The previous chapter introduced linux network namespace, and then discussed how to make an independent network namespace communicate with the host network. Here we need to use the linux virtual network device veth.
veth equipment
veth devices always appear in pairs. They are usually used to connect different network namespaces (hereinafter referred to as NS). One end is connected to the kernel protocol stack of NS1 and the other end is connected to the kernel protocol stack of NS2. The data sent by one end will be received by the other end.
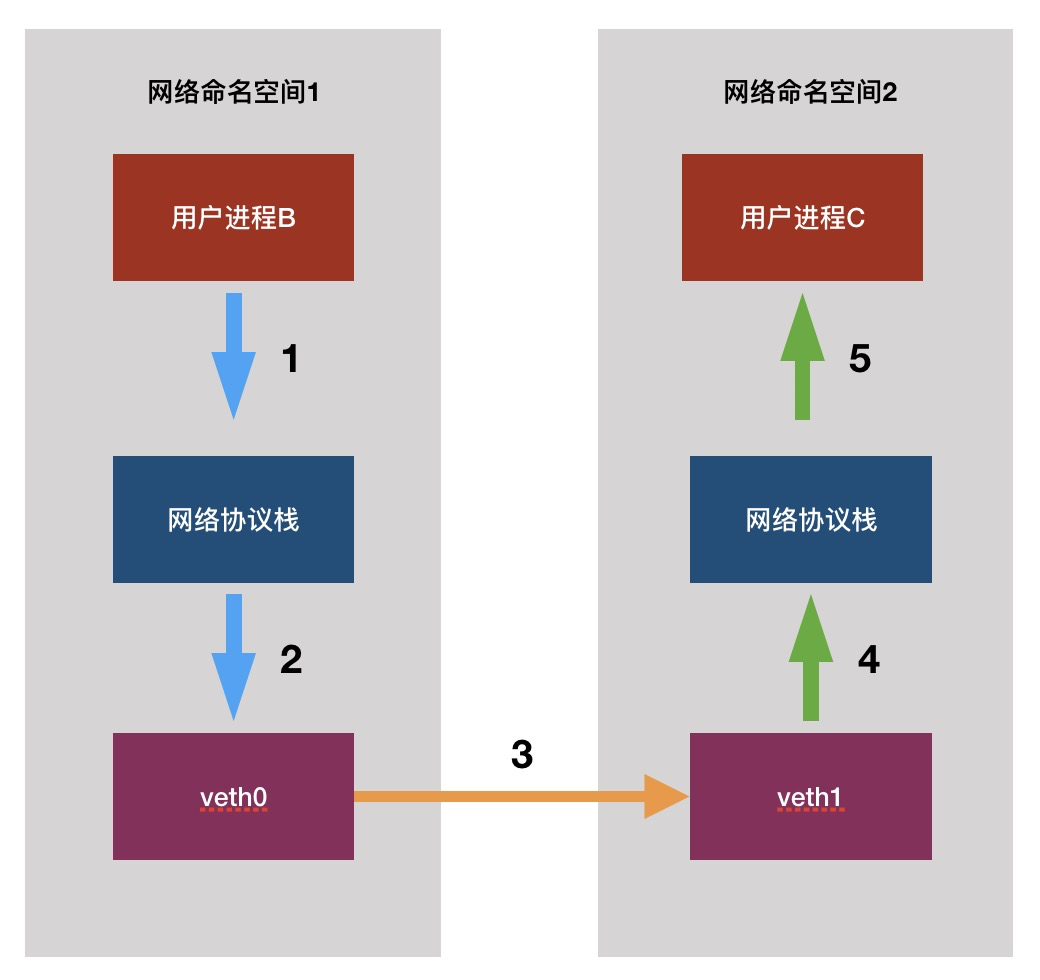
Next, let's try to create a new NS and connect it with the host NS
You can create a pair of veh devices with the following command
ip link add veth0 type veth peer name veth1
Then create a new NS
ip netns add ns1
Then turn one end of the newly created veh network card to NS1, which is like inserting one end into NS1 and the other end into the ns of the host
ip link set veth0 netns ns1
Set an IP for both ends. When setting veth0, use ip netns exec ns1, because veth0 is in ns1 at this time,
ip netns exec ns1 ip addr add 192.168.10.10/24 dev veth0 ip addr add 192.168.10.11/24 dev veth1
Start both network cards
ip netns exec ns1 ip link set veth0 up ip link set veth1 up
The status is as follows:

Then, you can PING each other
[root@worker2 ~]# ping 192.168.10.10 -c 5 PING 192.168.10.10 (192.168.10.10) 56(84) bytes of data. 64 bytes from 192.168.10.10: icmp_seq=1 ttl=64 time=0.060 ms 64 bytes from 192.168.10.10: icmp_seq=2 ttl=64 time=0.065 ms 64 bytes from 192.168.10.10: icmp_seq=3 ttl=64 time=0.090 ms 64 bytes from 192.168.10.10: icmp_seq=4 ttl=64 time=0.071 ms 64 bytes from 192.168.10.10: icmp_seq=5 ttl=64 time=0.064 ms [root@worker2 ~]# ip netns exec ns1 ping 192.168.10.11 -c 5 PING 192.168.10.11 (192.168.10.11) 56(84) bytes of data. 64 bytes from 192.168.10.11: icmp_seq=1 ttl=64 time=0.064 ms 64 bytes from 192.168.10.11: icmp_seq=2 ttl=64 time=0.052 ms 64 bytes from 192.168.10.11: icmp_seq=3 ttl=64 time=0.073 ms 64 bytes from 192.168.10.11: icmp_seq=4 ttl=64 time=0.059 ms 64 bytes from 192.168.10.11: icmp_seq=5 ttl=64 time=0.075 ms
