1. hbase integration Mapreduce
in the offline task scenario, MapReduce accesses HBASE data to speed up analysis and expand analysis capabilities.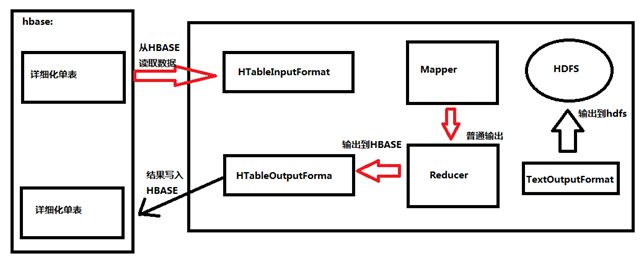
Read data from hbase (result)
public class ReadHBaseDataMR {
private static final String ZK_KEY = "hbase.zookeeper.quorum";
private static final String ZK_VALUE = "hadoop01:2181,hadoop01:2182,hadoop03:2181";
private static Configuration conf;
static {
conf=HBaseConfiguration.create();
conf.set(ZK_KEY,ZK_VALUE);
//Because it is read from hbase to its own hdfs cluster, the configuration file of hdfs needs to be loaded here
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
}
//job
public static void main(String[] args) {
Job job = null;
try {
//Use the conf of hbase here
job = Job.getInstance(conf);
job.setJarByClass(ReadHBaseDataMR.class);
//Full table scan
Scan scans=new Scan();
String tableName="user_info";
//Set up the integration of MapReduce and hbase
TableMapReduceUtil.initTableMapperJob(tableName,
scans,
ReadHBaseDataMR_Mapper.class,
Text.class,
NullWritable.class,
job,
false);
//Set the number of reducertasks to 0
job.setNumReduceTasks(0);
//Set the output to match the path on hdfs
Path output=new Path("/output/hbase/hbaseToHDFS");
if(output.getFileSystem(conf).exists(output)) {
output.getFileSystem(conf).delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
//Submit tasks
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
} catch (Exception e) {
e.printStackTrace();
}
}
//Mapper
//Use TableMapper to read the data of tables in hbase
private static class ReadHBaseDataMR_Mapper extends TableMapper<Text, NullWritable> {
Text mk = new Text();
NullWritable kv = NullWritable.get();
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//Read according to each rowkey by default
List<Cell> cells = value.listCells();
//Here, a row record, row key, column cluster, column and timestamp are determined by four coordinates
for(Cell cell:cells){
String row= Bytes.toString(CellUtil.cloneRow(cell)); //Row key
String cf=Bytes.toString(CellUtil.cloneFamily(cell)); //Cluster
String column=Bytes.toString(CellUtil.cloneQualifier(cell)); //column
String values=Bytes.toString(CellUtil.cloneValue(cell)); //value
long time=cell.getTimestamp(); //time stamp
mk.set(row+"\t"+cf+"\t"+column+"\t"+value+"\t"+time);
context.write(mk,kv);
}
}
}
}Write data to hbase (put)
public class HDFSToHbase {
private static final String ZK_CONNECT_KEY = "hbase.zookeeper.quorum";
private static final String ZK_CONNECT_VALUE = "hadoop02:2181,hadoop03:2181,hadoop01:2181";
private static Configuration conf;
static {
conf=HBaseConfiguration.create();
conf.set(ZK_CONNECT_KEY,ZK_CONNECT_VALUE);
//Because it is read from hbase to its own hdfs cluster, the configuration file of hdfs needs to be loaded here
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
}
//job
public static void main(String[] args) {
try {
Job job = Job.getInstance(conf);
job.setJarByClass(HDFSToHbase.class);
job.setMapperClass(MyMapper.class);
//Specify the output on the Map side
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
/**
* The representation specified as nulL uses the default
*/
String tableName="student";
//Integrate MapReduce reducer to hbase
TableMapReduceUtil.initTableReducerJob(tableName,MyReducer.class,
job,null, null, null, null,
false );
//Specify the input path of MapReducer
Path input = new Path("/in/mingxing.txt");
FileInputFormat.addInputPath(job, input);
//Submit tasks
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
//Mapper
private static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
NullWritable mv = NullWritable.get();
