Typical usage scenarios of Zookeeper
Zookeeper distributed lock practice
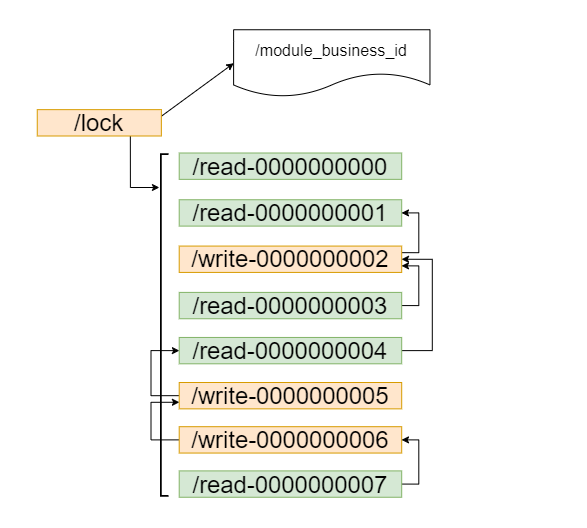
Zookeeper distributed locking principle
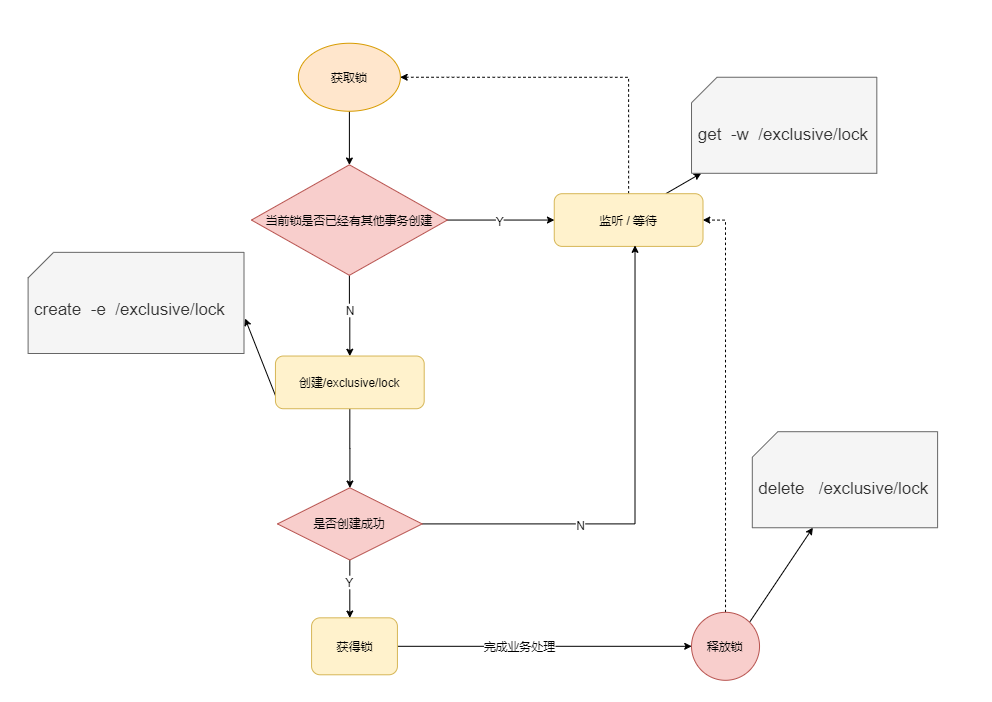
In the above implementation, when the concurrency problem is serious, the performance will decline sharply. The main reason is that all connections are listening to the same node. When the server detects a deletion event, it should notify all connections. All connections receive events at the same time and compete concurrently again. This is herding. This locking method is the specific implementation of unfair locking: how to avoid it? Let's look at the following method.
