Convolutional neural network series
preface
In this article, we use a custom implemented LeNet-5 neural network architecture to perform image classification on MNIST data sets.1, Integration
LeNet was founded in 1998 by Yann Lecun, Leon bottom, yoshua bengio, and Patrick Haffner My thesis Gradient-Based Learning Applied To Document Recognition introduce. In this article, we will introduce the LeNet-5 CNN architecture described in the original paper and use tensorflow2 0. Then, the MNIST data set is classified by using the constructed LeNet-5 CNN.
What will you learn from the article?
- Understand the construction of convolutional neural network
- Key definitions of common terms in deep learning and machine learning
- Understanding of LeNet-5
- Neural network implementation using TensorFlow and Keras
2, Convolutional neural network (CNN)
Convolutional neural network is a standard form of neural network architecture for solving image related tasks. The solutions of object detection, face detection, pose estimation and other tasks are all variants of CNN architecture.
Some features of CNN architecture make them better in many computer vision tasks:
- Local Receptive Fields
- Sub sampling
- Weight Sharing
3, LeNet-5
LeNet-5 CNN architecture has seven layers, including three convolution layers, two lower sampling layers and two full connection layers. As follows:
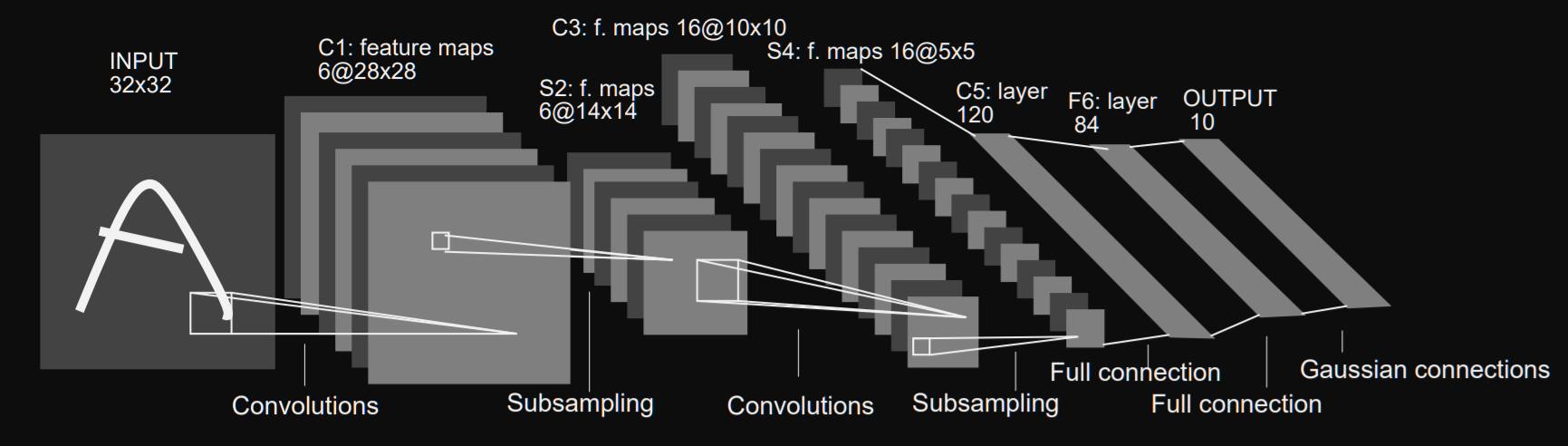
The first layer is the input layer, which has no learning ability. The input layer is constructed to accept 32x32 size input, which is the size of the image passed to the next layer. The size of MNIST dataset image is 28x28. In order to make the MNIST image dimension meet the requirements of the input layer, the 28x28 image is filled.
The used grayscale image pixel values are normalized from 0 to 255 to -0.1 to 1.175. This is done to ensure that the average value of this batch of images is 0 and the standard deviation is 1, which can reduce the training time. In the following image classification using LeNet-5 CNN, we will standardize the pixel value of the image to a value between 0 and 1.
LeNet-5 architecture uses two important types of layer construction: convolution layer and sub sampling layer.
- Convolutional layers
- Sub-sampling layers
The first convolution layer C1 generates 6 characteristic graphs as output, and the core size is 5x5. The kernel / filter is the name of the window containing the weight value used in the convolution of the weight value with the input value. 5x5 also represents the local receptive field size of each unit or neuron in the convolution layer. The size of the six feature maps generated by the first convolution layer is 28x28.
The subsampling layer "S2" follows the "C1" layer. The "S2" layer halves the feature map dimension it receives from the previous layer; this is commonly referred to as downsampling.
The "S2" layer also generates six feature maps, and each feature map corresponds to the feature map transmitted as input from the previous layer.
The following table summarizes the main features of each layer:

4, Implementation of LeNet-5 CNN Tensor Flow
- TensorFlow: an open source platform for implementing, training, and deploying machine learning models.
- Keras: an open source library for implementing neural network architecture running on CPU and GPU.
- Numpy: a library that uses n-dimensional arrays for numerical calculations.
Import these libraries first:
import tensorflow as tf from tensorflow import keras import numpy as np
Next, the MNIST dataset is loaded using the Keras library. We divide the dataset into test set, verification set and training set.
Normalize the image pixel range in the dataset from 0-255 to 0-1.
