This article is the last article (TVM development code learning) add a new operator to the Relay system - Zhihu (zhihu.com) It is mainly to be familiar with the Relay operator code from six parts and deconstruct the Relay operator in TVM from the perspective of adding an operator.
Reviewing the previous section, the following points are required to add operators to Relay in TVM:
-
The definition in the src file is a structure inherited from AttrsNode, which contains the general attribute parameters of the operator. include/tvm/relay/attrs/
-
type relation function src/relay/op in src folder/
-
Attribute information of registration operator src/relay/op/
-
python side calculation definition python/tvm/topi/
-
python side calculation + scheduling packaging function python/tvm/relay/op/strategy/
-
Create a CallNode instance of the operator in the SRC folder and register it. src/relay/op/
-
Python side of the concise API to achieve the final function. python/tvm/relay/op
Note that in the following, because steps 3 and 6 are for registering certain classes, I will combine these two steps together (to be honest, I don't quite understand the meaning of dividing these steps into two steps in the official guidelines. They are generally in a cc file, and the functions are similar. Maybe it's to make the narrative logic smooth?). 6 is for the registration of CallNode class, which can be registered globally by creating a CallNode instance of operator, while 3 is for the registration of AttrsNode created in step 1 and type relation ship created in step 2,
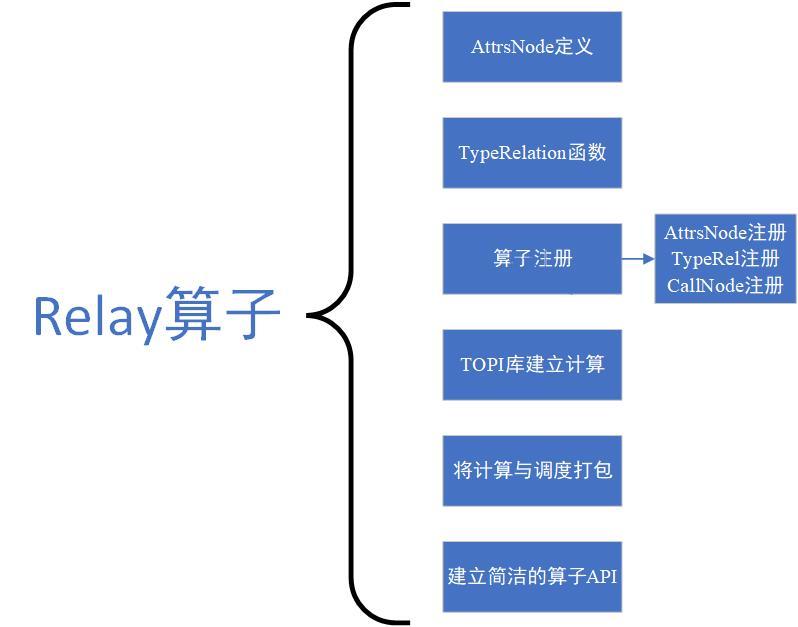
Therefore, the Relay operator code in TVM is divided into the following six parts:
1. A structure inherited from AttrsNode, containing the general attribute parameters of the operator. include/tvm/relay/attrs/
2. type relation function src/relay/op in src folder/
3. Register the attribute information AttrsNode, type relationship of the operator, and create and register a CallNode. src/relay/op/
4. python side calculation definition python/tvm/topi/
5. python side calculation + scheduling packaging function python/tvm/relay/op/strategy/
6. Python side of the concise API to achieve the final function. python/tvm/relay/op
Draw a picture to make it clearer:
In order to be more familiar with its process, today we'll take a look at the code of Softmax operator and Conv1d operator.
Sofrmax operator:
1.AttrsNode
/*! \brief Attributes used in softmax operators */
struct SoftmaxAttrs : public tvm::AttrsNode<SoftmaxAttrs> {
int axis;
TVM_DECLARE_ATTRS(SoftmaxAttrs, "relay.attrs.SoftmaxAttrs") {
TVM_ATTR_FIELD(axis).set_default(-1).describe("The axis to sum over when computing softmax.");
}
};The source code is located in include \ TVM \ relay \ attrs \ NN h
The attribute of Softmax operator only needs an axis.
