Introduction: This paper introduces how to test the memory access delay of multi-level cache and the computer principle behind it.
The CPU cache is often a multi-level pyramid model. L1 is closest to the CPU and has the smallest access delay, but the cache capacity is also the smallest. This paper introduces how to test the memory access delay of multi-level cache and the computer principle behind it.
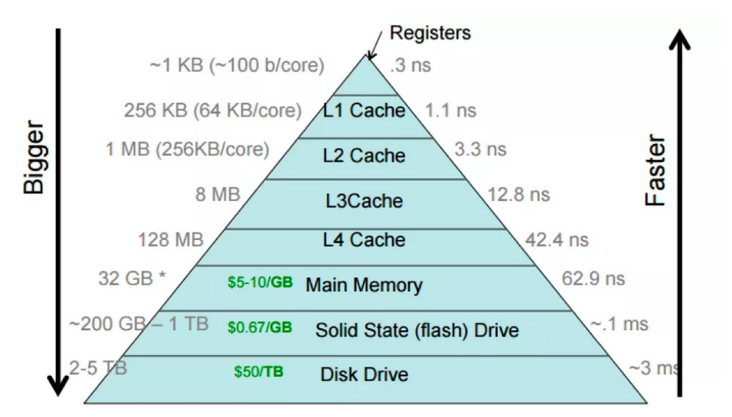
Source: https://cs.brown.edu/courses/...
Cache Latency
Wikichip[1] provides cache latency of different CPU models. The unit is generally cycle, which is converted to ns through simple operation. Taking skylake as an example, the benchmark value of cache delay at all levels of CPU is:
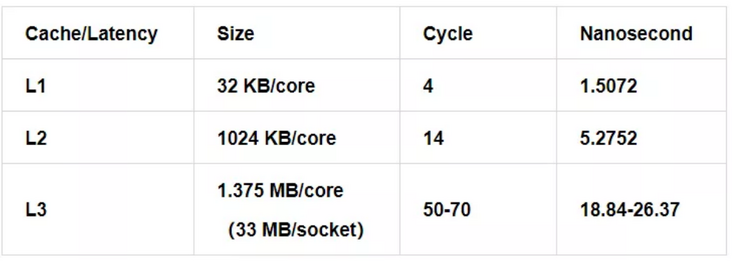
CPU Frequency:2654MHz (0.3768 nanosec/clock)
Design experiment
1. naive thinking
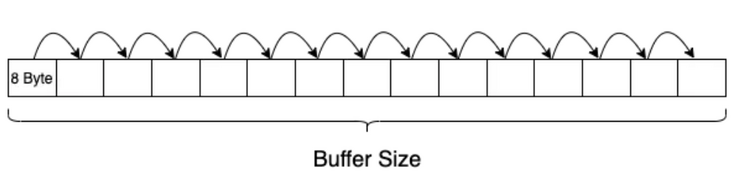
Apply for a buffer. The buffer size is the size corresponding to the cache. Warm up the first traversal and load all the data into the cache. The second traversal takes time to calculate the average delay of each read.
