of statistics plus prediction means that we can train a model ourselves in order to obtain better prediction results, and the new prediction process is more relevant to the data set used. The so-called better is not necessarily the optimization at the digital level, because the general part of speech tagging accuracy of the current spaCy model has reached 97%.
In order to make the prediction results more accurate, the weight needs to be optimized in a specific direction, that is, increase or decrease. The training process of spaCy part of speech tagger is shown in the figure.

Next, start spaCy training custom model.
Note: This article is implemented with spaCy 3.0 code.
Custom model
1, Import required packages and modules
from __future__ import unicode_literals, print_function import plac import random from pathlib import Path import spacy from spacy.training import Example from spacy.tokens import Doc
2, Custom part of speech
The word object in spaCy contains a tag_ Attributes, the following are the 19 main parts of speech and introduction in spaCy.
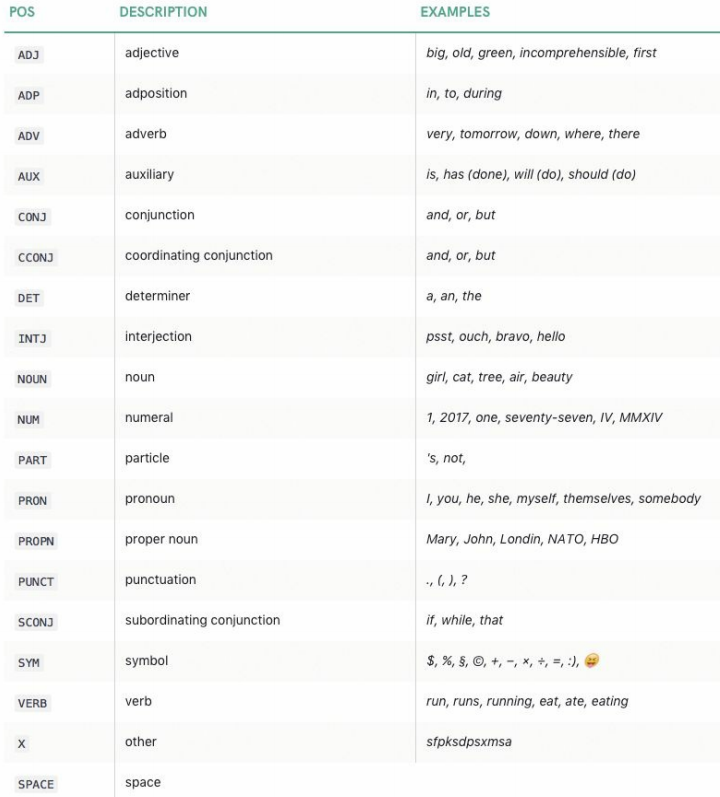
Imported and initialized TAG_MAP dictionary
TAG_MAP = {
'noun': {'pos': 'NOUN'},
'verb': {'pos': 'VERB'},
'adjective': {'pos': 'ADJ'},
'Judgment word': {'pos': 'AUX'},
'numeral': {'pos': 'NUM'},
'classifier': {'pos': 'DET'},
'pronoun': {'pos': 'PRON'},
'adverb': {'pos': 'ADV'},
'auxiliary word': {'pos': 'PART'}
}
3, Part of speech tagging
Map the custom part of speech name to the general part of speech tagging set,
# training sample
TRAIN_DATA = [
('Your own text', {'tags': ['pronoun', 'verb', 'numeral', 'classifier', 'noun', 'noun']}),
('Your own text', {'tags': ['pronoun', 'verb', 'numeral', 'classifier', 'noun', 'noun']})
]
The training set can play freely. The more data, the better the training effect of the model.
Training model
I. annotation of model parameters (language, output directory and number of training iterations)
@plac.annotations(
lang=("ISO Code of language to use", "option", "l", str),
output_dir=("Optional output directory", "option", "o", Path),
n_iter=("Number of training iterations", "option", "n", int))
2, Create a blank language model
Use add_ The pipeline function creates a pipeline and adds a callout to it
def main(lang='zh', output_dir=None, n_iter=25):
nlp = spacy.blank(lang) # Create an empty Chinese model
tagger = nlp.add_pipe('tagger') # Create pipeline
# Add callout
for tag, values in TAG_MAP.items():
#print("tag:",tag)
#print("values:",values)
tagger.add_label(tag)
print("3:",tagger)
optimizer = nlp.begin_training() # Model initialization
for i in range(n_iter):
random.shuffle(TRAIN_DATA) # Disrupt list
losses = {}
for text, annotations in TRAIN_DATA:
example = Example.from_dict(Doc(nlp.vocab, words=text, spaces=[""] * len(text)), annotations)
nlp.update([example], sgd=optimizer, losses=losses)
print(losses)
3, Put into test set
test_text = "Your own text"
doc = nlp(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
4, Save model and test model
if output_dir is not None:
output_dir = Path(output_dir)
if not output_dir.exists():
output_dir.mkdir()
nlp.to_disk(output_dir)
print("Saved model to", output_dir)
# Test save model
print("Loading from", output_dir)
nlp2 = spacy.load(output_dir)
doc = nlp2(test_text)
print('Tags', [(t.text, t.tag_, TAG_MAP[t.tag_]['pos']) for t in doc])
The effect of the model is as follows
# I like apples
Tags [('I', 'pronoun', 'PRON'), ('happiness', 'verb', 'VERB'), ('Joyous', 'verb', 'VERB'), ('eat', 'verb', 'VERB'), ('Apple', 'noun', 'NOUN'), ('fruit', 'noun', 'NOUN')]
Deficiencies
It can be seen from the effect that the model has marked the part of speech of each word, but the whole word cannot be marked. We will continue to try in the future.
reference resources
1. [method] bagoff Srinivasa desikan, natural language processing and computational linguistics, people's Posts and Telecommunications Press