2.type relation function
Softmax's type relation function is very simple. After all, the operator itself is simple. Instead of defining a type relation belonging to softmax, it uses IdentityRel() and many operators (relu, fast_softmax, l2_normalize, etc.) to share this type association function. The input and output types and shapes of these operators are the same.
The source code is located in \ src\relay\op\type_relations.cc
bool IdentityRel(const Array<Type>& types, int num_inputs, const Attrs& attrs,
const TypeReporter& reporter) {
for (size_t i = 1; i < types.size(); ++i) {
reporter->Assign(types[i], types[0]);
}
return true;
}3.AttrsNode registration, Type Relation registration and CallNode registration
Registered TVM for AttrsNode_ REGISTER_ NODE_ TYPE
Register for operator type relation_ REGISTER_ OP
The source code is located at \ SRC \ relay \ op \ NN \ NN cc
TVM_REGISTER_NODE_TYPE(SoftmaxAttrs);
RELAY_REGISTER_OP("nn.softmax")
.describe(R"code(Softmax layer.
.. math:: \text{softmax}(x)_i = \frac{exp(x_i)}{\sum_j exp(x_j)}
.. note::
This operator can be optimized away for inference.
- **data**: The input data
)code" TVM_ADD_FILELINE)
.set_attrs_type<SoftmaxAttrs>()
.set_num_inputs(1)
.add_argument("data", "Tensor", "The input tensor.")
.set_support_level(1)
.add_type_rel("Identity", IdentityRel);Then, create a CallNode object and use the registration macro TVM_REGISTER_GLOBAL registration.
TVM_REGISTER_GLOBAL("relay.op.nn._make.softmax").set_body_typed([](Expr data, int axis) {
auto attrs = make_object<SoftmaxAttrs>();
attrs->axis = axis;
static const Op& op = Op::Get("nn.softmax");
return Call(op, {data}, Attrs(attrs), {});
});Unlike the previous section, it also wrote a makesum function to return callnode. Here, because softmax is simple, it directly puts callnode creation and macro registration together.
4. Define specific calculations in the topi library on the python side
The source code is in \ Python \ TVM \ topi \ NN \ softmax Py, which is perhaps the most difficult step in the definition of TVM operator, involving the design of its tensor expression.
def softmax_common(x, axis, use_fast_exp):
"""The common part of softmax and fast_softmax"""
shape = x.shape
if axis < 0:
axis = len(shape) + axis
if axis >= len(shape):
ValueError("axis parameter should be less than input dim")
k1 = te.reduce_axis((0, shape[axis]), name="k")
k2 = te.reduce_axis((0, shape[axis]), name="k")
def insert_reduce_index(indices, reduce_index):
return indices[:axis] + (reduce_index,) + indices[axis:]
def get_non_reduce_indices(indices):
return tuple([var for (i, var) in enumerate(indices) if i != axis])
def _compute_max(*indices):
eval_range = insert_reduce_index(indices, k1)
return tvm.te.max(x[eval_range], axis=k1)
def _compute_delta(max_elem, *indices):
non_reduce_indices = get_non_reduce_indices(indices)
return x[indices] - max_elem[non_reduce_indices]
def _compute_exp(max_elem, *indices):
non_reduce_indices = get_non_reduce_indices(indices)
return te.exp(x[indices] - max_elem[non_reduce_indices])
def _compute_expsum(exp, *indices):
eval_range = insert_reduce_index(indices, k2)
return te.sum(exp[eval_range], axis=k2)
def _normalize(exp, expsum, *indices):
non_reduce_indices = get_non_reduce_indices(indices)
return exp[indices] / expsum[non_reduce_indices]
reduced_shape = tuple([dim for (i, dim) in enumerate(shape) if i != axis])
max_elem = te.compute(reduced_shape, _compute_max, name="T_softmax_maxelem")
