[overview]
This is the first article in the hudi series, which first deepens the understanding of the concept from the core concept and the stored file format, and then gradually shares the use (spark/flink into hudi, hudi synchronous hive, etc.) and principles (compression mechanism, index, clustering, etc.)
[what is a data Lake]
In short, data Lake technology is a data organization format between the computing engine and the underlying storage format. It is used to define the organization mode of data and metadata, and realize the following functions:
Support transactions (ACID)
Support flow batch integration
Support schema evolution and schema termination
Support a variety of underlying data storage HDFS, OSS, S3
In terms of implementation, based on the distributed file system, it is provided for external use in the way of traditional relational database.
Open source data Lake implementations include Hudi, IceBerg and Delta.
[hudi introduction]
Apache hudi represents Hadoop upserts deletes incremental. It can make the HDFS data set support changes within the minute delay, and also support the incremental processing of this data set by the downstream system.
hudi dataset is compatible with the current hadoop ecosystem through customized InputFormat, including Hive, Presto, Trino, Spark and Flink, so that end users can connect seamlessly.
Hudi maintains a timeline (which is the core of Hudi) and carries a timestamp every time an operation is performed (such as write, delete, compression, etc.). Through the timeline, you can query only the data successfully submitted after a certain time point, or only the data before a certain time point. This avoids scanning a larger time range and consumes only changed files very efficiently.
The above is some theoretical introduction. It is simple to use. There are corresponding examples on the official website, so I won't be wordy here. Let's introduce some core concepts of hudi, the persistent file and file format of hudi.
[related concepts]
1. Table type
There are two types of tables in hudi
MOR(Merge on Read)
A table that is merged on read. Generally speaking, when writing, its data is written to the line storage file in the form of log, and then the line storage file is transformed into column storage file by compression. When reading, you may need to merge the data stored in the log file and the data stored in the column file to get the desired query results.
COW(Copy on Write)
A table that is copied and merged at the time of writing. When writing each time, the data is merged and stored in the column storage format, that is, there is no incremental log file.
Some comparisons between the two
| balance |
COW |
MOR |
| Data delay |
Higher |
Lower |
| Update cost (I/O) |
Higher |
Lower |
| parquet file size |
Smaller |
Bigger |
| Write amplification |
Higher |
Lower (depending on compression strategy) |
2. Timeline
hudi maintains the timeline of all operations on the table at different time points, which helps to provide an immediate view of the table and effectively provide sequential retrieval of data.
instant consists of the following components:
instant action: the operation type (action) of the dataset (table).
instant time: usually a timestamp, which monotonically increases in the order of operation start time.
State: current state
Key operation types include:
commit
Atomic writes a batch of data into a data set (table)
cleans
Clear old version files that are no longer needed in the dataset (table)
delta_commit
Incremental commit means that a batch of atomic records are written to MOR type tables, and some / all of the data may only be written to the incremental log file
compaction
Generally speaking, it is to move and update the line based log file to the column file.
rollback
Indicates the rollback after unsuccessful commit or incremental commit. At this time, any partition file generated during write will be deleted.
savepoint
Identify some filegroups as saved so that they are not deleted during cleanup. In the scenario of disaster recovery or data recovery, it is helpful to recover to a certain point on the timeline.
Any given instant can only be in one of the following states:
REQUESTED: indicates that an action has been scheduled but has not yet been executed
INFLIGHT: indicates that an action is being performed
COMPLETED: indicates when the last action on the axis has been COMPLETED
The status is converted by requested - > inflight - > complete.
3. View
hudi supports three types of Views:
Read Optimized Queries
This view only exposes the basic / column files in the latest file slice to the query, and guarantees the same columnar query performance as the non hudi columnar dataset. Simply put, for the MOR table, only the committed or compressed columnar storage files are read, and the incremental committed log files are not read.
Incremental Queries
The query of this view can only see the new data written to the dataset after submission / compression. This view effectively provides a change flow to support incremental data.