The code implementation of MEM lat. C is as follows:
#include <sys/types.h>
#include <stdlib.h>
#include <stdio.h>
#include <sys/mman.h>
#include <sys/time.h>
#include <unistd.h>
#define ONE p = (char **)*p;
#define FIVE ONE ONE ONE ONE ONE
#define TEN FIVE FIVE
#define FIFTY TEN TEN TEN TEN TEN
#define HUNDRED FIFTY FIFTY
static void usage()
{
printf("Usage: ./mem-lat -b xxx -n xxx -s xxx\n");
printf(" -b buffer size in KB\n");
printf(" -n number of read\n\n");
printf(" -s stride skipped before the next access\n\n");
printf("Please don't use non-decimal based number\n");
}
int main(int argc, char* argv[])
{
unsigned long i, j, size, tmp;
unsigned long memsize = 0x800000; /* 1/4 LLC size of skylake, 1/5 of broadwell */
unsigned long count = 1048576; /* memsize / 64 * 8 */
unsigned int stride = 64; /* skipped amount of memory before the next access */
unsigned long sec, usec;
struct timeval tv1, tv2;
struct timezone tz;
unsigned int *indices;
while (argc-- > 0) {
if ((*argv)[0] == '-') { /* look at first char of next */
switch ((*argv)[1]) { /* look at second */
case 'b':
argv++;
argc--;
memsize = atoi(*argv) * 1024;
break;
case 'n':
argv++;
argc--;
count = atoi(*argv);
break;
case 's':
argv++;
argc--;
stride = atoi(*argv);
break;
default:
usage();
exit(1);
break;
}
}
argv++;
}
char* mem = mmap(NULL, memsize, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0);
// trick3: init pointer chasing, per stride=8 byte
size = memsize / stride;
indices = malloc(size * sizeof(int));
for (i = 0; i < size; i++)
indices[i] = i;
// trick 2: fill mem with pointer references
for (i = 0; i < size - 1; i++)
*(char **)&mem[indices[i]*stride]= (char*)&mem[indices[i+1]*stride];
*(char **)&mem[indices[size-1]*stride]= (char*)&mem[indices[0]*stride];
char **p = (char **) mem;
tmp = count / 100;
gettimeofday (&tv1, &tz);
for (i = 0; i < tmp; ++i) {
HUNDRED; //trick 1
}
gettimeofday (&tv2, &tz);
if (tv2.tv_usec < tv1.tv_usec) {
usec = 1000000 + tv2.tv_usec - tv1.tv_usec;
sec = tv2.tv_sec - tv1.tv_sec - 1;
} else {
usec = tv2.tv_usec - tv1.tv_usec;
sec = tv2.tv_sec - tv1.tv_sec;
}
printf("Buffer size: %ld KB, stride %d, time %d.%06d s, latency %.2f ns\n",
memsize/1024, stride, sec, usec, (sec * 1000000 + usec) * 1000.0 / (tmp *100));
munmap(mem, memsize);
free(indices);
}
Here are three tips:
- HUNDRED macro: expand the macro to avoid the interference of other instructions on memory access as much as possible.
- Secondary pointer: the buffer is concatenated through the secondary pointer to avoid calculating the offset during memory access.
- Char and char * are 8 bytes, so stripe is 8.
Test method:
#set -x
work=./mem-lat
buffer_size=1
stride=8
for i in `seq 1 15`; do
taskset -ac 0 $work -b $buffer_size -s $stride
buffer_size=$(($buffer_size*2))
doneThe test results are as follows:
//L1 Buffer size: 1 KB, stride 8, time 0.003921 s, latency 3.74 ns Buffer size: 2 KB, stride 8, time 0.003928 s, latency 3.75 ns Buffer size: 4 KB, stride 8, time 0.003935 s, latency 3.75 ns Buffer size: 8 KB, stride 8, time 0.003926 s, latency 3.74 ns Buffer size: 16 KB, stride 8, time 0.003942 s, latency 3.76 ns Buffer size: 32 KB, stride 8, time 0.003963 s, latency 3.78 ns //L2 Buffer size: 64 KB, stride 8, time 0.004043 s, latency 3.86 ns Buffer size: 128 KB, stride 8, time 0.004054 s, latency 3.87 ns Buffer size: 256 KB, stride 8, time 0.004051 s, latency 3.86 ns Buffer size: 512 KB, stride 8, time 0.004049 s, latency 3.86 ns Buffer size: 1024 KB, stride 8, time 0.004110 s, latency 3.92 ns //L3 Buffer size: 2048 KB, stride 8, time 0.004126 s, latency 3.94 ns Buffer size: 4096 KB, stride 8, time 0.004161 s, latency 3.97 ns Buffer size: 8192 KB, stride 8, time 0.004313 s, latency 4.11 ns Buffer size: 16384 KB, stride 8, time 0.004272 s, latency 4.07 ns
Compared with the reference value, the delay of L1 is too large and the delay of L2 and L3 is too small, which is not in line with the expectation.