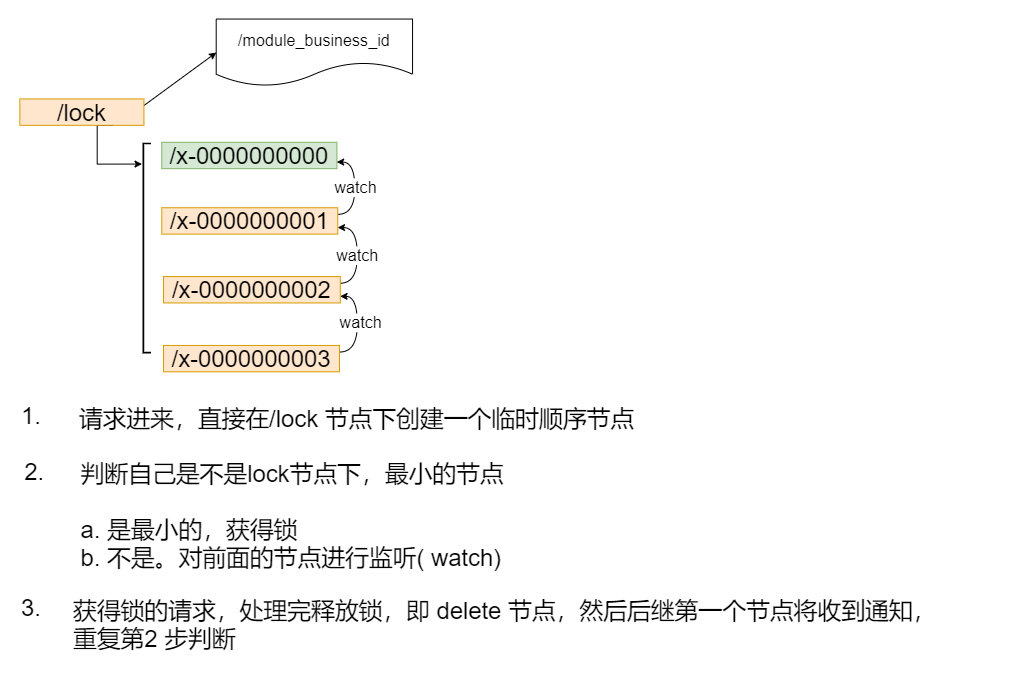
As mentioned above, with the help of temporary sequential nodes, the concurrent competitive lock of multiple nodes at the same time can be avoided, and the pressure on the server can be relieved. In this way, all lock requests are queued and locked, which is the specific implementation of fair lock.
The previous two locking methods have a common characteristic, that is, they are mutually exclusive locks. Only one request can be occupied at a time. If a large number of concurrent requests come up, the performance will decline sharply. All requests have to be locked. Is it true that all requests need to be locked? The answer is No. for example, if the data has not been modified, it does not need to be locked, but if the request to read the data has not been read, and a write request comes at this time, what should we do? Someone is already reading data. You can't write data at this time, otherwise the data will be incorrect. The write request cannot be executed until all the previous read locks are released. Therefore, it is necessary to add an identifier (read lock) to the read request to let the write request know that the data cannot be modified at this time. Otherwise the data will be inconsistent. If someone is already writing data, another request to write data is not allowed, which will also lead to inconsistent data. Therefore, all write requests need to be added with a write lock to avoid writing shared data at the same time.