Live view (Snapshot Queries)
Queries on this view will an incremental commit to the latest snapshot of the dataset in the operation. This view provides near real-time data sets by dynamically merging the latest basic files.
The relationship between view type and table is:
| COW | MOR |
|
| Real time view |
Y |
Y |
| Incremental view |
Y |
Y |
| Read optimization view |
N |
Y |
[persistent file]
If the above concepts are still somewhat abstract, let's take a look at how the data written to hudi is stored on hdfs, and then understand the concepts mentioned above.
According to the example of the official website, the data written in the table and the files stored on hdfs are roughly as follows:
[root@localhost ~] hdfs dfs -ls -R /user/hncscwc/hudiedemo
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap/.fileids
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.aux/.bootstrap/.partitions
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/.temp
-rw-r--r-- 3 root supergroup 2017 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit
-rw-r--r-- 3 root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit.inflight
-rw-r--r-- 3 root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/20211130143947.deltacommit.requested
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/archived
-rw-r--r-- 3 root supergroup 388 2021-11-30 14:39 /user/hncscwc/hudidemo/.hoodie/hoodie.properties
drwxr-xr-x - root supergroup 0 2021-11-30 14:39 /user/hncscwc/hudidemo/par1
-rw-r--r-- 3 root supergroup 960 2021-11-30 14:39 /user/hncscwc/hudidemo/par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0
-rw-r--r-- 3 root supergroup 93 2021-11-30 14:39 /user/hncscwc/hudidemo/par1/.hoodie_partition_metadata
Several points can be seen from the storage files of hdfs:
The data of the table is stored in the specified configuration directory (here, / user/hncscwc)
The data is roughly divided into multiple directories, including The metadata related information is stored in the hoodie directory, which is essentially the relevant data corresponding to the timeline. The directory named after the partition (par1 here) stores the specific data of the data table in the partition.
Let's have a look first Persistent files related to metadata in the hoodie directory include:
yyyyMMddHHmmss.deltacommit
Record the execution results of a transaction of MOR table, including which partitions and which data (log) files are operated by the transaction, the type of operation on (log) files (insert or update), the length written, the metadata information of the table, etc. The file contents are stored in json format.
Several important fields in the file are:
partitionToWrtieStats
Take the partition as the key and record the actual operation information of each partition, including the ID, path, number of records written / deleted / updated, and the actual byte length of the partition written in this transaction.
compacted
Mark whether this submission operation is triggered by compression operation
extraMetadata
The most important is the schema field, which records the schema information of the table.
In addition, it should be noted that yyyyMMddHHmmss in the file name is the time stamp of this transaction submission, and its suffix is deltacommit, and the content of the corresponding file is not empty, which means that the transaction has been completed, and the related files also have yyyyMMddHHmmss deltacommit. Inflight and yyyyMMddHHmmss deltacommit. requested. It just corresponds to the three states corresponding to instant mentioned in the previous concept. That is, the current state of an operation is represented by writing the contents to files with different suffixes.
