11.1 introduction to experimental environment
- The cluster environment is running normally
- Hive and Impala services are installed in the cluster
- Operating system: redhat6 five
- CDH and CM versions are 5.11.1
- EC2 user with sudo permission is used for operation
11.2 UDF function development - using Intellij tools
- Use Intellij tool to develop Hive's UDF function
- Create a Java project through Maven
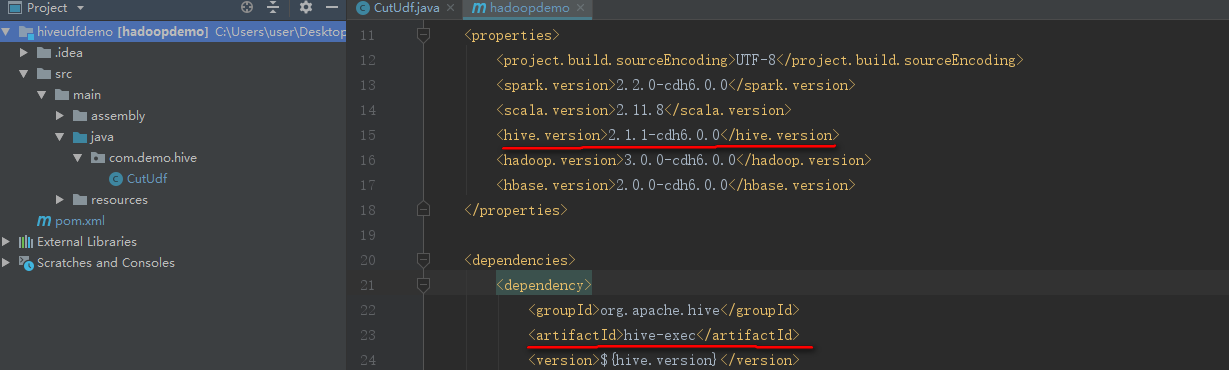
- pom. Add dependency of Hive package in XML file
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.1.0</version> </dependency>
- The sample code is as follows - Java
package com.peach.date;
import org.apache.hadoop.hive.ql.exec.UDF;
import java.text.ParseException;
import java.text.SimpleDateFormat;
/**
* SQL UDF date related tool classes
* Created by peach on 2017/8/24.
*/
public class DateUtils extends UDF {
/**
* Format the date string to the standard date format
* For example:
* 2017-8-9 to 2017-08-09
* 2017-08-09 9:23:3 to 2017-08-0909:23:03
* @param sdate
* @param pattern
* @return
*/
public static String evaluate(Stringsdate, String pattern) {
String formatDate = sdate;
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
formatDate =sdf.format(sdf.parse(sdate));
} catch (ParseException e) {
e.printStackTrace();
}
return formatDate;
}
}
- Here, you need to integrate UDF classes and override the evaluate method to implement custom functions.
- Compile jar package
- The prerequisite is that Maven's environment variable has been configured, the command line enters the project directory, and execute the following commands:
mvn clean package
11.3 Hive uses UDF
The sql-udf-utils-1.0-snapshot compiled in 11.2 Upload jar to cluster server
11.3.1 create temporary UDF
- Enter Hive's shell command line and execute the following command to create a temporary function
add jar /home/ec2-user/sql-udf-utils-1.0-SNAPSHOT.jar; create temporary function parse_date as 'com.peach.date.DateUtils';
- Test the UDF function on the command line
select parse_date(dates, 'yyyy-MM-dd HH:mm:ss') from date_test1;
11.3.2 creating a permanent UDF
- Create the corresponding directory in HDFS and add sql-udf-utils-1.0-snapshot Upload the jar package to this directory
[ec2-user@ip-172-31-8-141 ~]$ hadoop dfs -mkdir /udfjar [ec2-user@ip-172-31-8-141 ~]$ hadoop dfs -put sql-udf-utils-1.0-SNAPSHOT.jar /udfjar
- Note: the directory udfjar and sql-udf-utils-1.0-snapshot Jar permission. The user is hive
- Enter Hive's shell command line and execute the following command to create a permanent UDF
create function default.parse_date as 'com.peach.date.DateUtils' using jar 'hdfs://ip-172-31-9-186.ap-southeast-1.compute.internal:8020/udfjar/sql-udf-utils-1.0-SNAPSHOT.jar';
- Note: if there is a database name when creating, the UDF function is only effective for the library, and other libraries cannot use the UDF function.
- Test the UDF on the command line
select parse_date(dates, 'yyyy-MM-dd HH:mm:ss') from date_test1;
- Verify that the permanent UDF function is valid
- Reopening Hive CLI can normally use the created UDF functions
11.4 Impala uses Hive's UDF
- Execute the metadata synchronization command on the Impala shell command line
[ip-172-31-10-156.ap-southeast-1.compute.internal:21000] > invalidate metadata;
- Using UDF functions
[ip-172-31-10-156.ap-southeast-1.compute.internal:21000] > select parse_date(dates,'yyyy-MM-dd HH:mm:ss') from date_test1;
11.5 common problem solving
1. Use UDF exception through Impala command
- Exception when using UDF custom function through Impala CLI command line
Connected to ip-172-31-10-156.ap-southeast-1.compute.internal:21000 Server version: impalad version 2.7.0-cdh5.10.2 RELEASE (build 38c989c0330ea952133111e41965ff9af96412d3) [ip-172-31-10-156.ap-southeast-1.compute.internal:21000] > select parse_date(dates) from date_test1; Query: select parse_date(dates) from date_test1 Query submitted at: 2017-08-24 12:51:44 (Coordinator: http://ip-172-31-10-156.ap-southeast-1.compute.internal:25000) ERROR: AnalysisException: default.parse_date() unknown
- resolvent:
- If the metadata is not synchronized, execute the following command to synchronize the metadata:
[ip-172-31-10-156.ap-southeast-1.compute.internal:21000] > invalidate metadata;
2. Execute on the Impala CLI command line. The exceptions are as follows
[ip-172-31-10-156.ap-southeast-1.compute.internal:21000] > select parse_date(dates,'yyyy-MM-dd HH:mm:ss') from date_test1; Query: select parse_date(dates,'yyyy-MM-dd HH:mm:ss') from date_test1 Query submitted at: 2017-08-24 13:02:14 (Coordinator: http://ip-172-31-10-156.ap-southeast-1.compute.internal:25000) ERROR: Failed to copy hdfs://ip-172-31-9-186.ap-southeast-1.compute.internal:8020/udfjar/sql-udf-utils-1.0-SNAPSHOT.jar to /var/lib/impala/udfs/sql-udf-utils-1.0-SNAPSHOT.2386.2.jar: Error(2): No such file or directory
- On the Impala Daemon server, the directory does not exist
- resolvent:
- Create the / var/lib/impala/udfs directory on all Impala Daemon servers
- Note: users and groups to which the directory belongs
- Create the / var/lib/impala/udfs directory on all Impala Daemon servers
[ec2-user@ip-172-31-10-156 lib]$ sudo mkdir -p impala/udf [ec2-user@ip-172-31-10-156 lib]$ sudo chown -R impala:impala impala/
Big data video recommendation:
CSDN
Big data voice recommendation:
Application of enterprise level big data technology
Recommendation system of big data machine learning cases
natural language processing
Big data foundation
Artificial intelligence: introduction to deep learning to mastery