for instance
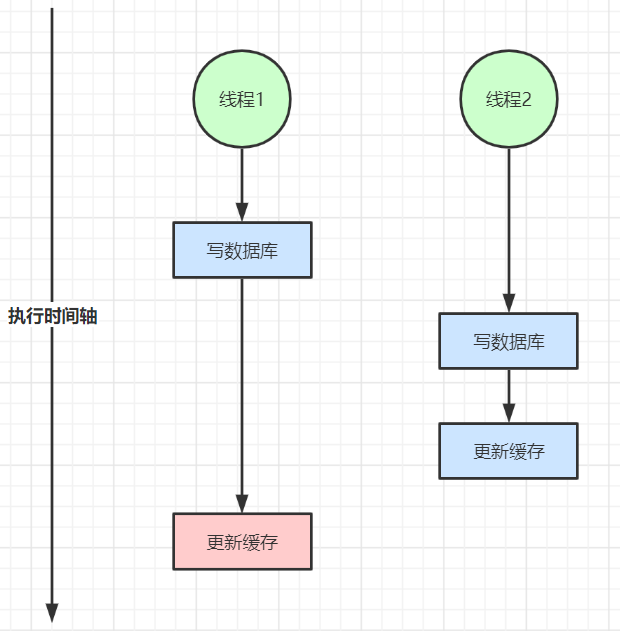
1. Inconsistent read-write concurrency
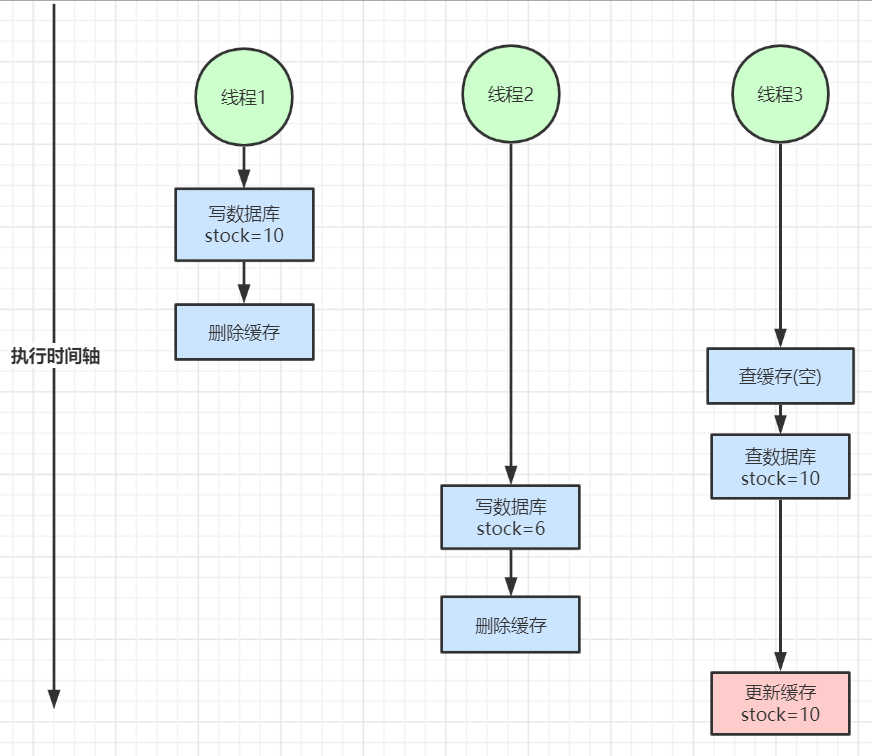
2. Double write inconsistency
Implementation principle of Zookeeper shared lock
Registration center practice
Registry scenario analysis:
- In a scenario where the distributed service architecture is relatively simple, our services may be like this
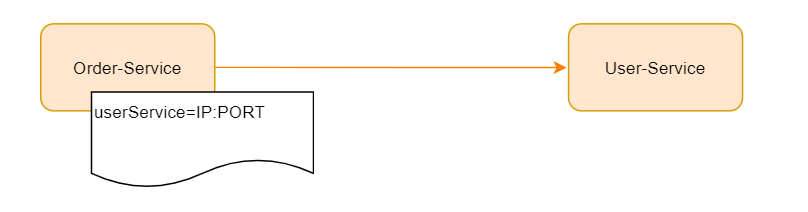
Now the order service needs to call the user service of the external service. For the external service dependency, we directly configure it in our service configuration file. In the scenario where the service invocation relationship is relatively simple, it is completely OK. With the expansion of services, user service may need to be deployed in clusters, as follows:
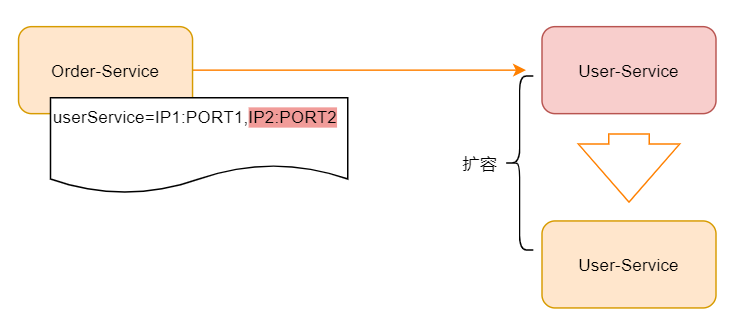
If the system call is not very complex, it is OK to realize a simple client load balancing through configuration management. However, with the development of business, the service module is divided into more fine-grained modules, and the business becomes more complex. It will become difficult to maintain by using simple configuration file management. Of course, we can add a service agent in front, such as nginx as the reverse agent, as follows:
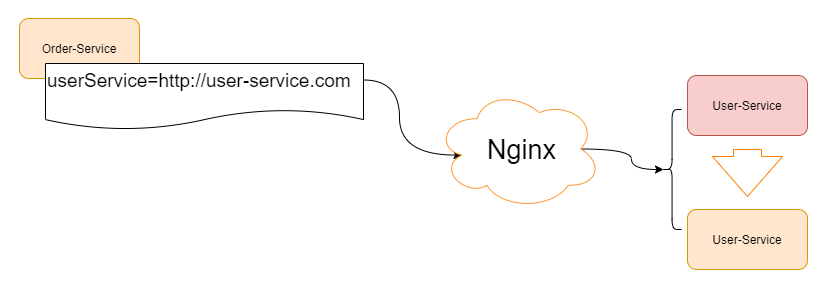
What if we are the following scenario?