if use_fast_exp:
delta = te.compute(
shape, lambda *indices: _compute_delta(max_elem, *indices), name="T_softmax_delta"
)
exp = topi.math.fast_exp(delta)
else:
exp = te.compute(
shape, lambda *indices: _compute_exp(max_elem, *indices), name="T_softmax_exp"
)
expsum = te.compute(
reduced_shape, lambda *indices: _compute_expsum(exp, *indices), name="T_softmax_expsum"
)
return te.compute(
shape,
lambda *indices: _normalize(exp, expsum, *indices),
name="T_softmax_norm",
attrs={"axis": axis},
)5. Packaging calculation and scheduling
The source code is in \ Python \ TVM \ relay \ op \ strategy \ generic Py, you can see that its process is basically the same as that described in the previous section
def wrap_compute_softmax(topi_compute):
"""Wrap softmax topi compute"""
def _compute_softmax(attrs, inputs, out_type):
axis = attrs.get_int("axis")
return [topi_compute(inputs[0], axis)]
return _compute_softmax
@override_native_generic_func("softmax_strategy")
def softmax_strategy(attrs, inputs, out_type, target):
"""softmax generic strategy"""
strategy = _op.OpStrategy()
strategy.add_implementation(
wrap_compute_softmax(topi.nn.softmax),
wrap_topi_schedule(topi.generic.schedule_softmax),
name="softmax.generic",
)
return strategy6. Final packing
\python\tvm\relay\op\nn\nn.py
def softmax(data, axis=-1):
r"""Computes softmax.
.. math:: \text{softmax}(x)_i = \frac{exp(x_i)}{\sum_j exp(x_j)}
.. note::
This operator can be optimized away for inference.
Parameters
----------
data: tvm.relay.Expr
The input data to the operator.
axis: int, optional
The axis to sum over when computing softmax
Returns
-------
result : tvm.relay.Expr
The computed result.
"""
return _make.softmax(data, axis)One dimensional convolution operator Conv1d
1.AttrsNode
/*! \brief Attributes used in 1D convolution operators */
struct Conv1DAttrs : public tvm::AttrsNode<Conv1DAttrs> {
Array<IndexExpr> strides;
Array<IndexExpr> padding;
Array<IndexExpr> dilation;
int groups;
IndexExpr channels;
Array<IndexExpr> kernel_size;
std::string data_layout;
std::string kernel_layout;
std::string out_layout;
DataType out_dtype;
TVM_DECLARE_ATTRS(Conv1DAttrs, "relay.attrs.Conv1DAttrs") {
TVM_ATTR_FIELD(strides)
.set_default(Array<IndexExpr>({
1,
}))
.describe("Specifies the stride of the convolution.");
TVM_ATTR_FIELD(padding)
.set_default(Array<IndexExpr>({0, 0}))
.describe(
"If padding is non-zero, then the input is implicitly zero-padded"
"on both sides for padding number of points");
TVM_ATTR_FIELD(dilation)
.set_default(Array<IndexExpr>({
1,
}))
.describe("Specifies the dilation rate to use for dilated convolution.");
TVM_ATTR_FIELD(groups).set_default(1).describe(
"Currently unused but may be added in the future.");
TVM_ATTR_FIELD(channels)
.describe(
"The number of output channels in the convolution."
" If it is not set, inferred by shape of the weight.")
.set_default(NullValue<IndexExpr>());
TVM_ATTR_FIELD(kernel_size)
.describe("Specifies the dimensions of the convolution window.")
.set_default(NullValue<Array<IndexExpr>>());
TVM_ATTR_FIELD(data_layout)
.set_default("NCW")
.describe(
"Dimension ordering of input data. Can be 'NCW', 'NWC', etc."
"'N', 'C', 'W' stands for batch, channel, and width"
"dimensions respectively. Convolution is applied on the 'W'"
"dimension.");
TVM_ATTR_FIELD(kernel_layout)
.set_default("OIW")
.describe(
"Dimension ordering of weight. Can be 'OIW', or 'WIO', etc."
