Preface
Understanding HashMap and Concurrent HashMap focuses on:
(1) Understanding the design and implementation of HashMap's data structure
(2) Understanding the design and implementation of Concurrent HashMap's concurrent security on the basis of (1)
The previous article has introduced the underlying implementation of Map structure. Here we focus on its expansion method. Here we analyze the HashMap + Concurrent HashMap of JDK7 and JDK8 versions respectively:
HashMap Expansion of JDK7
This version of HashMap data structure is still the way of array + linked list. The expansion method is as follows:
void transfer(Entry[] newTable) {
Entry[] src = table; //src refers to the old Entry array
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //Traversing through old Entry arrays
Entry<K, V> e = src[j]; //Get each element of the old Entry array
if (e != null) {
src[j] = null;//Release the object reference of the old Entry array (after the for loop, the old Entry array no longer references any objects)
do {
Entry<K, V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!! Recalculate the position of each element in the array
e.next = newTable[i]; //Labelled [1]
newTable[i] = e; //Place elements on arrays
e = next; //Access the elements on the next Entry chain
} while (e != null);
}
}
}
The above code is not difficult to understand. For scaling operations, the underlying implementation needs to generate an array, and then copy every Node list in the old array into the new array. This method can be executed in a single thread, but it has a big problem under multi-threading. The main problem is the migration of data based on header interpolation. It causes the inversion of the linked list, thus triggering the closed chain of the linked list, resulting in the program dead cycle and eating full CPU. It is said that some people have mentioned bug s to the original SUN company, but Sun company believes that this is due to improper use by developers, because this class is not thread-safe, you still use it under multi-threading. Okay now, can I blame the problem? Think about it carefully. It makes sense.
Concurrent HashMap Expansion of JDK7
HashMap is thread insecure. Let's take a look at thread-safe Concurrent HashMap. When JDK7 is used, this security strategy adopts the mechanism of sectional locking. Concurrent HashMap maintains a Segment array. Segment inherits the re-entry lock ReentrantLock and maintains a HashEntry < K, V >[] table array in this class. In the write operation put, remove, expand Segments can be locked, so different Segments can be concurrent, so the thread security problem is solved, and the concurrent efficiency is also improved by using segmented lock. 
Look at the source code for its expansion:
// The node on the method parameter is the data that needs to be added to the new array after this expansion.
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 2 times
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
// Create a new array
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
// If the new mask is expanded from 16 to 32, then the sizeMask is 31, corresponding to the binary `000... 00011111'.
int sizeMask = newCapacity - 1;
// Traversing through the original array, the old routine, splitting the list at the position I of the original array into two positions I and i+oldCap of the new array
for (int i = 0; i < oldCapacity ; i++) {
// e is the first element of the list
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// Computing should be placed in a new array.
// Assuming that the length of the original array is 16 and e is at oldTable[3], idx may only be 3 or 3 + 16 = 19
int idx = e.hash & sizeMask;
if (next == null) // There is only one element in this location, which is easier to do.
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// e is the list head
HashEntry<K,V> lastRun = e;
// idx is the new location of the head node e of the current linked list
int lastIdx = idx;
// The for loop below finds a lastRun node, after which all the elements are to be put together.
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// Put the list of lastRun and all subsequent nodes in lastIdx
newTable[lastIdx] = lastRun;
// The following operation deals with the nodes before lastRun.
// These nodes may be assigned to another list or to the list above.
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// Place the new node at the head of one of the two lists just created in the new array
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
Notice that the code inside is locked, so it's safe inside. Let's look at the concrete implementation: first doubling the length of the array, then traversing the old table array, migrating every element of the array, that is, Node linked list, into the new array, and finally replacing the reference of the new array directly after the migration. In addition, there is a small detail optimization here. Two for loops are used to migrate the linked list. The first for is to determine whether there are elements with the same migration location and whether they are adjacent. According to HashMap's design strategy, the size of the table must be the n-th power of 2. We know that the location of each element in the expanded list is either unchanged or the original ta. For example, if there are three elements (3, 5, 7) to be put into the map, the table's capacity is 2. Simply assume that the location of the element is equal to the value% 2 of the element, the following structure can be obtained:
[0]=null [1]=3->5->7
Now the size of the table is expanded to 4, and the distribution is as follows:
[0]=null [1]=5->7 [2]=null [3]=3
Because expansion must be the n-th power of 2, HashMap directly takes the hashCode of key when put ting and get ting elements, and then directly uses the bitwise operation after re-equalization to achieve the modular effect. This is not to say in detail. The purpose of the above ex amp le is to illustrate the data distribution strategy after expansion, either in situ or in the old table position. Here it is 1. Plus the old table capacity is 2, so it's 3. Based on this feature, the first for loop is optimized as follows. Suppose we now use 0 to represent the in-situ position and 1 to represent the migration to index+oldCap to represent the element:
[0]=null [1]=0->1->1->0->0->0->0
The first for loop records lastRun, for example, to migrate data from [1]. After this loop, the location of lastRun records the location of the third 0. Because the latter data are all 0, which means they are migrating to the same location in the new array, they can insert the intermediate node directly into the new array location, but the attached elements are not. Need to move.