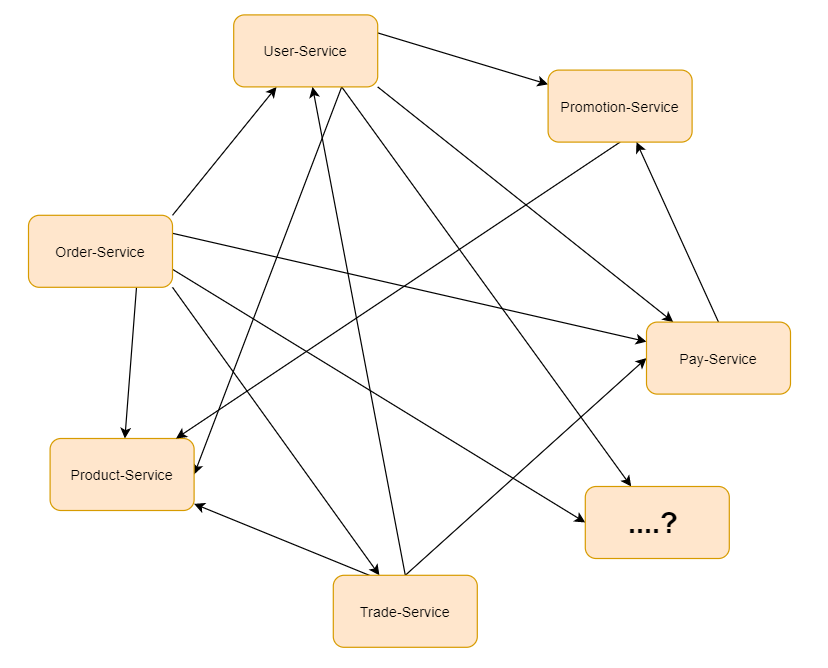
Services are no longer as simple as A-B and B-C, but complex and tiny service calls
At this time, we can use the basic features of Zookeeper to realize a registration center. What is a registration center? As the name suggests, it is to let many services register in Zookeeper. What is registration? Registration is to write some of their own service information, such as IP, port and some more specific service information, to the Zookeeper node, In this way, services in need can be obtained directly from Zookeeper. How can I get them? At this time, we can define a unified name, such as user service. When all user services are started, a child node (temporary node) is created under the user service node. This child node should be unique, representing the unique identification of each service instance, For those that rely on user services, for example, order service can obtain all user service child nodes and all child node information (IP, port, etc.) through the parent node user service. After obtaining the data of the child nodes, order service can cache them, and then realize load balancing of a client, At the same time, you can also listen to the user service directory, so that if a new node joins or exits, the order service can receive a notification, so that the order service can re acquire all child nodes and update the data. The type of child node of this user service is temporary node. As mentioned in the first lesson, the life cycle of temporary nodes in Zookeeper is bound to SESSION. If the SESSION times out, the corresponding node will be deleted. When deleted, Zookeeper will notify the client listening to the parent node of the node, so that the corresponding client can refresh the local cache again. When a new service is added, the corresponding client will also be notified to refresh the local cache. To achieve this goal, the client needs to register repeatedly to listen to the parent node. In this way, the automatic registration and automatic exit of the service are realized.
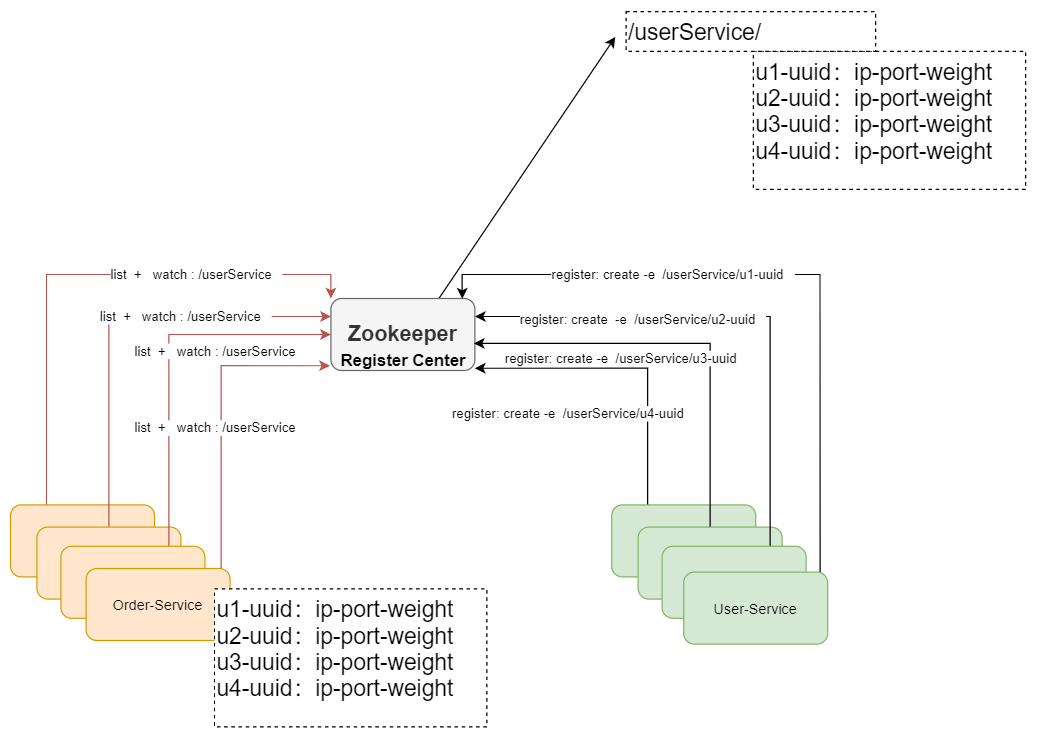
Spring Cloud ecology also provides the implementation of Zookeeper registration center. This project is called Spring Cloud Zookeeper. Let's conduct practical combat.
