TVM: a quick tutorial for compiling a deep learning model
This article will show how to use the Relay python front end to build a neural network and use TVM to generate a runtime library for Nvidia GPU. Note that cuda and llvm are enabled when we need to rebuild TVM.
Overview of hardware backend supported by TVM
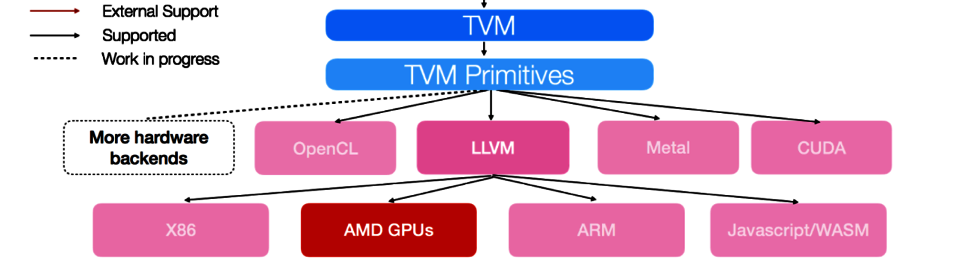
In this tutorial, we use cuda and llvm as the target backend. Let's import Relay and TVM first:
import numpy as np from tvm import relay from tvm.relay import testing import tvm from tvm import te from tvm.contrib import graph_executor import tvm.testing
Using Relay to define a neural network
First, we define a neural network using the python front end of relay. For simplicity, we directly use the predefined resnet-18 network in relay. Parameters are initialized according to Xavier initialization. Relay also supports other model formats such as MXNet, CoreML, ONNX and TensorFlow.
In this tutorial, we assume that we will reason on our own device, and the batch size is set to 1. The input is an RGB color image with a size of 224 * 224. We can call TVM relay. expr. TupleWrapper. Astext() to view the network structure,
batch_size = 1
num_class = 1000
image_shape = (3, 224, 224)
data_shape = (batch_size,) + image_shape
out_shape = (batch_size, num_class)
mod, params = relay.testing.resnet.get_workload(
num_layers=18, batch_size=batch_size, image_shape=image_shape
)
# set show_meta_data=True if you want to show meta data
print(mod.astext(show_meta_data=False))
Output:
#[version = "0.0.5"] def @main(%data: Tensor[(1, 3, 224, 224), float32], %bn_data_gamma: Tensor[(3), float32], %bn_data_beta: Tensor[(3), float32], %bn_data_moving_mean: Tensor[(3), float32], %bn_data_moving_var: Tensor[(3), float32], %conv0_weight: Tensor[(64, 3, 7, 7), float32], %bn0_gamma: Tensor[(64), float32], %bn0_beta: Tensor[(64), float32], %bn0_moving_mean: ... Tensor[(64), float32], %bn0_moving_var: Tensor[(64), float32], %stage1_unit1_bn1_gamma: %88 = nn.dense(%87, %fc1_weight, units=1000) /* ty=Tensor[(1, 1000), float32] */; %89 = nn.bias_add(%88, %fc1_bias, axis=-1) /* ty=Tensor[(1, 1000), float32] */; nn.softmax(%89) /* ty=Tensor[(1, 1000), float32] */ }
compile
The next step is to compile using the Relay/TVM process. You can specify the optimization level of compilation. At present, the optimization level can be set to 0 to 3. The optimized pass includes operator fusion, pre calculation, layout transformation and so on.
relay.build() returns three components: the execution diagram in json format, the TVM module library specially compiled for this diagram on the target hardware, and the parameter blob of the model. In the compilation process, Relay performs graph level optimization and TVM performs sheet level optimization, so as to provide optimized runtime module for model reasoning service.
We will first compile for Nvidia GPU. relay.build() first performs some graph level optimization behind the scenes, such as pruning, fusion, etc., and then registers the operator (i.e. the node of the optimization graph) to the TVM implementation to generate TVM module. In order to generate the module library, TVM will first convert the high-level IR into the low-level inherent IR of the specified target backend, in this case CUDA. Then generate the machine code to get the module library.
opt_level = 3
target = tvm.target.cuda()
with tvm.transform.PassContext(opt_level=opt_level):
lib = relay.build(mod, target, params=params)
Output:
/home/areusch/ws/tvm3/python/tvm/target/target.py:259: UserWarning: Try specifying cuda arch by adding 'arch=sm_xx' to your target.
warnings.warn("Try specifying cuda arch by adding 'arch=sm_xx' to your target.")
Run the generated library
Now we can create a graph executor to run the module on the Nvidia GPU.
# create random input
dev = tvm.cuda()
data = np.random.uniform(-1, 1, size=data_shape).astype("float32")
# create module
module = graph_executor.GraphModule(lib["default"](dev))
# set input and parameters
module.set_input("data", data)
# run
module.run()
# get output
out = module.get_output(0, tvm.nd.empty(out_shape)).numpy()
# Print first 10 elements of output
print(out.flatten()[0:10])
Output:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737 0.00106262 0.00095838 0.00110792 0.00113151]
Save / load compiled modules
We can save graph, lib and parameters to a file and load them in the deployment scenario. (Note: the code here will save the model in a temporary file. If you want to save the model, you can modify the path yourself)
# save the graph, lib and params into separate files
from tvm.contrib import utils
temp = utils.tempdir()
path_lib = temp.relpath("deploy_lib.tar")
lib.export_library(path_lib)
print(temp.listdir())
Output:
['deploy_lib.tar']
# load the module back. loaded_lib = tvm.runtime.load_module(path_lib) input_data = tvm.nd.array(data) module = graph_executor.GraphModule(loaded_lib["default"](dev)) module.run(data=input_data) out_deploy = module.get_output(0).numpy() # Print first 10 elements of output print(out_deploy.flatten()[0:10]) # check whether the output from deployed module is consistent with original one tvm.testing.assert_allclose(out_deploy, out, atol=1e-5)
Output:
[0.00089283 0.00103331 0.0009094 0.00102275 0.00108751 0.00106737 0.00106262 0.00095838 0.00110792 0.00113151]