Data merging is a necessary step in data processing. As a sharp tool for data analysis, pandas provides four common data merging methods. Let's see how to use these methods!
1.concat()
concat() can be used for inline or inline splicing in the row / column direction between two or more dataframes. The union of rows (along the y-axis) is taken by default.
Mode of use
pd.concat(
objs: Union[Iterable[~FrameOrSeries], Mapping[Union[Hashable, NoneType], ~FrameOrSeries]],
axis=0,
join='outer',
ignore_index: bool = False,
keys=None,
levels=None,
names=None,
verify_integrity: bool = False,
sort: bool = False,
copy: bool = True,
)
main parameter
- objs: a sequence or Series, the mapping of DataFrame objects.
- Axis: connected axis, 0 ('index ', row), 1 ('columns', column). The default value is 0.
- join: connection method, inner (intersection) and outer (Union). The default is outer.
- ignore_index: whether to reset the index value of the series axis. If True, resets the index to 0,..., n - 1.
- keys: create a hierarchical index. It can be any value list or array, tuple array, array list (if levels is set to multi-level array)
- names: the name of the level in the generated hierarchical index.
Example
Create two dataframes.
df1 = pd.DataFrame(
{'char': ['a', 'b'],
'num': [1, 2]})
df2 = pd.DataFrame(
{'char': ['b', 'c'],
'num': [3, 4]})
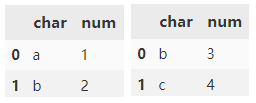
concat() will splice the row direction by default, and the connection mode is outer.
pd.concat([d1, d2])
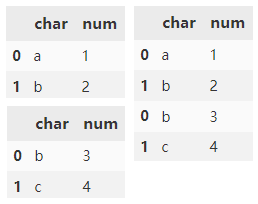
Clear existing indexes and reset indexes.
pd.concat(
[d1, d2],
ignore_index=True)
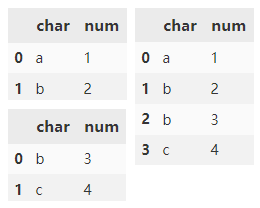
Add a hierarchical index to the outermost layer of data through the keys parameter.
pd.concat(
[d1, d2],
keys=['d1', 'd2'])
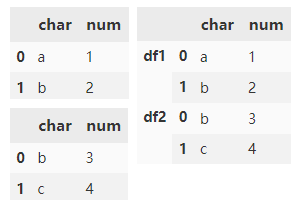
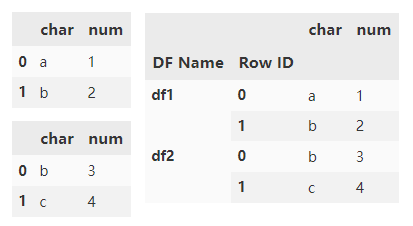
Specify the names parameter to mark the index key created.
pd.concat(
[d1, d1],
keys=['d1', 'd2'],
names=['DF Name', 'Row ID'])
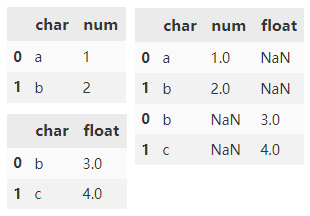
Combine two dataframes with overlapping columns and return everything. Fill NaN with columns outside the intersection.
df3 = pd.DataFrame(
{'char': ['b', 'c'],
'float': [3.0, 4.0]})
pd.concat([df1, df3])
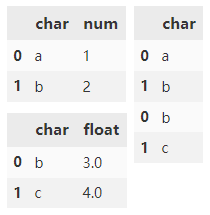
Combine two dataframes with overlapping columns and return only the contents of overlapping columns.
pd.concat(
[df1, df3],
join="inner")
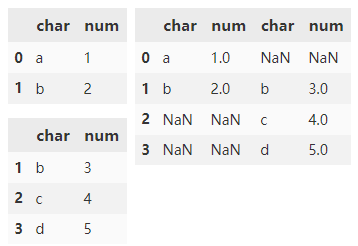
Specify axis=1 to combine DataFrame objects horizontally along the x axis.
df4 = pd.DataFrame(
{'char': ['b', 'c', 'd'],
'num': [3, 4, 5]},
index=range(1, 4))
pd.concat([df1, df4], axis=1)
2.merge()
merge() can only be used for inline or external merging in the column direction between two dataframes. By default, the columns are merged (along the x-axis) and the intersection is taken (that is, the intersection of two DataFrame column names is used as the connection key)
Mode of use
pd.merge(
left,
right,
how: str = 'inner',
on=None,
left_on=None,
right_on=None,
left_index: bool = False,
right_index: bool = False,
sort: bool = False,
suffixes=('_x', '_y'),
copy: bool = True,
indicator: bool = False,
validate=None,
)
parameter
- left: DataFrame
- right: DataFrame or Series with name
- how: {left ',' right ',' outer ',' inner '}. The default is' inner'. The connection method is
- on: the column index name used for connection must exist in the left and right dataframes at the same time. By default, the intersection of the column names of the two dataframes is used as the connection key.