2. thinking with hardware: cache line
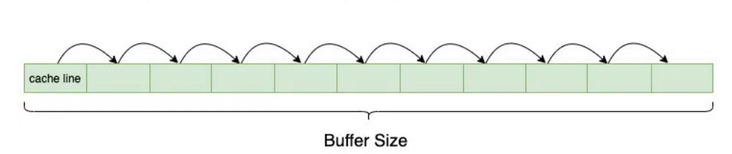
In modern processors, memory is organized in cache with cache line as granularity. The read-write granularity of memory access is a cache line, and the most common cache line size is 64 bytes.
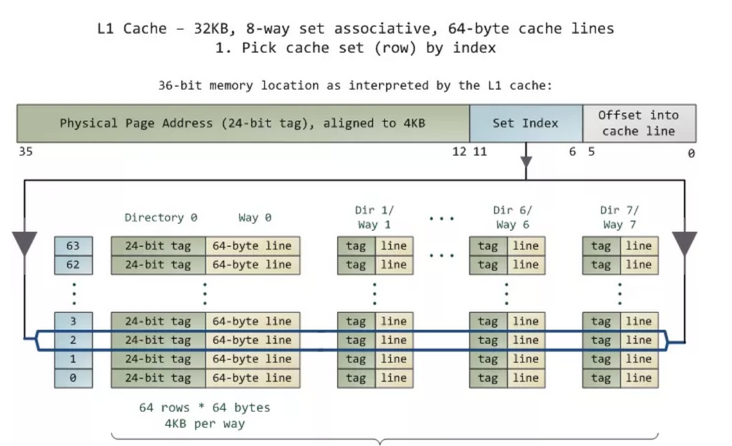
If we simply read 128KB buffer s in sequence with the granularity of 8 bytes, assuming that the data hits L2, the data will be cached to L1. One cache line and other memory access operations will only hit L1, resulting in significantly smaller L2 latency.
For the CPU tested in this article, the cache line size is 64 bytes, and you only need to set the stripe to 64.
The test results are as follows:
//L1 Buffer size: 1 KB, stride 64, time 0.003933 s, latency 3.75 ns Buffer size: 2 KB, stride 64, time 0.003930 s, latency 3.75 ns Buffer size: 4 KB, stride 64, time 0.003925 s, latency 3.74 ns Buffer size: 8 KB, stride 64, time 0.003931 s, latency 3.75 ns Buffer size: 16 KB, stride 64, time 0.003935 s, latency 3.75 ns Buffer size: 32 KB, stride 64, time 0.004115 s, latency 3.92 ns //L2 Buffer size: 64 KB, stride 64, time 0.007423 s, latency 7.08 ns Buffer size: 128 KB, stride 64, time 0.007414 s, latency 7.07 ns Buffer size: 256 KB, stride 64, time 0.007437 s, latency 7.09 ns Buffer size: 512 KB, stride 64, time 0.007429 s, latency 7.09 ns Buffer size: 1024 KB, stride 64, time 0.007650 s, latency 7.30 ns Buffer size: 2048 KB, stride 64, time 0.007670 s, latency 7.32 ns //L3 Buffer size: 4096 KB, stride 64, time 0.007695 s, latency 7.34 ns Buffer size: 8192 KB, stride 64, time 0.007786 s, latency 7.43 ns Buffer size: 16384 KB, stride 64, time 0.008172 s, latency 7.79 ns
Although the delay of L2 and L3 is increased compared with scheme 1, it is still not as expected.
3. thinking with hardware: prefetch
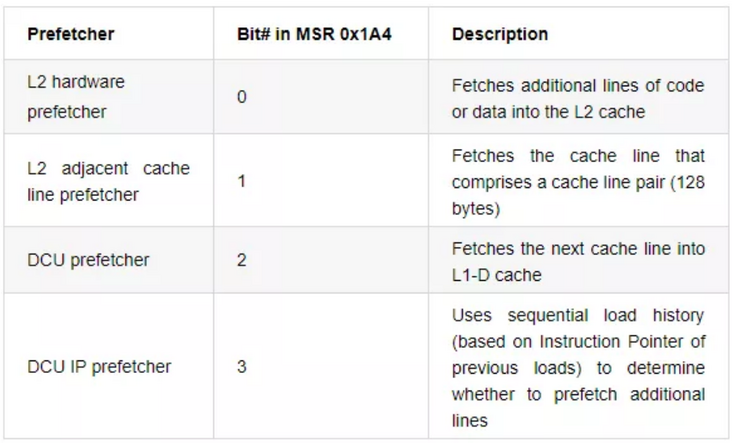
Modern processors usually support prefetch. Data prefetching loads the data that may be used later in the code into the cache in advance, reduces the time that the CPU waits for the data to be loaded from the memory, improves the cache hit rate, and then improves the operation efficiency of the software.