"'O', 'I', 'W' stands for num_filter, input_channel, and width"
"dimensions respectively.");
// use 0 bits to indicate none.
TVM_ATTR_FIELD(out_dtype)
.set_default(NullValue<DataType>())
.describe("Output data type, set to explicit type under mixed precision setting");
}
};2.type relation function
The source code is in \ SRC \ relay \ op \ NN \ revolution h. The file contains the type connection functions of all convolution operators of TVM. The type function of conv1d completes the functions of checking the input and output data format and realizing the constraint of output type through the reporter.
// Standard convolution operator shape relations
template <typename AttrType>
bool Conv1DRel(const Array<Type>& types, int num_inputs, const Attrs& attrs,
const TypeReporter& reporter) {
ICHECK_EQ(types.size(), 3);
const auto* data = types[0].as<TensorTypeNode>();
const auto* weight = types[1].as<TensorTypeNode>();
if (data == nullptr) return false;
static const Layout kNCW("NCW");
static const Layout kOIW("OIW");
const AttrType* param = attrs.as<AttrType>();
ICHECK(param != nullptr);
const Layout in_layout(param->data_layout);
const Layout kernel_layout(param->kernel_layout);
const auto trans_in_layout = tir::BijectiveLayout(in_layout, kNCW);
ICHECK(trans_in_layout.defined())
<< "Conv only support input layouts that are convertible from NCW."
<< " But got " << in_layout;
const auto trans_kernel_layout = tir::BijectiveLayout(kernel_layout, kOIW);
ICHECK(trans_kernel_layout.defined())
<< "Conv only support kernel layouts that are convertible from OIW."
<< " But got " << kernel_layout;
Layout out_layout(param->out_layout == "" ? param->data_layout : param->out_layout);
const auto trans_out_layout = tir::BijectiveLayout(out_layout, kNCW);
ICHECK(trans_out_layout.defined())
<< "Conv only support output layouts that are convertible from NCW."
<< " But got " << out_layout;
Array<IndexExpr> dshape_ncw = trans_in_layout.ForwardShape(data->shape);
IndexExpr channels, dilated_ksize;
// infer weight if the kernel_size and channels are defined
if (param->kernel_size.defined() && param->channels.defined()) {
Array<IndexExpr> wshape;
wshape = {{param->channels, dshape_ncw[1], param->kernel_size[0]}};
wshape = trans_kernel_layout.BackwardShape(wshape);
channels = param->channels;
dilated_ksize = 1 + (param->kernel_size[0] - 1) * param->dilation[0];
DataType weight_dtype = data->dtype;
if (weight != nullptr) {
weight_dtype = weight->dtype;
}
// assign result to reporter
reporter->Assign(types[1], TensorType(wshape, weight_dtype));
} else {
// use weight to infer the conv shape.
if (weight == nullptr) return false;
auto wshape = trans_kernel_layout.ForwardShape(weight->shape);
if (param->kernel_size.defined()) {
// check the size
ICHECK(reporter->AssertEQ(param->kernel_size[0], wshape[2]))
<< "Conv1D: shape of weight is inconsistent with kernel_size, "
<< " kernel_size=" << param->kernel_size << " wshape=" << wshape;
}
if (param->channels.defined()) {
ICHECK(reporter->AssertEQ(param->channels, wshape[0]))
<< "Conv1D: shape of weight is inconsistent with channels, "
<< " channels=" << param->channels << " wshape=" << wshape;
}
if (!dshape_ncw[1].as<tir::AnyNode>() && !wshape[1].as<tir::AnyNode>()) {
ICHECK(reporter->AssertEQ(dshape_ncw[1], wshape[1]));
}
channels = wshape[0];
dilated_ksize = 1 + (wshape[2] - 1) * param->dilation[0];
}
// dilation
Array<IndexExpr> oshape({dshape_ncw[0], channels, 0});
if (!dshape_ncw[2].as<tir::AnyNode>()) {
oshape.Set(2, indexdiv(dshape_ncw[2] + param->padding[0] + param->padding[1] - dilated_ksize,
param->strides[0]) +
1);
} else {
oshape.Set(2, dshape_ncw[2]);
}
DataType out_dtype = param->out_dtype;
if (out_dtype.bits() == 0) {
out_dtype = data->dtype;
}
oshape = trans_out_layout.BackwardShape(oshape);
// assign output type
reporter->Assign(types[2], TensorType(oshape, out_dtype));
return true;
}3.AttrsNode registration, Type Relation registration and CallNode registration
The code is located at \ SRC \ relay \ op \ NN \ revolution cc
AttrsNode:
// relay.nn.conv1d TVM_REGISTER_NODE_TYPE(Conv1DAttrs);
Type Relation and additional information registration:
RELAY_REGISTER_OP("nn.conv1d")
.describe(R"code(1D convolution layer (e.g. spatial convolution over sequences).