- left_on: the column name used for the connection key in the DataFrame on the left. This parameter is very useful when the left and right column names are different but represent the same meaning;
- right_on: the column name used for the join key in the right DataFrame
- left_index: the default is False, and the row index in the left DataFrame is not used as the JOIN key (but it is best to use JOIN in this case)
- right_index: the default is False, and the row index in the right DataFrame is not used as the JOIN key (but it is best to use JOIN in this case)
- sort: False by default. sort the merged data. Setting False can improve performance
- suffixes: tuple composed of string values. It is used to specify the suffix name attached to the column name when the same column name exists in the left and right dataframes. The default is ('u x ',' u y ')
- copy: the default value is True. Data is always copied to the data structure. Setting it to False can improve performance
- indicator: displays the source of data in the consolidated data
- validate: {"one_to_one" or "1:1", "one_to_many" or "1:m", "many_to_one" or "m:1", "many_to_many" or "m:m"} if specified, check whether the merge is of the specified type.
Example
Create two dataframes.
df1 = pd.DataFrame(
{'name': ['A1', 'B1', 'C1'],
'grade': [60, 70, 80]})
df2 = pd.DataFrame(
{'name': ['B1', 'C1', 'D1'],
'grade': [70, 80, 100]})
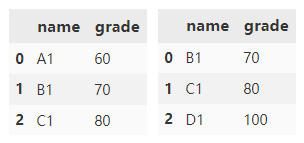
By default, merge() will merge according to the columns existing in two dataframes at the same time. The merging method adopts the method of taking the intersection.
df1.merge(df2)
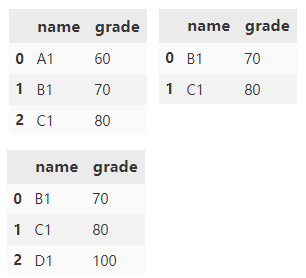
Specifies that the merge method is outer and the union set is taken.
df1.merge(df2, how='outer')
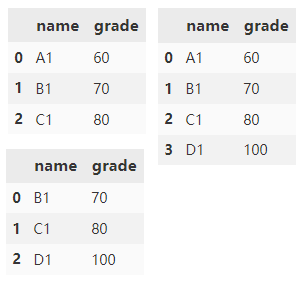
Next, create two more dataframes.
df1 = pd.DataFrame(
{'name1': ['A1', 'B1', 'B1', 'C1'],
'grade': [60, 70, 80, 90]})
df2 = pd.DataFrame(
{'name2': ['B1', 'C1', 'D1', 'E1'],
'grade': [70, 80, 90, 100]})
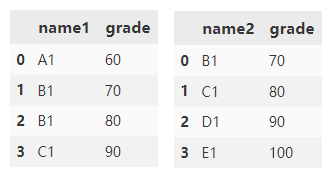
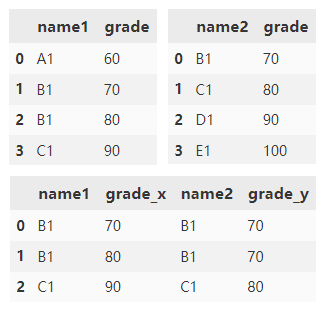
Merge df1 and df2 according to name1 and name2 columns. The default suffix is appended to the grade column_ x and_ y.
df1.merge(
df2,
left_on='name1',
right_on='name2')
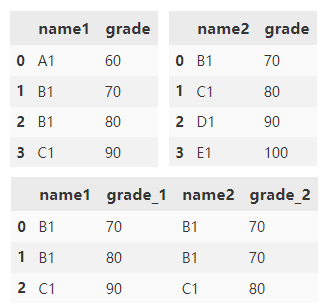
Merge df1 and df2 and append the specified left and right suffixes to the end of overlapping columns.
df1.merge(
df2,
left_on='name1',
right_on='name2',
suffixes=('_1', '_2'))
3.append()
append() can be used for splicing in the row direction (along the y axis) between two or more dataframes. The union set is taken by default.