Project Description: in order to simplify the requirements, we use two services to explain. In actual use, we can draw inferences from one example. User center: user service product center: product service
The user invokes the product service and realizes the load balancing of the client. The product service automatically joins the cluster and automatically exits the service.
Project construction
1. Create a user center project
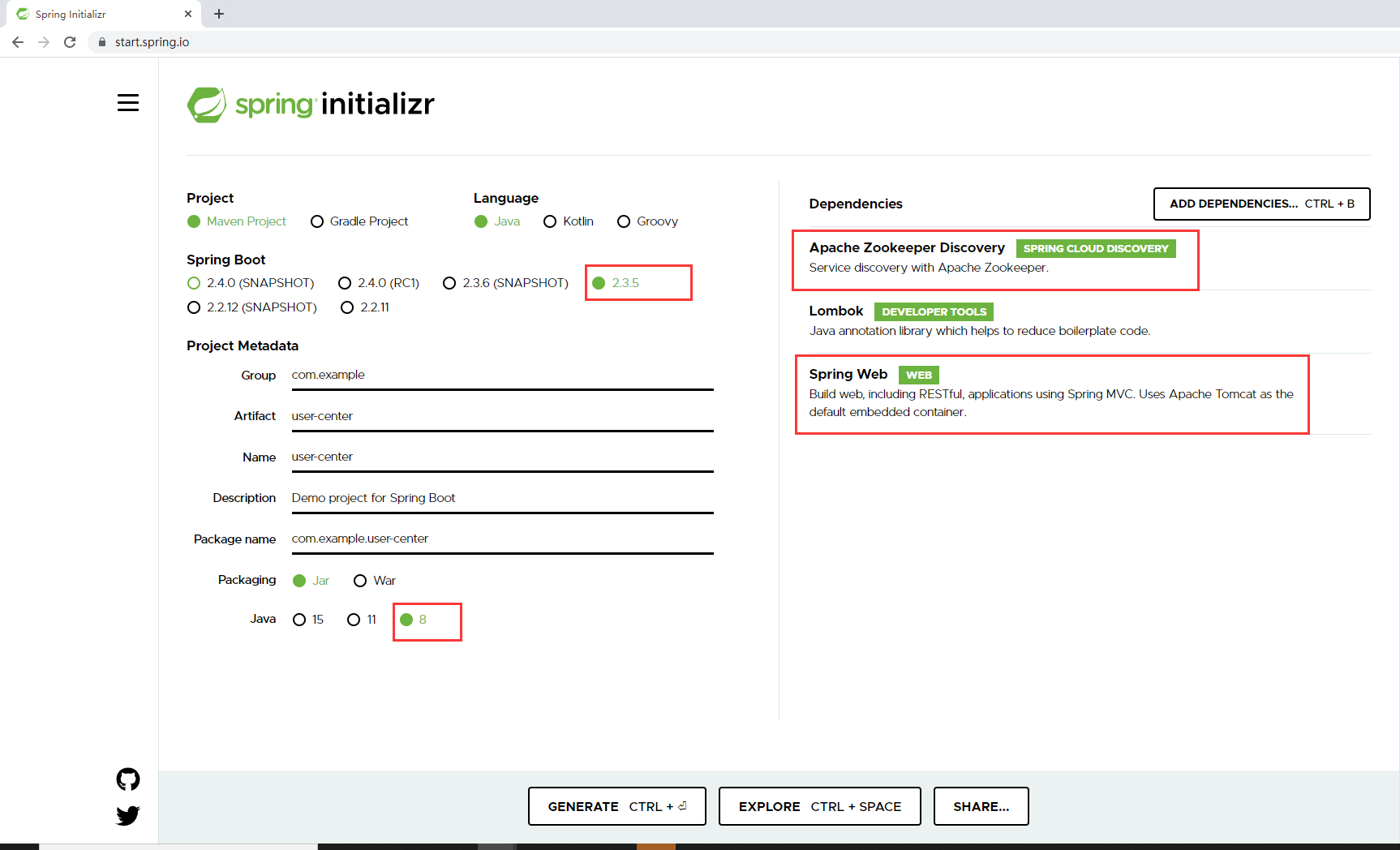
Create a product center in the same way
2. Unzip the project, open it with idea, and import it with maven
The product center project is introduced in the same way
3. Configure zookeeper
user-center Services: application.properties spring.application.name=user-center #zookeeper connection address, #If spring cloud zookeeper config is used, this configuration should be