Then, in the second loop, it starts traversing from the position of the first 0 to the position of the third element, and only processes the previous data. In this loop, different chain lists are added according to the location 0 and 1. The latter data has been optimized and migrated, but in the worst case, the latter one may not be optimized, such as the following structure:
[0]=null [1]=1->1->0->0->0->0->1->0
In this case, the first for loop doesn't work much. It needs to traverse from the beginning to the end through the second for loop and distribute migration by 0 and 1. In this case, it uses header interpolation to migrate. The newly migrated data is added to the head of the list, but it is thread-safe, so there will be no loop list, leading to the problem of dead loop. Once the migration is complete, add the latest elements directly, and finally replace the old table with the new one.
JDK8 HashMap Expansion
In JDK8, the underlying data structure of HashMap has changed into the structure of array+linked list+red-black tree. Because the query efficiency of linked list is O(n) in the case of severe hash conflict, JDK8 has optimized the number of linked lists larger than 8, which will be directly converted to the structure of red-black tree as space for time, so the query efficiency becomes O(logN), as shown in the figure. Next:
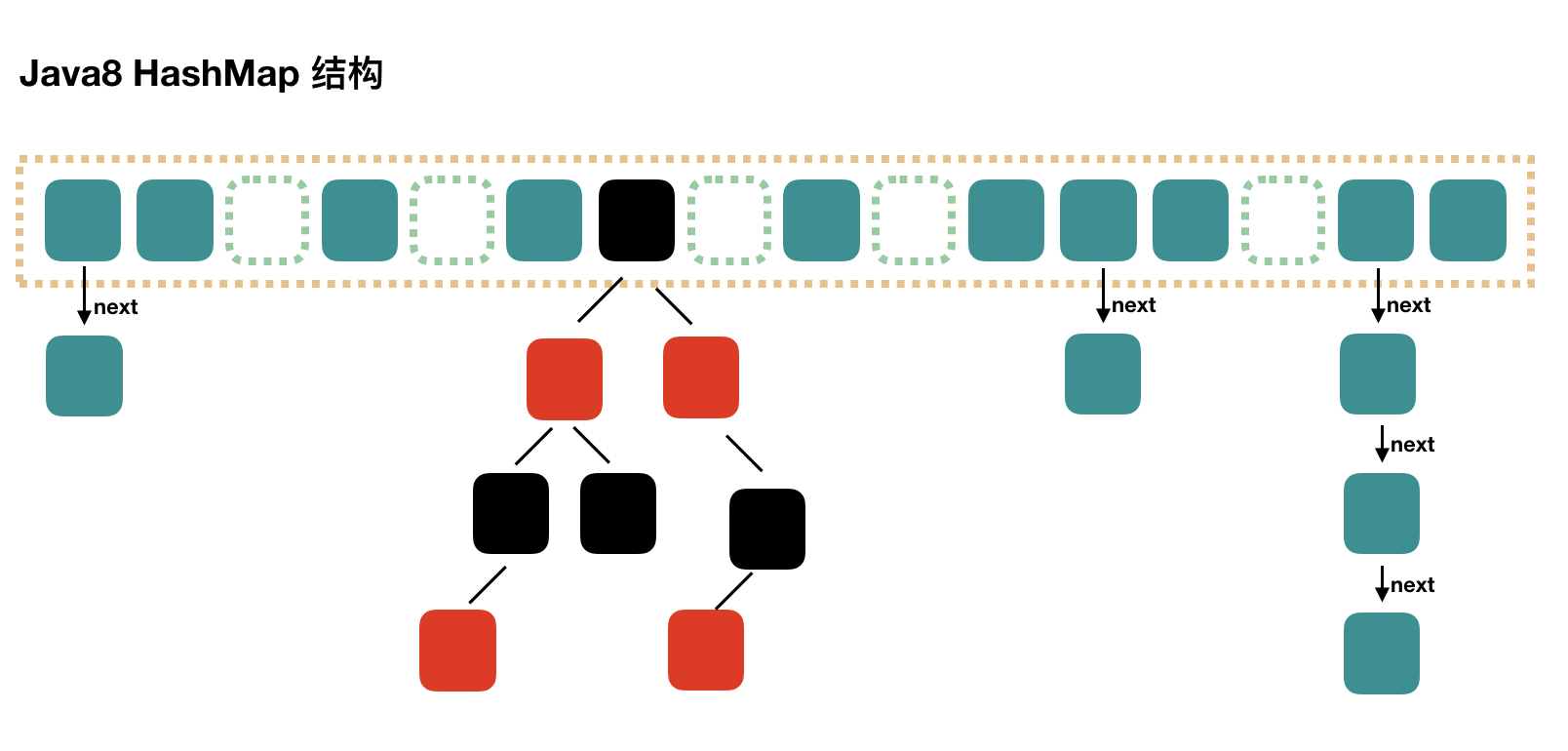
Let's look at its expansion code:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
//Areas of Focus
// preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
In JDK8, the addition of red-black tree to the simple HashMap data structure is a big optimization. In addition, according to the above migration and expansion strategy, we find that HashMap in JDK8 does not use header interpolation to transfer linked list data, but retains the sequential position of elements. The new code uses:
//In the order of the original list, the elements (low = 0) with the same location are filtered out and put together.