A simple example is:
{
"partitionToWriteStats" : {
"par1" : [ {
"fileId" : "f9037b56-d84c-4b9a-87db-7cae41ab2505",
"path" : "par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0",
"prevCommit" : "20211130143947",
"numWrites" : 1,
"numDeletes" : 0,
"numUpdateWrites" : 0,
"numInserts" : 1,
"totalWriteBytes" : 960,
"totalWriteErrors" : 0,
"tempPath" : null,
"partitionPath" : "par1",
"totalLogRecords" : 0,
"totalLogFilesCompacted" : 0,
"totalLogSizeCompacted" : 0,
"totalUpdatedRecordsCompacted" : 0,
"totalLogBlocks" : 0,
"totalCorruptLogBlock" : 0,
"totalRollbackBlocks" : 0,
"fileSizeInBytes" : 960,
"minEventTime" : null,
"maxEventTime" : null,
"logVersion" : 1,
"logOffset" : 0,
"baseFile" : "",
"logFiles" : [ ".f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0" ]
} ]
},
"compacted" : false,
"extraMetadata" : {
"schema" : "{\"type\":\"record\",\"name\":\"record\",\"fields\":[{\"name\":\"uuid\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"name\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"age\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ts\",\"type\":[\"null\",{\"type\":\"long\",\"logicalType\":\"timestamp-millis\"}],\"default\":null},{\"name\":\"partition\",\"type\":[\"null\",\"string\"],\"default\":null}]}"
},
"operationType" : null,
"totalCreateTime" : 0,
"totalUpsertTime" : 6446,
"totalRecordsDeleted" : 0,
"totalLogRecordsCompacted" : 0,
"fileIdAndRelativePaths" : {
"f9037b56-d84c-4b9a-87db-7cae41ab2505" : "par1/.f9037b56-d84c-4b9a-87db-7cae41ab2505_20211130143947.log.1_2-4-0"
},
"writePartitionPaths" : [ "par1" ],
"totalScanTime" : 0,
"totalCompactedRecordsUpdated" : 0,
"totalLogFilesCompacted" : 0,
"totalLogFilesSize" : 0,
"minAndMaxEventTime" : {
"Optional.empty" : {
"val" : null,
"present" : false
}
}
}yyyyMMddHHmmss.commit
It is similar to deltacommit, but it is usually the execution result of a transaction in the COW table or the compressed execution result. However, the file content is basically the same as that of deltacommit, and the file content is also stored in json format.
hoodie.properties
Relevant attributes of the file record table, such as:
#Properties saved on Tue Nov 30 14:39:29 CST 2021
#Tue Nov 30 14:39:29 CST 2021
hoodie.compaction.payload.class=org.apache.hudi.common.model.OverwriteWithLatestAvroPayload
hoodie.table.precombine.field=ts
hoodie.table.name=t1
hoodie.archivelog.folder=archived
hoodie.table.type=MERGE_ON_READ
hoodie.table.version=2
hoodie.table.partition.fields=partition
hoodie.timeline.layout.version=1
hoodie.compaction.payload.class: the processing class of payload during data insertion / update
hoodie.table.precombine.field: the field (data) to be pre merged before writing
hoodie.table.name: the name of the table
hoodie.archivelog.folder: Archive path of the table
hoodie.table.type: type of table (MOR or COW)
hoodie.table.version: the version number of the table (2 by default)
hoodie.table.partition.fields: the partition field of the table. Each partition takes the value of the partition field as the corresponding directory name, and its data is stored in the directory of the partition
hoodie.timeline.layout.version: the version of the timeline layout (1 by default)
The above files should be the most common. In addition, you may also see the following files:
yyyyMMddHHmmss.compaction.requested/inflight
The specific contents of the compression operation, including the time stamp of the compression operation and the files under which partitions are compressed and merged.
avro tool is a tool that can convert avro files to json compressed files. For example:
{
"operations":{
"array":[
{
"baseInstantTime":{"string":"20220106084115"},
"deltaFilePaths":{
"array":[".97ae031c-189b-4ade-9044-781e840c7e01_20220106084115.log.1_2-4-0"]},
"dataFilePath":null,
"fileId":{"string":"97ae031c-189b-4ade-9044-781e840c7e01"},
"partitionPath":{"string":"par1"},
"metrics":{
"map":{
"TOTAL_LOG_FILES":1.0,
"TOTAL_IO_READ_MB":0.0,
"TOTAL_LOG_FILES_SIZE":3000.0,
"TOTAL_IO_WRITE_MB":120.0,
"TOTAL_IO_MB":120.0}
},
"bootstrapFilePath":null
}]},
"extraMetadata":null,
"version":{"int":2}
}yyyyMMddHHmmss.clean.requested/inflight
The contents of the clean-up operation, including the timestamp of the clean-up operation and the files under which partitions are cleaned.