//The map side does not do any operation, and directly outputs the read data to the reduce side
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
context.write(value, mv);
}
}
//Reuser, reuser using TableReducer
/**
* TableReducer<KEYIN, VALUEIN, KEYOUT>
* KEYIN:mapper Output key
* VALUEIN: mapper Output value
* KEYOUT: reduce Output key
* By default, there is a fourth parameter: Mution, which means put/delete operation
*/
private static class MyReducer extends TableReducer<Text, NullWritable, NullWritable>{
//Cluster
String family[] = { "basicinfo","extrainfo"};
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// Zhangfenglun, m, 201352234455, zfl@163.com, 23521472 fields
for(NullWritable value:values){
String fields[]=key.toString().split(",");
//Name as rowkey
Put put=new Put(fields[0].getBytes());
put.addColumn(fields[0].getBytes(),"sex".getBytes(),fields[1].getBytes());
put.addColumn(fields[0].getBytes(),"age".getBytes(),fields[2].getBytes());
put.addColumn(fields[1].getBytes(),"phone".getBytes(),fields[3].getBytes());
put.addColumn(fields[1].getBytes(),"email".getBytes(),fields[4].getBytes());
put.addColumn(fields[1].getBytes(),"qq".getBytes(),fields[5].getBytes());
context.write(value, put);
}
}
}
}2. Import Mysql to HBASE
#Importing HBASE from MySQL using sqoop
sqoop import \ --connect jdbc:mysql://Hadoop 01: 3306 / test \ ා - MySQL entry --username hadoop \ #Login user name of MySQL --password root \ #Password to log in to MySQL --table book \ #Inserted table to MySQL --hbase-table book \ #Table name of HBASE --column-family info \ #Column clusters in HBASE tables --hbase-row-key bid \ #Which column in mysql is rowkey #ps: because of version incompatibility, the table inserted in HBASE here must be created in advance and cannot use: - HBASE create table \, this statement
3.HBASE integration hive
principle: Hive and HBase use their own external API to realize integration. They mainly rely on HBaseStorageHandler for communication. Using HBaseStorageHandler, Hive can obtain the HBase table name, column cluster and column corresponding to Hive table, InputFormat and OutputFormat class, create and delete HBase table, etc.
Hive accesses the table data in HBase, essentially reading the HBase table data through MapReduce. Its implementation is to use HiveHBaseTableInputFormat in MR to complete the segmentation of HBase table and obtain the RecordReader object to read the data.
.
.
Specific operation:
#Specify the address of the zookeeper cluster used by hbase: the default port is 2181, which can be left blank:
hive>set hbase.zookeeper.quorum=hadoop02:2181,hadoop03:2181,hadoop04:2181;
#Specify the root directory hbase uses in zookeeper
hive>set zookeeper.znode.parent=/hbase;
#Create hive table based on HBase table
hive>create external table mingxing(rowkey string, base_info map, extra_info map) row format delimited fields terminated by '\t'
>stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
>with serdeproperties ("hbase.columns.mapping" = ":key,base_info:,extra_info:")
>tblproperties("hbase.table.name"="mingxing","hbase.mapred.output.outputtable"="mingxing");
#ps:org.apache.hadoop.hive.hbase.HBaseStorageHandler: the processor handling the hive to HBase transformation relationship
#ps:hbase.columns.mapping: define the column cluster of HBase and the mapping relationship between columns and hive
#ps:hbase.table.name: HBase table nameAlthough hive integrates hbase, the actual data is still stored on hbase, and the corresponding file in the corresponding table directory of hive is empty. However, each time there is data added in hbase, hive will update the corresponding fields when executing this table query.