Intel processors support four kinds of hardware prefetching [2], which can be turned off and on through MSR control:
Here, we simply set the stripe to 128 and 256 to avoid hardware prefetching. The L3 memory access delay of the test increases significantly:
// stride 128 Buffer size: 1 KB, stride 256, time 0.003927 s, latency 3.75 ns Buffer size: 2 KB, stride 256, time 0.003924 s, latency 3.74 ns Buffer size: 4 KB, stride 256, time 0.003928 s, latency 3.75 ns Buffer size: 8 KB, stride 256, time 0.003923 s, latency 3.74 ns Buffer size: 16 KB, stride 256, time 0.003930 s, latency 3.75 ns Buffer size: 32 KB, stride 256, time 0.003929 s, latency 3.75 ns Buffer size: 64 KB, stride 256, time 0.007534 s, latency 7.19 ns Buffer size: 128 KB, stride 256, time 0.007462 s, latency 7.12 ns Buffer size: 256 KB, stride 256, time 0.007479 s, latency 7.13 ns Buffer size: 512 KB, stride 256, time 0.007698 s, latency 7.34 ns Buffer size: 512 KB, stride 128, time 0.007597 s, latency 7.25 ns Buffer size: 1024 KB, stride 128, time 0.009169 s, latency 8.74 ns Buffer size: 2048 KB, stride 128, time 0.010008 s, latency 9.55 ns Buffer size: 4096 KB, stride 128, time 0.010008 s, latency 9.55 ns Buffer size: 8192 KB, stride 128, time 0.010366 s, latency 9.89 ns Buffer size: 16384 KB, stride 128, time 0.012031 s, latency 11.47 ns // stride 256 Buffer size: 512 KB, stride 256, time 0.007698 s, latency 7.34 ns Buffer size: 1024 KB, stride 256, time 0.012654 s, latency 12.07 ns Buffer size: 2048 KB, stride 256, time 0.025210 s, latency 24.04 ns Buffer size: 4096 KB, stride 256, time 0.025466 s, latency 24.29 ns Buffer size: 8192 KB, stride 256, time 0.025840 s, latency 24.64 ns Buffer size: 16384 KB, stride 256, time 0.027442 s, latency 26.17 ns
The memory access delay of L3 is basically in line with expectations, but L1 and L2 are obviously too large.
If the random memory access delay is tested, a more common approach is to randomize the buffer pointer when it is concatenated.
// shuffle indices
for (i = 0; i < size; i++) {
j = i + rand() % (size - i);
if (i != j) {
tmp = indices[i];
indices[i] = indices[j];
indices[j] = tmp;
}
}It can be seen that the test result is basically the same as that of 256 stripe.
Buffer size: 1 KB, stride 64, time 0.003942 s, latency 3.76 ns Buffer size: 2 KB, stride 64, time 0.003925 s, latency 3.74 ns Buffer size: 4 KB, stride 64, time 0.003928 s, latency 3.75 ns Buffer size: 8 KB, stride 64, time 0.003931 s, latency 3.75 ns Buffer size: 16 KB, stride 64, time 0.003932 s, latency 3.75 ns Buffer size: 32 KB, stride 64, time 0.004276 s, latency 4.08 ns Buffer size: 64 KB, stride 64, time 0.007465 s, latency 7.12 ns Buffer size: 128 KB, stride 64, time 0.007470 s, latency 7.12 ns Buffer size: 256 KB, stride 64, time 0.007521 s, latency 7.17 ns Buffer size: 512 KB, stride 64, time 0.009340 s, latency 8.91 ns Buffer size: 1024 KB, stride 64, time 0.015230 s, latency 14.53 ns Buffer size: 2048 KB, stride 64, time 0.027567 s, latency 26.29 ns Buffer size: 4096 KB, stride 64, time 0.027853 s, latency 26.56 ns Buffer size: 8192 KB, stride 64, time 0.029945 s, latency 28.56 ns Buffer size: 16384 KB, stride 64, time 0.034878 s, latency 33.26 ns
4. thinking with compiler: register keyword
After solving the problem that L3 is too small, we continue to look at the reasons why L1 and L2 are too large. In order to find out the reason why it is too large, we first disassemble the executable program to see whether the executed assembly instruction is what we want:
objdump -D -S mem-lat > mem-lat.s
Add spacing to cards
Delete card
- -D: Display assembler contents of all sections.