At this time, it is impossible for us to ping the host in ns1, because there is only one route automatically generated by the system in ns1, and there is no default route, which will be discussed later.
If we go to ns1 and find that the PING local address is unavailable, it may be just because the lo network card is not started
ip netns exec ns1 ip link set lo up
Of course, this is rarely used in actual scenarios, because each new NS requires two IP addresses, which is a waste of IP and difficult to manage. When we set IP for veth1, the host will quietly generate a route for us:
192.168.10.0/24 dev veth5 proto kernel scope link src 192.168.10.11
This route indicates that it will usually go to 192.168 The addresses of the 10.0/24 network segment are given to veth1, which is obviously not the result we want, because other ns are not connected to veth1. Although we are only discussing VETH devices, our ultimate goal is to serve the container network. The pods of the same host are usually on the same cidr, The previous route is equivalent to leading the communication of all pods of the host to veth1, which is a problem.
Container connection host
In fact, we can not configure IP on veth1. The above example is just to let you know the effect of veth1 connection, because veth1 is connected to the kernel protocol stack of the host, and there are already many IPS on the host, just because there is no default route in ns1, The IP address of the host does not work (of course, if the network segment of your host is 192.168.10.0/24 network segment, it can work). Just add the default route. Let's demonstrate a more practical scenario.