Like the compressed file, the file content is also stored in the standard avro format, and can also be converted into json by tools.
yyyyMMddHHmmss.rollback.requested/inflight
The contents of the rollback operation are also stored in standard avro format, for example:
{
"startRollbackTime":"20220112151350",
"timeTakenInMillis":331,
"totalFilesDeleted":0,
"commitsRollback":["20220112151328"],
"partitionMetadata":{
"par1":{
"partitionPath":"par1",
"successDeleteFiles":[],
"failedDeleteFiles":[],
"rollbackLogFiles":{"map":{}},
"writtenLogFiles":{"map":{}}
}
},
"version":{"int":1},
"instantsRollback":[{"commitTime":"20220112151328","action":"deltacommit"}]
}Summary: each operation of the table is recorded in the file with timestamp and different suffix, and its operation is stored in different files according to the status. All these correspond to the implementation of the timeline.
Let's look at the persistent files in the table partition. There are mainly several types of files:
.hoodie_partition_metadata
Record the metadata information of the partition. When writing, write it first hoodie_ partition_ metadata_$ Partition ID, and then rename it. The contents of the document are as follows:
#partition metadata
#Mon Dec 13 09:13:56 2021
commitTime=20211213091354
partitionDepth=1
Where commitTime is the submission time corresponding to the write operation, and partitionDepth is the level depth of the root directory of the relative table (mentioned above / user/hncscwc/hudidemo). When querying incremental view and snapshot view, the path corresponding to the partition directory is usually passed directly. Therefore, you need to read the file from the partition path to get the level depth, and then locate the root directory of the table to get the metadata information of the table.
xx.log.xx
The log data of MOR table operation is similar to the binlog file of mysql.
There are two forms of file naming:
Without writeToken: file name is $FileID_$Instant.log.$Version
With writeToken: the file name is $FileID_$Instant.log.$Version_$WriteToken
among
$FileID is a 36 byte UUID, $Instant is the timestamp of the operation submission, $Version is the log Version information, which starts from 1 by default. When writing the same file, the Version number will increase.
$WriteToken also has a fixed format, which is $Partition_$StageID_$AttemptID.
Note: there will be a "." before the file, That is, it is stored in the way of hidden files. In addition, with token, multiple processes are allowed to write concurrently to prevent confusion caused by writing the same file.
The specific format of the file is: it is composed of one or more submitted records, and each record is data in line storage format similar to avro.
One record represents the write operation record of a transaction to the table (including insertion, deletion and update). Multiple transactions will append and write to the same file to reduce the problem of massive small files caused by unnecessary file creation.
The file format is shown in the following figure:
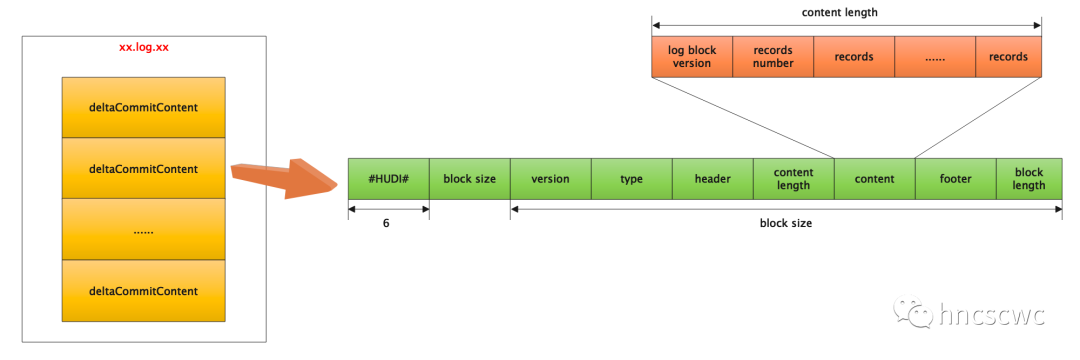
In addition, multiple write records in each transaction are finally saved in content. At the same time, the following five fields are added on the basis of the original data:
"_hoodie_commit_time"
"_hoodie_commit_seqno"
"_hoodie_record_key"
"_hoodie_partition_path"
"_hoodie_file_name"
The file example is as follows (it cannot be viewed directly, but the relevant contents printed after code analysis):
magic:#HUDI#
block size:1061
log format version:1
block type:AVRO_DATA_BLOCK