Node<K,V> loHead = null, loTail = null;
//In the order of the original list, the elements (high = 0) that have been filtered out and expanded and changed to (index+oldCap) are put together.
Node<K,V> hiHead = null, hiTail = null;
After classifying the elements to be migrated, they are finally placed in the corresponding positions of the new array:
//Location invariant
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//Location migration (index+oldCap)
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
JDK7 first determines whether the number of storage elements of table exceeds the current threshold=table.length*loadFactor (default 0.75). If it exceeds, it expands first. In JDK8, it inserts data first. After insertion, it determines whether the next + + size will exceed the current threshold. If it exceeds, it expands.
Concurrent HashMap Expansion of JDK8
JDK8 completely abandoned the mechanism of JDK7 segmented lock. The new version mainly uses CAS spin assignment of Unsafe class + synchronized synchronization + LockSupport blocking to achieve efficient concurrency, and the code readability is slightly poor.
The biggest difference between JDK8 of Concurrent HashMap and JDK7 is that the lock granularity of JDK8 is finer. Ideally, the size of talbe array elements is the maximum number of concurrent elements it supports. The maximum number of concurrent elements in JDK7 is the number of Segments. The default value is 16. Once created, it can be changed by the constructor. This value is concurrent granularity. The advantage of this design is that the expansion of the array will not affect other segments. It simplifies the concurrent design. The disadvantage is that the concurrent granularity is slightly coarse. Therefore, in JDK8, the segmented lock is removed and the level of the lock is controlled at a finer level of table elements. That is to say, just locking the head node of the linked list will not affect the reading and writing of other table elements. The advantage is that the concurrent granularity is finer and the impact is smaller, so the concurrent efficiency is better. But the disadvantage is that when concurrent expansion is completed, because the tables are the same, unlike JDK7 segment control, all the reading and writing needs to wait after expansion. Operations can only be carried out, so the efficiency of expansion has become a bottleneck of the whole concurrency. Fortunately, Doug lea optimizes the expansion. Originally, when one thread expands, if the data of other threads is affected, the reading and writing operations of other threads should be blocked. But Douglea says that you are idle, so you should participate in the expansion task together. Much power, do what you should do, don't waste time, so in the source code of JDK8 introduced a ForwardingNode class, when a thread initiates expansion, it will change the value of sizeCtl, which means as follows:
sizeCtl: Default is 0, which is used to control the initialization and expansion of table s. The specific application will be reflected in the future. - 1 represents that the table is initializing - N indicates that N-1 threads are expanding The rest: 1. If the table is not initialized, it indicates the size of the table to be initialized. 2. If the table initialization is completed, the capacity of the table is 0.75 times the size of the table by default.
This value will be judged when expanding. If it exceeds the threshold value, it will be expanded. First, the number of times i need to be traversed is obtained according to the operation. Then, the element F of i position is obtained by tabAt method, and a forwardNode instance fwd is initialized. If f = null, fwd is placed in the i position of table. Otherwise, the data of the specified task range of the current old table array is migrated by header interpolation. Go to the new array and assign fwd to the old table in situ. After traversing all the nodes, the replication is completed, pointing the table to nextTable, and updating sizeCtl to 0.75 times the size of the new array. During this period, if other threads have read and write operations, it will determine whether the head node is a forward Node node, and if so, it will help to expand.
The expansion source code is as follows:
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
How to read and write when expanding capacity
(1) For get read operation, if the current node has data and the migration has not been completed, it will not affect the read at this time, and can proceed normally.
If the current list has been migrated, the header node will be set to the fwd node, and the get thread will help expand.
(2) For put/remove write operation, if the current linked list has been migrated, the header node will be set as fwd node, and the write thread will help to expand. If the expansion is not completed, the header node of the current linked list will be locked, so the write thread will be blocked until the expansion is completed.
Weak consistency for size and iterator
volatile modified array references are strongly visible, but their elements are not necessarily, so this leads to the inaccuracy of size's sumCount-based approach.
Similarly, Iteritor's iterator does not accurately reflect the latest reality.
summary
This paper mainly introduces the expansion strategy of HashMap+Concurrent HashMap. The principle of expansion is to generate an array larger than 1 times the original size, then copy the old array data into the new array. In the case of multi-threading, if we pay attention to thread security, we should also pay attention to its efficiency, which is the best of the concurrent container class. Place.