This layer creates a convolution kernel that is convolved
with the layer input to produce a tensor of outputs.
- **data**: This depends on the `layout` parameter. Input is 3D array of shape
(batch_size, in_channels, width) if `layout` is `NCW`.
- **weight**: (channels, in_channels, kernel_size)
- **out**: This depends on the `layout` parameter. Output is 3D array of shape
(batch_size, channels, out_width) if `layout` is `NCW`.
)code" TVM_ADD_FILELINE)
.set_attrs_type<Conv1DAttrs>()
.set_num_inputs(2)
.add_argument("data", "Tensor", "The input tensor.")
.add_argument("weight", "Tensor", "The weight tensor.")
.set_support_level(2)
.add_type_rel("Conv1D", Conv1DRel<Conv1DAttrs>)
.set_attr<FInferCorrectLayout>("FInferCorrectLayout", ConvInferCorrectLayout<Conv1DAttrs>);CallNode and its registration:
//Establish a CallNode, which is universal for 1d2d3d convolution operators
template <typename T>
inline Expr MakeConv(Expr data, Expr weight, Array<IndexExpr> strides, Array<IndexExpr> padding,
Array<IndexExpr> dilation, int groups, IndexExpr channels,
Array<IndexExpr> kernel_size, std::string data_layout,
std::string kernel_layout, std::string out_layout, DataType out_dtype,
std::string op_name) {
auto attrs = make_object<T>();
attrs->strides = std::move(strides);
attrs->padding = std::move(padding);
attrs->dilation = std::move(dilation);
attrs->groups = groups;
attrs->channels = std::move(channels);
attrs->kernel_size = std::move(kernel_size);
attrs->data_layout = std::move(data_layout);
attrs->kernel_layout = std::move(kernel_layout);
attrs->out_layout = std::move(out_layout);
attrs->out_dtype = std::move(out_dtype);
const Op& op = Op::Get(op_name);
return Call(op, {data, weight}, Attrs(attrs), {});
}
//register
TVM_REGISTER_GLOBAL("relay.op.nn._make.conv1d")
.set_body_typed([](Expr data, Expr weight, Array<IndexExpr> strides, Array<IndexExpr> padding,
Array<IndexExpr> dilation, int groups, IndexExpr channels,
Array<IndexExpr> kernel_size, String data_layout, String kernel_layout,
String out_layout, DataType out_dtype) {
return MakeConv<Conv1DAttrs>(data, weight, strides, padding, dilation, groups, channels,
kernel_size, data_layout, kernel_layout, out_layout, out_dtype,
"nn.conv1d");
});4. Definition of calculation in topi Library
The source code is located at \ Python \ TVM \ topi \ NN \ conv1d Py, which implements the convolution of NWC and NCW data formats. Here, only NCW is shown.