Direct command, which is not explained sentence by sentence:
ip link add veth2 type veth peer name veth3 ip netns add ns2 ip link set veth2 netns ns2 ip netns exec ns2 ip addr add 192.168.10.12/24 dev veth2 ip netns exec ns2 ip link set veth2 up ip link set veth3 up
Open the arp proxy of veth3 on the host side, then add the default route to ns2, and also tell the host to go to veth3 to ns2:
echo 1 > /proc/sys/net/ipv4/conf/veth3/proxy_arp ip netns exec ns2 ip route add 0.0.0.0/0 via 169.2.2.2 dev veth2 onlink ip route add 192.168.10.12 dev veth3 scope link
Why is the default route of ns2 such a strange IP? It will be explained later
The whole state is as follows:
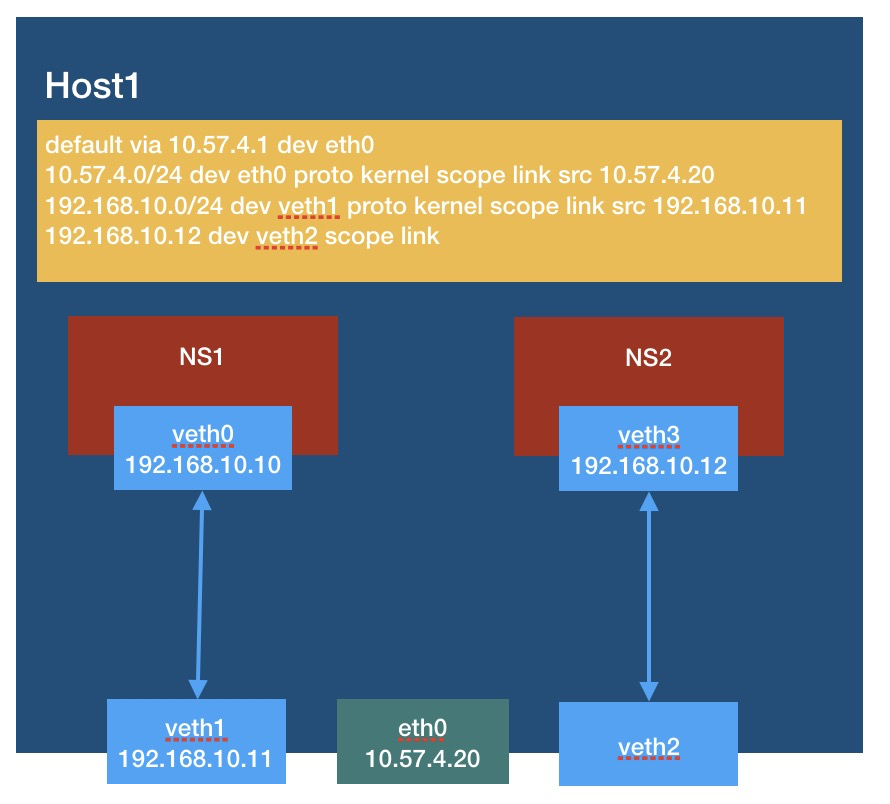
You can ping:
[root@worker2 ~]# ping 192.168.10.12 -c 5 PING 192.168.10.12 (192.168.10.12) 56(84) bytes of data. 64 bytes from 192.168.10.12: icmp_seq=1 ttl=64 time=0.188 ms 64 bytes from 192.168.10.12: icmp_seq=2 ttl=64 time=0.068 ms 64 bytes from 192.168.10.12: icmp_seq=3 ttl=64 time=0.077 ms 64 bytes from 192.168.10.12: icmp_seq=4 ttl=64 time=0.080 ms 64 bytes from 192.168.10.12: icmp_seq=5 ttl=64 time=0.079 ms --- 192.168.10.12 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4000ms rtt min/avg/max/mdev = 0.068/0.098/0.188/0.045 ms
Can ns1 and ns2 ping each other? OK, but first open the arp proxy of veth1 and configure ns1 with a default gateway
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp ip netns exec ns1 ip route add 0.0.0.0/0 via 192.168.10.11 dev veth0 onlink
If there is no accident, ping ns2 on ns1 should be connected. Of course, remember to turn on the routing and forwarding function of the host:
echo 1 > /proc/sys/net/ipv4/ip_forward
ns1 PING ns2:
[root@worker2 ~]# ip netns exec ns1 ping 192.168.10.12 -c 5 PING 192.168.10.12 (192.168.10.12) 56(84) bytes of data. 64 bytes from 192.168.10.12: icmp_seq=1 ttl=63 time=0.450 ms 64 bytes from 192.168.10.12: icmp_seq=2 ttl=63 time=0.105 ms 64 bytes from 192.168.10.12: icmp_seq=3 ttl=63 time=0.089 ms 64 bytes from 192.168.10.12: icmp_seq=4 ttl=63 time=0.094 ms 64 bytes from 192.168.10.12: icmp_seq=5 ttl=63 time=0.112 ms --- 192.168.10.12 ping statistics --- 5 packets transmitted, 5 received, 0% packet loss, time 4000ms rtt min/avg/max/mdev = 0.089/0.170/0.450/0.140 ms