block header:{INSTANT_TIME=20211230090953, SCHEMA={"type":"record","name":"record","fields":[{"name":"_hoodie_commit_time","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_commit_seqno","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_record_key","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_partition_path","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_file_name","type":["null","string"],"doc":"","default":null},{"name":"uuid","type":["null","string"],"default":null},{"name":"name","type":["null","string"],"default":null},{"name":"age","type":["null","int"],"default":null},{"name":"ts","type":["null",{"type":"long","logicalType":"timestamp-millis"}],"default":null},{"name":"partition","type":["null","string"],"default":null}]}}
content length:235
content:
log block version:1
total records:2
content:
[
{
"_hoodie_commit_time": "20211230090953",
"_hoodie_commit_seqno": "20211230090953_1_1",
"_hoodie_record_key": "id1",
"_hoodie_partition_path": "par1",
"_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065",
"uuid": "id1",
"name": "Danny",
"age": 27,
"ts": 661000,
"partition": "par1"
},
{
"_hoodie_commit_time": "20211230090953",
"_hoodie_commit_seqno": "20211230090953_1_2",
"_hoodie_record_key": "id2",
"_hoodie_partition_path": "par1",
"_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065",
"uuid": "id2", "name":
"Stephen", "age": 33,
"ts": 2000,
"partition": "par1"
}
]
footer:{}
log block length:1067
magic:#HUDI#
block size:947
log format version:1
block type:AVRO_DATA_BLOCK
block header:{INSTANT_TIME=20211230092036, SCHEMA={"type":"record","name":"record","fields":[{"name":"_hoodie_commit_time","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_commit_seqno","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_record_key","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_partition_path","type":["null","string"],"doc":"","default":null},{"name":"_hoodie_file_name","type":["null","string"],"doc":"","default":null},{"name":"uuid","type":["null","string"],"default":null},{"name":"name","type":["null","string"],"default":null},{"name":"age","type":["null","int"],"default":null},{"name":"ts","type":["null",{"type":"long","logicalType":"timestamp-millis"}],"default":null},{"name":"partition","type":["null","string"],"default":null}]}}
content length:121
content:
log block version:1
total records:1
content:[{"_hoodie_commit_time": "20211230092036", "_hoodie_commit_seqno": "20211230092036_1_1", "_hoodie_record_key": "id4", "_hoodie_partition_path": "par1", "_hoodie_file_name": "c6b44d5e-749d-4053-94bf-92b39828e065", "uuid": "id4", "name": "Fabian", "age": 31, "ts": 4000, "partition": "par1"}]
footer:{}
log block length:953
xxx.parquet(orc/hfile)
Usually, the data in the log file mentioned above is compressed and written to the file after a transaction of the COW table is committed or after the compression operation. This is a standard parquet file format. Of course, orc and hfile formats are also supported.
Note: when spark operates on the MOR table type, the newly added data will be directly written to the parquet file, while the update operation will be recorded in the incremental log file (xx.log.xx), which is related to the index type used by spark/flink by default.
Well, this is the whole content of this article. After a brief review, we first introduce the core concepts of hudi, and then explain various types of persistent files and specific formats of hudi. Through persistent files, we can in turn deepen our understanding of the core concepts of hudi. In the next article, let's talk about other contents of hudi.
If you think this article is helpful to you, you are welcome to join me in wechat communication ~
This article is shared with WeChat official account hncscwc (gh_383bc7486c1a).
In case of infringement, please contact support@oschina.cn Delete.
Article participation“ OSC source creation plan ”, you who are reading are welcome to join us and share with us.