configured in bootstrap yml/bootstrap. In properties spring.cloud.zookeeper.connect-string=192.168.109.200:2181 #Register this service with zookeeper. If you don't want to be found, you can configure it as false and the default is true spring.cloud.zookeeper.discovery.register=true
Code writing: configure Resttemplate to support load balancing
@SpringBootApplication
public class UserCenterApplication {
public static void main(String[] args) {
SpringApplication.run(UserCenterApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}Write test classes: TestController and Spring Cloud support feign, spring resttemplate and webclient to access in the form of logical name instead of specific url.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
public class TestController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/test")
public String test(){
return this.restTemplate.getForObject( "http://product-center/getInfo" ,String.class);
}
}Product center services:
application.properties spring.application.name=user-center #zookeeper connection address spring.cloud.zookeeper.connect-string=192.168.109.200:2181 #Register this service with zookeeper spring.cloud.zookeeper.discovery.register=true
The main class receives a getInfo request
@SpringBootApplication
@RestController
public class ProductCenterApplication {
@Value("${server.port}")
private String port;
@Value( "${spring.application.name}" )
private String name;
@GetMapping("/getInfo")
public String getServerPortAndName(){
return this.name +" : "+ this.port;
}
public static void main(String[] args) {
SpringApplication.run(ProductCenterApplication.class, args);
}
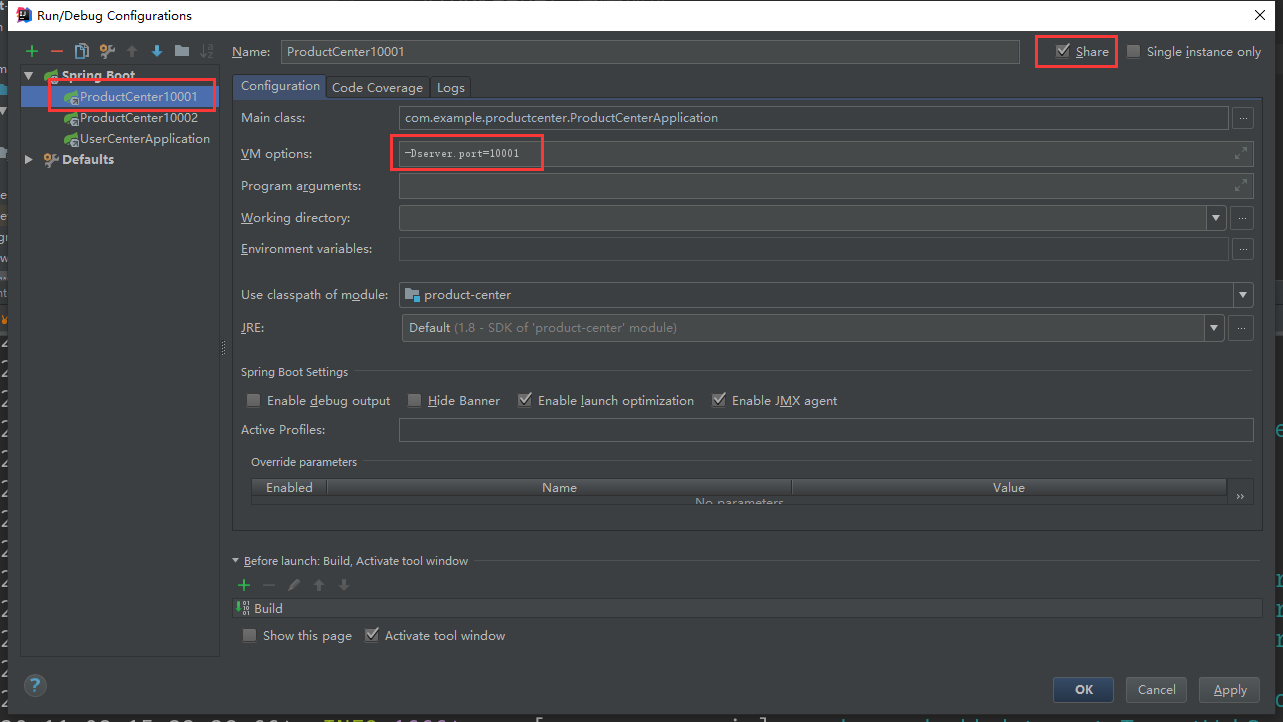