- -S: Intermix source code with disassembly. (you need to use - g during GCC compilation to generate mode information)
Generated assembly file MEM lat. S:
char **p = (char **)mem; 400b3a: 48 8b 45 c8 mov -0x38(%rbp),%rax 400b3e: 48 89 45 d0 mov %rax,-0x30(%rbp) // push stack //... HUNDRED; 400b85: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b89: 48 8b 00 mov (%rax),%rax 400b8c: 48 89 45 d0 mov %rax,-0x30(%rbp) 400b90: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b94: 48 8b 00 mov (%rax),%rax
First, the variable mem is assigned to the variable p, which is pushed into the stack - 0x30(%rbp).
char **p = (char **)mem; 400b3a: 48 8b 45 c8 mov -0x38(%rbp),%rax 400b3e: 48 89 45 d0 mov %rax,-0x30(%rbp)
Logic of memory access:
HUNDRED; // p = (char **)*p 400b85: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b89: 48 8b 00 mov (%rax),%rax 400b8c: 48 89 45 d0 mov %rax,-0x30(%rbp)
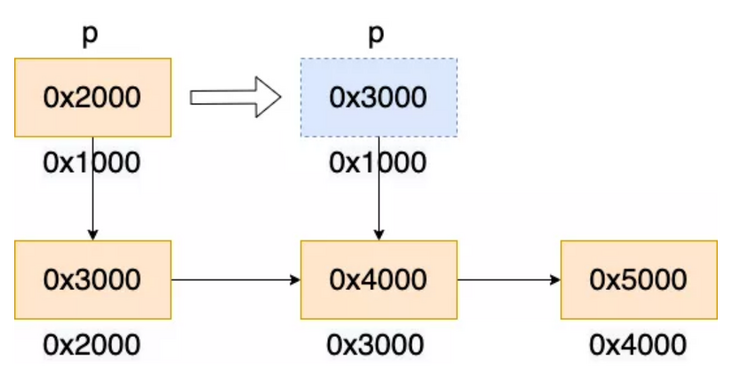
- First read the value of pointer variable p from the stack to the rax register (the type of variable p is char *, which is a secondary pointer, that is, pointer P points to a char variable, that is, the value of P is also an address). The value of variable p in the following figure is 0x2000.
- Read the value of the variable pointed to by the rax register into the rax register, corresponding to the monocular operation * p. In the following figure, the value of address 0x2000 is 0x3000, and rax is updated to 0x3000.
- Assign the rax register to the variable P. In the following figure, the value of variable p is updated to 0x3000.
According to the result of disassembly, we can see that the expected one move instruction is compiled into three, and the cache latency is increased by three times.
The register keyword of C language allows the compiler to save variables into registers, so as to avoid the overhead of reading from the stack every time.
It's a hint to the compiler that the variable will be heavily used and that you recommend it be kept in a processor register if possible.
When we declare p, we add the register keyword.
register char **p = (char **)mem;
The test results are as follows:
// L1 Buffer size: 1 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 2 KB, stride 64, time 0.000029 s, latency 0.03 ns Buffer size: 4 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 8 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 16 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 32 KB, stride 64, time 0.000030 s, latency 0.03 ns // L2 Buffer size: 64 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 128 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 256 KB, stride 64, time 0.000029 s, latency 0.03 ns Buffer size: 512 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 1024 KB, stride 64, time 0.000030 s, latency 0.03 ns // L3 Buffer size: 2048 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 4096 KB, stride 64, time 0.000029 s, latency 0.03 ns Buffer size: 8192 KB, stride 64, time 0.000030 s, latency 0.03 ns Buffer size: 16384 KB, stride 64, time 0.000030 s, latency 0.03 ns
The delay of memory access is less than 1 ns, which is obviously not in line with the expectation.