The operator defined by tensor expression in TOPI is the most difficult and abstract in TVM operator code. Teacher Chen Tianqi calls it a bridge between high-level IR and low-level IR. I feel that there is no simple, clear and complete tutorial on tensor expression in TVM on the Internet, including TVM community. I will open a pit to share the content in the future.
def conv1d_ncw(data, kernel, strides=1, padding="VALID", dilation=1, out_dtype=None):
if out_dtype is None:
out_dtype = data.dtype
if isinstance(strides, (tuple, list)):
strides = strides[0]
if isinstance(dilation, (tuple, list)):
dilation = dilation[0]
batch, in_channels, data_width = data.shape
out_channels, _, kernel_size = kernel.shape
# Compute the output shape
dilated_kernel_size = (kernel_size - 1) * dilation + 1
pad_left, pad_right = get_pad_tuple1d(padding, (dilated_kernel_size,))
out_channels = simplify(out_channels)
out_width = simplify((data_width - dilated_kernel_size + pad_left + pad_right) // strides + 1)
# Apply padding
pad_before = [0, 0, pad_left]
pad_after = [0, 0, pad_right]
temp = pad(data, pad_before, pad_after, name="pad_temp")
# Compute graph
rc = te.reduce_axis((0, in_channels), name="rc")
rw = te.reduce_axis((0, kernel_size), name="rw")
return te.compute(
(batch, out_channels, out_width),
lambda b, c, w: te.sum(
temp[b, rc, w * strides + rw * dilation].astype(out_dtype)
* kernel[c, rc, rw].astype(out_dtype),
axis=[rc, rw],
),
tag="conv1d_ncw",
)5. Packaging of calculation + scheduling
As in the previous article, the implementation of CPU is located in \ Python \ TVM \ relay \ op \ strategy \ generic py
There is no comparison between the implementation methods of CPU and GPU for the time being. After being familiar with CUDA Programming and hardware acceleration, I may write an article to share.
# conv1d
def wrap_compute_conv1d(topi_compute):
"""wrap conv1d topi compute"""
def _compute_conv1d(attrs, inputs, out_type):
"""Compute definition of conv1d"""
strides = get_const_tuple(attrs.strides)
padding = get_const_tuple(attrs.padding)
dilation = get_const_tuple(attrs.dilation)
out_dtype = attrs.out_dtype
out_dtype = inputs[0].dtype if out_dtype in ("same", "") else out_dtype
return [topi_compute(inputs[0], inputs[1], strides, padding, dilation, out_dtype)]
return _compute_conv1d
@override_native_generic_func("conv1d_strategy")
def conv1d_strategy(attrs, inputs, out_type, target):
"""conv1d generic strategy"""
logger.warning("conv1d is not optimized for this platform.")
layout = attrs.data_layout
dilation = get_const_tuple(attrs.dilation)
if dilation[0] < 1:
raise ValueError("dilation should be a positive value")
strategy = _op.OpStrategy()
if layout == "NCW":
strategy.add_implementation(
wrap_compute_conv1d(topi.nn.conv1d_ncw),
wrap_topi_schedule(topi.generic.schedule_conv1d_ncw),
name="conv1d_ncw.generic",
)
elif layout == "NWC":
strategy.add_implementation(
wrap_compute_conv1d(topi.nn.conv1d_nwc),
wrap_topi_schedule(topi.generic.schedule_conv1d_nwc),
name="conv1d_nwc.generic",
)
else:
raise ValueError("Unsupported conv1d layout {}".format(layout))
return strategy6. Final API encapsulation
def conv1d(
data,
weight,
strides=1,
padding=0,
dilation=1,
groups=1,
channels=None,
kernel_size=None,
data_layout="NCW",
kernel_layout="OIW",
out_layout="",
out_dtype="",
):
if isinstance(kernel_size, int):
kernel_size = (kernel_size,)
if isinstance(strides, int):
strides = (strides,)
if isinstance(dilation, int):
dilation = (dilation,)
padding = get_pad_tuple1d(padding)
return _make.conv1d(
data,
weight,
strides,
padding,
dilation,
groups,
channels,
kernel_size,
data_layout,
kernel_layout,
out_layout,
out_dtype,
)