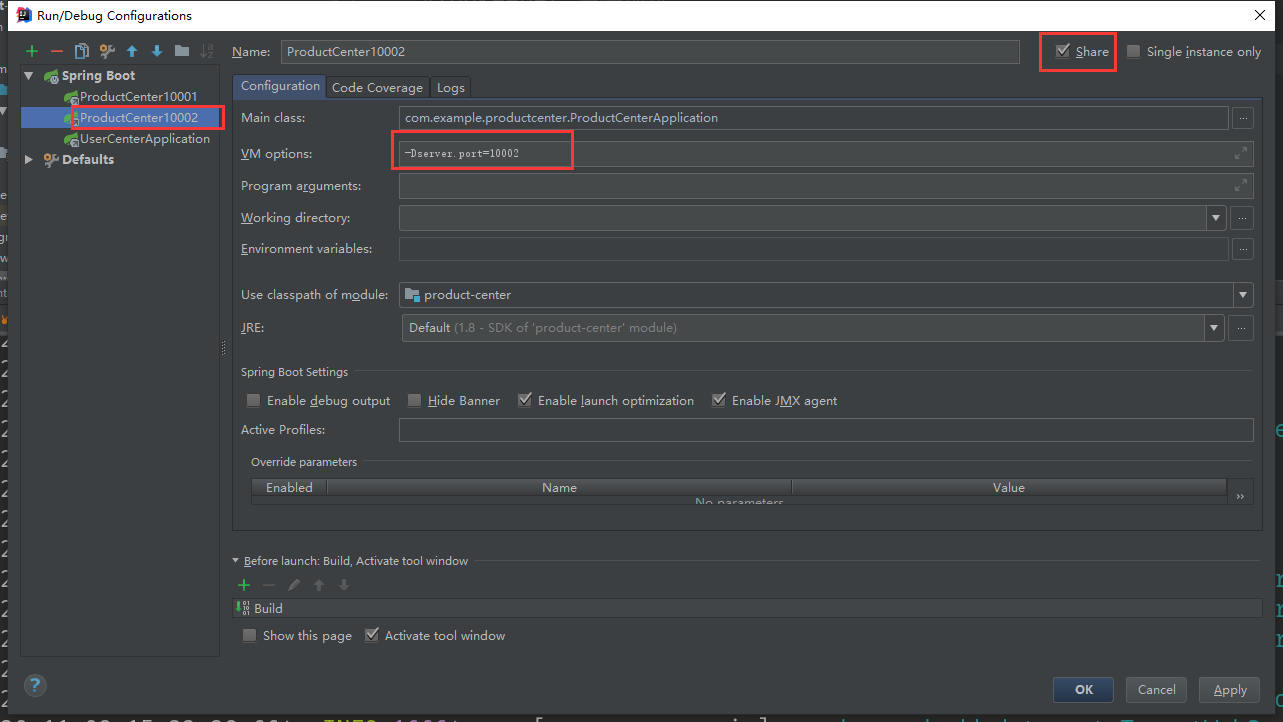
}Start two instances of product center
Through idea configuration, start multiple instances and distinguish different applications with ports
Start a user center instance. The default port is 8080
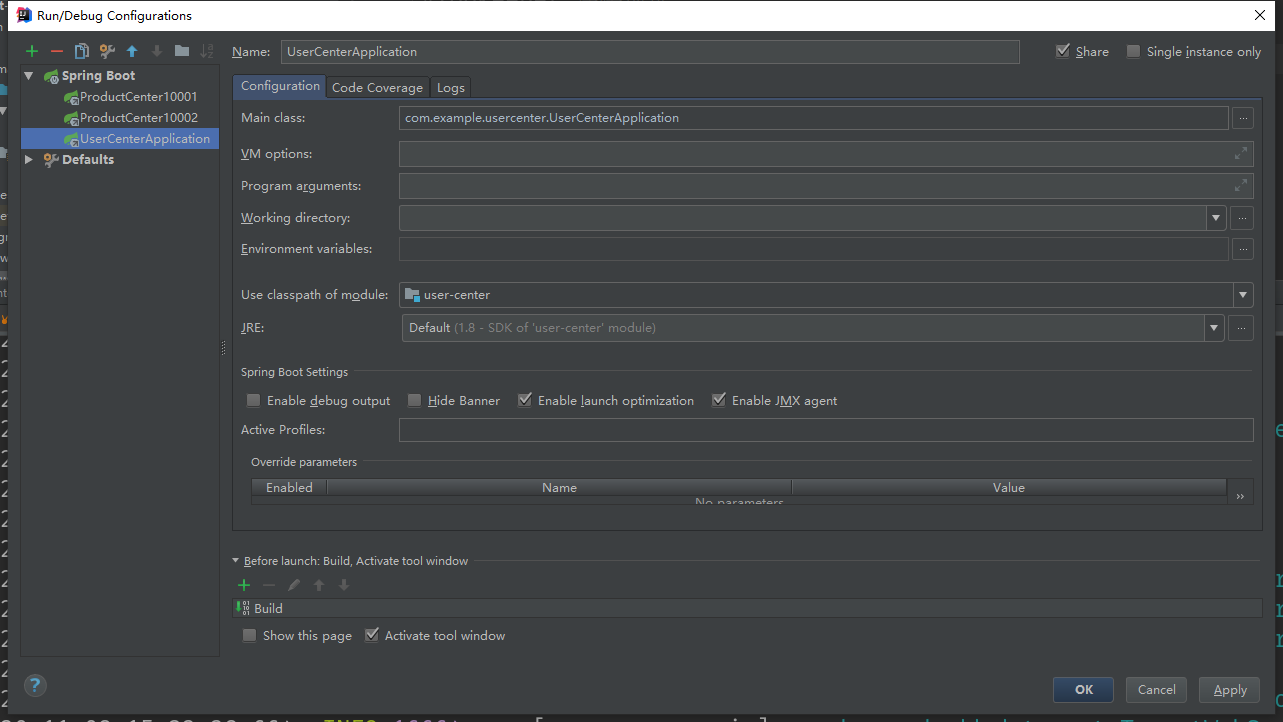
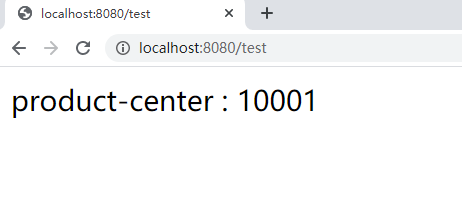
Start service: access http://localhost:8080/test
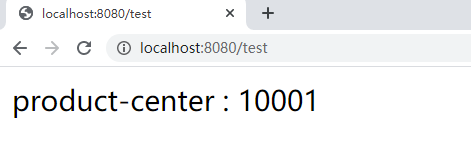
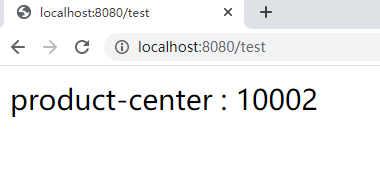
It has realized the automatic discovery of the server and the load balancing of the client.
Stop product center: 10002 and visit again
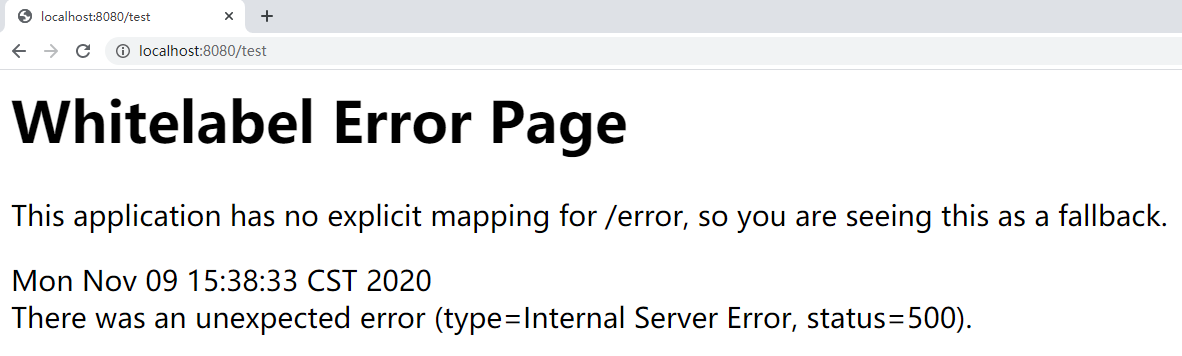
After a certain timeout period has elapsed, product center: 10002 will be removed from zookeeper. Zookeeper will notify the client to refresh the local cache and access it again. The automatic exit of the invalid node has been realized.