5. thinking with compiler: Touch it!
Disassemble again to see what's wrong. The compiled code is as follows:
for (i = 0; i < tmp; ++i) {
40155e: 48 c7 45 f8 00 00 00 movq $0x0,-0x8(%rbp)
401565: 00
401566: eb 05 jmp 40156d <main+0x37e>
401568: 48 83 45 f8 01 addq $0x1,-0x8(%rbp)
40156d: 48 8b 45 f8 mov -0x8(%rbp),%rax
401571: 48 3b 45 b0 cmp -0x50(%rbp),%rax
401575: 72 f1 jb 401568 <main+0x379>
HUNDRED;
}
gettimeofday (&tv2, &tz);
401577: 48 8d 95 78 ff ff ff lea -0x88(%rbp),%rdx
40157e: 48 8d 45 80 lea -0x80(%rbp),%rax
401582: 48 89 d6 mov %rdx,%rsi
401585: 48 89 c7 mov %rax,%rdi
401588: e8 e3 fa ff ff callq 401070 <gettimeofday@plt>The HUNDRED macro did not generate any assembly code. Statements involving variable p have no practical effect, just data reading, and the probability is optimized by the compiler.
register char **p = (char **) mem;
tmp = count / 100;
gettimeofday (&tv1, &tz);
for (i = 0; i < tmp; ++i) {
HUNDRED;
}
gettimeofday (&tv2, &tz);
/* touch pointer p to prevent compiler optimization */
char **touch = p;Disassembly verification:
HUNDRED; 401570: 48 8b 1b mov (%rbx),%rbx 401573: 48 8b 1b mov (%rbx),%rbx 401576: 48 8b 1b mov (%rbx),%rbx 401579: 48 8b 1b mov (%rbx),%rbx 40157c: 48 8b 1b mov (%rbx),%rbx
The assembly code generated by HUNDRED macro only has mov instruction of operating register rbx, which is advanced.
The delayed test results are as follows:
// L1 Buffer size: 1 KB, stride 64, time 0.001687 s, latency 1.61 ns Buffer size: 2 KB, stride 64, time 0.001684 s, latency 1.61 ns Buffer size: 4 KB, stride 64, time 0.001682 s, latency 1.60 ns Buffer size: 8 KB, stride 64, time 0.001693 s, latency 1.61 ns Buffer size: 16 KB, stride 64, time 0.001683 s, latency 1.61 ns Buffer size: 32 KB, stride 64, time 0.001783 s, latency 1.70 ns // L2 Buffer size: 64 KB, stride 64, time 0.005896 s, latency 5.62 ns Buffer size: 128 KB, stride 64, time 0.005915 s, latency 5.64 ns Buffer size: 256 KB, stride 64, time 0.005955 s, latency 5.68 ns Buffer size: 512 KB, stride 64, time 0.007856 s, latency 7.49 ns Buffer size: 1024 KB, stride 64, time 0.014929 s, latency 14.24 ns // L3 Buffer size: 2048 KB, stride 64, time 0.026970 s, latency 25.72 ns Buffer size: 4096 KB, stride 64, time 0.026968 s, latency 25.72 ns Buffer size: 8192 KB, stride 64, time 0.028823 s, latency 27.49 ns Buffer size: 16384 KB, stride 64, time 0.033325 s, latency 31.78 ns
L1 delay 1.61 ns, L2 delay 5.62 ns, finally, in line with expectations!
Write at the end
The idea and code of this article refer to lmbench[3], and the tool MEM lat of other students in the team. Finally, dig a hole for yourself. When randomizing the buffer pointer, the impact of hardware TLB miss is not considered. If readers are interested, they will supplement it when they are free in the future.
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.