Mode of use
df1.append(
other,
ignore_index=False,
verify_integrity=False,
sort=False)
parameter
- other: specify the data to add. DataFrame or Series objects, or a list of these objects
- ignore_index: whether to ignore the index. If True, the axis will be reset to 0, 1,..., n - 1. The default is False
- verify_integrity: if True, ValueError is raised when creating an index with duplicates. The default is False
- sort: if the columns of df1 and other are not aligned, the columns are sorted. The default is False.
Example
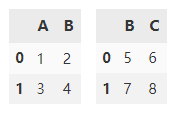
Create two dataframes.
df1 = pd.DataFrame(
[[1, 2], [3, 4]],
columns=list('AB'))
df2 = pd.DataFrame(
[[5, 6], [7, 8]],
columns=list('BC'))
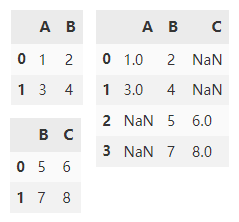
By default, append() will vertically splice two dataframes along the y axis, and fill NaN with columns outside the intersection of df1 and df2.
df1.append(df2)
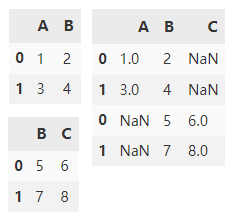
ignore_index is set to True to reset the index of the axis.
df1.append(df2, ignore_index=True)
4.join()
join() is used for splicing in the column direction (along the x axis) between two or more dataframes. The default is left splicing.
Mode of use
df1.join(
other,
on=None,
how='left',
lsuffix='',
rsuffix='',
sort=False)
- other: specify the data to add. DataFrame or Series objects, or a list of these objects
- on: connected columns. Index connection is used by default
- how: {left ',' right ',' outer ',' inner '}. The default is left. The connection method is
- lsuffix: empty string by default, indicating the suffix of duplicate columns in df1
- rsuffix: suffix of duplicate column in other
- Sort: sort the results on the join key in dictionary order. If False, the order of connection keys depends on the connection type (keyword).
Example
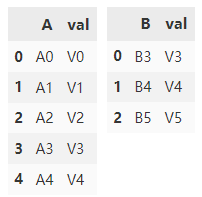
Create two dataframes.
df1 = pd.DataFrame(
{'A': ['A0', 'A1', 'A2', 'A3', 'A4'],
'val': ['V0', 'V1', 'V2', 'V3', 'V4']})
df2 = pd.DataFrame(
{'B': ['B3', 'B4', 'B5'],
'val': ['V3', 'V4', 'V5']})
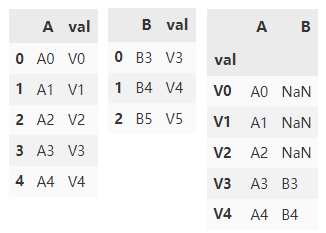
If we want to join using the val column, we need to set val to the index in df1 and df2.
df1.set_index('val').join(
df2.set_index('val'))
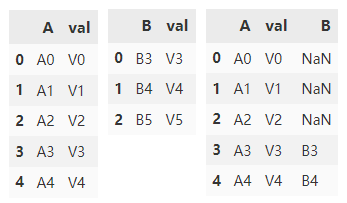
Another way to use the val column join is to specify the on parameter. df1.join can only use the index of df2, but can use any column in df1. Therefore, you can only turn the val column in df2 into an index, and specify the connection column of df1 as val through the on parameter.
df1.join(
df2.set_index('val'),
on='val')
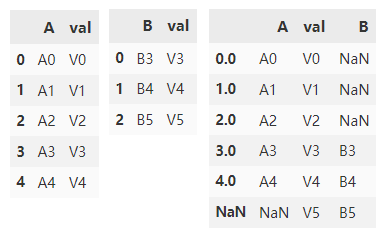
Connect df1 and df2 by external connection
df1.join(
df2.set_index('val'),
on='val',
how='outer')
Summary of four methods
- concat() connects Pandas objects along any axis and adds a hierarchical index on the concatenation axis
- join() is mainly used to splice columns based on row index
- merge() uses database style join merging, which is based on columns or indexes.
- Generally, append(), join() can be regarded as a simple version of concat() and merge(), with fewer parameters and strong ease of use.

For those who have just started Python or want to start python, you can contact the author through the small card below to communicate and learn together. They all come from novices. Sometimes a simple question card takes a long time, but they may suddenly realize it at the touch of others, and sincerely hope that everyone can make common progress. There are also nearly 1000 sets of resume templates and hundreds of e-books waiting for you to get them!