(train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data() train_x = train_x / 255.0 test_x = test_x / 255.0 train_x = tf.expand_dims(train_x, 3) test_x = tf.expand_dims(test_x, 3) val_x = train_x[:5000] val_y = train_y[:5000]
In the above code, the dimensions of training set and test set are extended. The reason is that in the training and evaluation stage, the network expects images to be presented in batches; Additional dimensions represent the number of images in a batch.
The following are the main parts based on LeNet-5 neural network:
Keras provides the tools needed to implement the classification model. Keras provides a Sequential API to overlay the layers of neural networks.
lenet_5_model = keras.models.Sequential([
keras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same'), #C1
keras.layers.AveragePooling2D(), #S2
keras.layers.Conv2D(16, kernel_size=5, strides=1, activation='tanh', padding='valid'), #C3
keras.layers.AveragePooling2D(), #S4
keras.layers.Flatten(), #Flatten
keras.layers.Dense(120, activation='tanh'), #C5
keras.layers.Dense(84, activation='tanh'), #F6
keras.layers.Dense(10, activation='softmax') #Output layer
])
First, TF keras. An instance of the sequential class constructor is assigned to the variable lenet_5_model.
In this class constructor, the layers in the model are defined.
Layer C1 is defined as follows:
keras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh', input_shape=train_x[0].shape, padding='same')
Use TF keras. layers. Conv2d class to construct the convolution layer in the network. The parameter activation is the activation function, which is a component of neural network. It introduces nonlinearity into the network. It makes the neural network have stronger representation ability. Other convolutions are similar.
After introducing the LeNet-5 architecture Original paper In, sub sampling layers are used. In the sub sampling layer, the average value of the pixel value falling in the 2x2 pooling window is taken, and then the value is multiplied by the coefficient value. Finally, add a deviation, which is completed before the activation function is applied.
However, in our implementation of LeNet-5 neural network, TF keras. layers. Averagepooling2d constructor. No parameters are passed to the constructor because some default values of the required parameters are initialized when the constructor is called. It should be clear that the role of the pooling layer in the network is to down sample the feature map when it moves in the network.
At the same time, there are two types of layers: Dense layer and flat layer.
The flatten layer uses the class constructor TF keras. layers. Flatten to create. The purpose of this layer is to convert its input into a one-dimensional array that can be input into subsequent dense layers.
The dense layer has a specified number of units or neurons in each layer, 84 in F6 and 10 in the output layer.
The last dense layer has 10 units, corresponding to the number of categories in the MNIST dataset. The activation function of the output layer is the softmax activation function.
Softmax: an activation function used to derive the probability distribution of a set of numbers in the input vector. The output of the softmax activation function is a vector, where its value set represents the probability of class / event occurrence. All the values in the vector add up to 1.
Then compile and build the model
lenet_5_model.compile(optimizer='adam', loss=keras.losses.sparse_categorical_crossentropy, metrics=['accuracy']) lenet_5_model.fit(train_x, train_y, epochs=5, validation_data=(val_x, val_y))
Keras provides a "compile" method through the model object we instantiated earlier. The compile function actually builds the model we implement behind the scenes and has some additional features, such as loss functions, optimizers, and metrics.
In order to train the network, we use the loss function to calculate the difference between the predicted value provided by the network and the actual value of the training data.
With the loss value of the optimization algorithm (Adam), the number of changes to the weight in the network is promoted. Supporting factors such as momentum and learning rate plan provide an ideal environment for network training convergence, so that the loss value is as close to zero as possible.
During the training, we will also validate our model after each period using the previously created valuation dataset partition
lenet_5_model.fit(train_x, train_y, epochs=5, validation_data=(val_x, val_y))
After training, you will notice that your model has achieved more than 90% verification accuracy. However, in order to more clearly verify the performance of the model on the unknown dataset, we will evaluate the training model on the partition of the previously created test dataset.
lenet_5_model.evaluate(test_x, test_y)

After model training, the accuracy of 98% can be achieved on the test data set. For a simple network, it has been a very good result.
appendix
The code is as follows:
import tensorflow as tf
from tensorflow import keras
import numpy as np
(train_x, train_y), (test_x, test_y) = keras.datasets.mnist.load_data()
train_x = train_x / 255.0
test_x = test_x / 255.0
train_x = tf.expand_dims(train_x, 3)
test_x = tf.expand_dims(test_x, 3)
val_x = train_x[:5000]
val_y = train_y[:5000]
lenet_5_model = keras.models.Sequential([
keras.layers.Conv2D(6, kernel_size=5, strides=1, activation='tanh',
input_shape=train_x[0].shape, padding='same'), # C1
keras.layers.AveragePooling2D(), # S2
keras.layers.Conv2D(16, kernel_size=5, strides=1, activation='tanh', padding='valid'), # C3
keras.layers.AveragePooling2D(), # S4
keras.layers.Flatten(), # Flatten
keras.layers.Dense(120, activation='tanh'), # C5
keras.layers.Dense(84, activation='tanh'), # F6
keras.layers.Dense(10, activation='softmax') # Output layer
])
lenet_5_model.compile(optimizer='adam', loss=keras.losses.sparse_categorical_crossentropy, metrics=['accuracy'])
lenet_5_model.fit(train_x, train_y, epochs=5, validation_data=(val_x, val_y))
lenet_5_model.evaluate(test_x, test_y)